

2023年2月現在において、日本初となる『Screaming Frog SEO Spider』の日本語訳です。
インストール
ScreamingFrogSEOスパイダーは、お使いのOSに適したダウンロードボタンをクリックし、インストーラーを実行することでダウンロードできます。
SEOスパイダーは、Windows、Mac、Ubuntu Linuxでご利用いただけます。ただし、SEOスパイダーはWindows XPではご利用になれません。
SEOスパイダーは、適切なハードウェア、メモリ、ストレージがあれば、数百万のURLをクロールすることが可能です。クロールしたデータはRAMに、またはディスクにデータベースとして保存することができます。
20万URL以下のクロールであれば、一般的に8gbのRAMで十分です。
しかし、100万以上のURLをクロールするためには、SSDと16gbのRAM(またはそれ以上)が推奨されるハードウェアです。
SEOスパイダーを初めてご利用になる方は、スタートアップガイドをご覧ください。
Windowsへのインストール
この手順はWindows 10で書かれたものですが、直近全てのWindowsバージョンで有効です。
SEOスパイダーの最新版をダウンロードします。
ダウンロードしたファイルはバージョンによってScreamingFrogSEOSpider-16.7.exeまたは同様の名前になります。
ファイルは、ファイルエクスプローラーで簡単にアクセスできるダウンロードディレクトリにダウンロードされることがほとんどです。Windowsがセキュリティスキャンを実行する間、ダウンロードは100%完了したところで一時停止することがあります。
インストール
ダウンロードしたファイルは、SEOスパイダーをインストールするために実行する必要がある実行ファイルです。ファイルエクスプローラでダウンロードフォルダに移動し、ダウンロードしたファイルをダブルクリックすると、以下の画面が表示されます。

「はい」をクリックし、初期設定の場所以外にインストールしたい場合を除き、以下の画面で「インストール」を選択します。
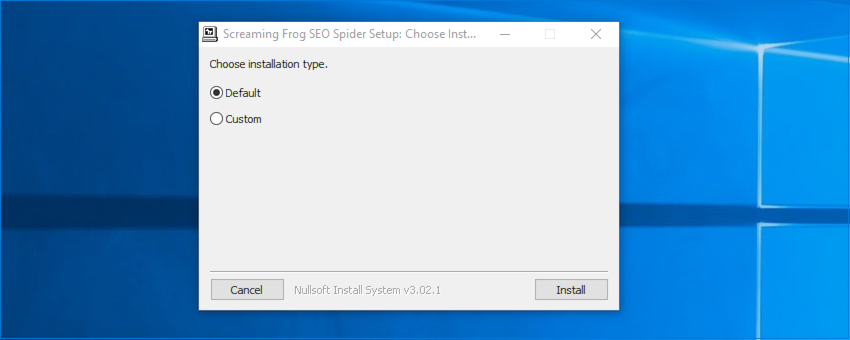
インストールが開始され、SEOスパイダーが必要とするファイルがコンピュータにコピーされます。完了すると、下記画面が表示されますので、「閉じる」をクリックしてください。
SEOスパイダーの実行
SEOスパイダーは、2つの方法で実行することができます。
GUI
画面左下のスタートアイコンをクリックし、「SEOスパイダー」と入力して検索し、クリックすると起動します。
コマンドライン
コマンドラインから実行したい場合は、ユーザーガイドをご覧ください。
トラブルシューティング
“Error opening file for writing”
コンピュータを再起動し、インストールを再試行してください。
macOSへのインストール
この手順は、macOS 10.14 Mojaveを使用して書かれていますが、直近全てのバージョンのmacOSで有効です。
SEOスパイダーの最新版をダウンロードします。
ダウンロードしたファイルは、バージョンやマシンのアーキテクチャに応じて、ScreamingFrogSEOSpider-17.0-aarch64.dmg、ScreamingFrogSEOSpider-17.0-x86_64.dmgなどの名前になります。
ダウンロードするバージョンがわからない場合は、FAQの「Macに必要なSEOスパイダーのバージョンを教えてください」をご覧ください。
ファイルは、Finderで簡単にアクセスできるDownloadsディレクトリにダウンロードされる可能性が高いです。
インストール
ダウンロードしたファイルは、Screaming Frog SEOスパイダーのアプリケーションを含むディスクイメージです。Finderのダウンロードフォルダに移動し、ダウンロードしたファイルをダブルクリックすると、以下の画面が表示されます。

左側のScreaming Frog SEOスパイダーアプリケーションアイコンをクリックし、右側のアプリケーションフォルダへドラッグします。これでScreaming Frog SEOスパイダーアプリケーションがアプリケーションフォルダにコピーされ、macOSのほとんどのアプリケーションのある場所に移動します。
ここで左上のxをクリックしてこのウィンドウを閉じます。
Finderに移動し、左側のデバイスセクションからScreamingFrogSEOSpiderを探し、その横にある取り出しアイコンをクリックします。

SEOスパイダーの実行
SEOスパイダーは、2つの方法で実行することができます。
GUI
Finderでアプリケーションフォルダに移動し、Screaming Frog SEOスパイダーのアイコンを探してダブルクリックすると起動します。
コマンドライン
コマンドラインから実行したい場合は、ユーザーガイドをご覧ください。
トラブルシューティング
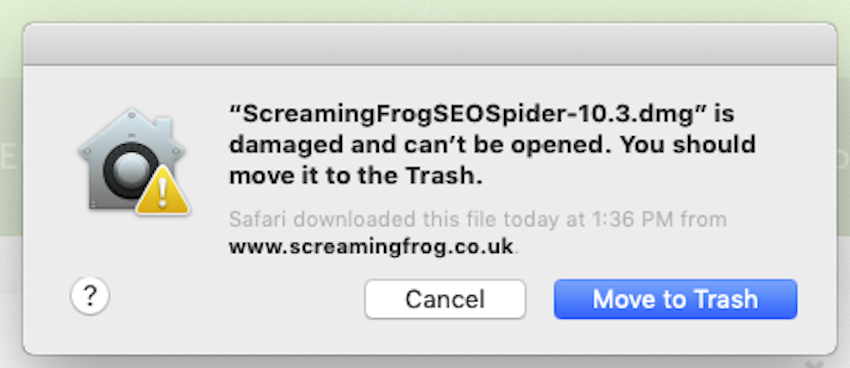
.dmgを開くときにこのようなメッセージが表示された場合は、Macを再起動してもう一度試してください。
Ubuntuへのインストール
この手順は、Ubuntu 18.04.1 にインストールするためのものです。
SEOスパイダーの最新版をダウンロードします。ダウンロードしたファイルはscreamfrogseospider_16.7_all.debのような名前で、ほとんどの場合、ホームディレクトリのダウンロードフォルダにあるはずです。
インストール
SEOスパイダーのインストール方法は2通りあります。
GUI
- .debファイルをダブルクリックします。
- インストール “を選んで、パスワードを入力してください。
- SEOスパイダーはttf-mscorefonts-installを実行する必要があるので、ポップアップが表示されたらこのライセンスを承諾してください。
- インストールが完了するのを待ちます。
コマンドライン
ターミナルを開き、以下のコマンドを入力します。
sudo apt-get install ~/Downloads/screamingfrogseospider_15.2_all.debパスワードを入力し、ttf-mscorefonts-installationsのインストールEULAに同意して続行するかどうか尋ねられたらYを入力する必要があります。
トラブルシューティング
E: Unable to locate package screamingfrogseospider_15.2_all.deb
例にあるように、インストールする .deb の絶対パスを入力しているかどうか確認してください。
Failed to fetch http://archive.ubuntu.com/ubuntu/pool/main/u/somepackage.deb 404 Not Found [IP: 91.189.88.149 80]
以下を実行して、もう一度試してください。
sudo apt-get updateSEOスパイダーの実行
SEOスパイダーのインストール方法に関係なく、2つの方法で実行することができます。
GUI
左下のアプリのアイコンをクリックし、「SEOスパイダー」と入力し、表示されたアプリのアイコンをクリックします。
コマンドライン
ターミナルで次のコマンドを入力します。
スクリミングフロッグスパイダー
その他のコマンドラインオプションについては、ユーザーガイドをご覧ください。
Fedoraでのインストール
この手順は、Fedora Linux 35にインストールするためのものです。
SEOスパイダーの最新版をダウンロードします。ダウンロードしたファイルはscreamfrogseospider-17.0-1.x86_64.rpmのような名前で、あなたのホームディレクトリのダウンロードフォルダにあることがほとんどでしょう。
インストール
ターミナルを開き、以下のコマンドを入力します。
sudo rpm -i ~/Downloads/screamingfrogseospider-17.0-1.x86_64.rpmSEOスパイダーの実行
SEOスパイダーをインストールすると、2つの方法で実行することができます。
GUI
左上のアクティビティーのアイコンをクリックし、「SEOスパイダー」と入力し、表示されたらアプリケーションのアイコンをクリックします。
コマンドライン
ターミナルで次のコマンドを入力します。
screamingfrogseospiderその他のコマンドラインオプションについては、ユーザーガイドをご覧ください。
クローリング
ScreamingFrogSEOスパイダーは無料でダウンロードでき、一度に500URLまでクロールして使用することができます。
年間149ポンドでライセンスを購入すると、500URLのクロール制限が解除されます。
また、ライセンスを取得することで、設定、クロールの保存と開放、およびJavaScriptレンダリング、カスタム検索、カスタム抽出、Google Analytics統合、Google Search Console統合、PageSpeed Insights統合、AMP検証、構造化データ検証、スケジュールなどの先進機能にアクセスすることができます。
無料と有料の機能比較は、価格ページでご確認してください。初めてご利用になる方は、SEOスパイダーのスタートガイドを読んでください。
Webサイト(サブドメイン)をクロールする
通常のクロールモードでは、SEOスパイダーは入力されたサブドメインをクロールし、遭遇した他のサブドメインは全て初期設定で外部リンクとして扱います(これらは「外部」タブに表示されます)。
例えば、上部の「Enter URL to spider(赤枠)」ボックスに https://www.screamingfrog.co.uk を入力し、「Start」をクリックすると、クロールされることになります。

有料版では、Webサイトのサブドメインが複数ある場合、全てのサブドメインをクロールするかどうかを選択するように設定を調整することができます。
ルート(例:https://screamingfrog.co.uk)からクロールを開始した場合、SEOスパイダーは初期設定で全てのサブドメインもクロールします。
SEOスパイダーの最も一般的な使い方は、
- リンク切れ
- リダイレクト
- サーバーエラー
など、Webサイトのエラーを見つけることです。
リンク切れの見つけ方については、404などのエラーのソースを表示する方法と、ソースデータをスプレッドシートに一括でエクスポートする方法について説明しています。
- サブフォルダをクロールするURL構造
- HTMLのみをクロールする(画像、CSS、JSなど)
- 除外機能
- カスタム robots.txt
- インクルード機能
などのSEOスパイダーの設定オプション、あるいはSEOスパイダーのモードを変更してクロールするURLのリストをアップロードするなど、クロールをより適切にコントロールすることができます。
サブフォルダをクロールする
SEOスパイダーは、初期設定でサブフォルダのパスから先にクロールします。サブフォルダをクロールするには、サブフォルダの完全なURLを入力するだけです。
例えば、/blog/であれば、
https://www.screamingfrog.co.uk/blog/これをSEOスパイダーに直接入力すると、/blog/のサブフォルダーに含まれる全てのURLをクロールしてくれます。
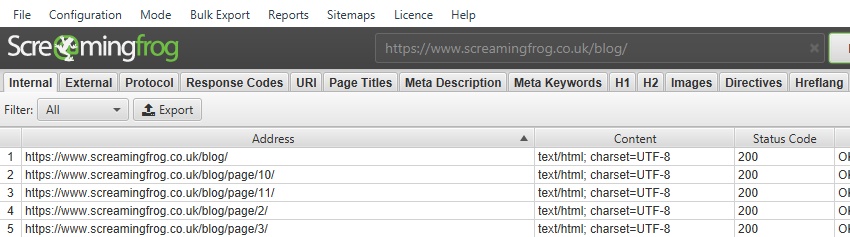
初期設定のままだと、場合によっては/blog/サブフォルダ内ではないURLもクロールされることがあります。
これは、初期設定項目のなかで「開始フォルダの外のリンクをチェックする」が含まれているからです。
この設定により、SEOスパイダーは/blog/ディレクトリ内を重点的にクロールしますが、このディレクトリ内からリンクされている場合は、指定したディレクトリ外のリンクもクロールします。
ただし、それ以上先にはクロールしません。これは、/blog/サブフォルダ内にありながら、URL構造に/blog/が含まれていないリンク切れを見つけたい場合に有効です。
/blog/のあるURLだけをクロールするには、この設定のチェックを外してください。
例えば、「/blog/」ではなく「/blog」のようにサブフォルダーの末尾にスラッシュがない場合、SEOスパイダーはそれをサブフォルダーとして認識せず、その中をクロールすることはありません。
また、トレイリングスラッシュのついたサブフォルダー(末尾に/がついているサブフォルダーのURL)が、トレイリングスラッシュのついていないサブフォルダー(末尾に/がついていないサブフォルダーのURL)にリダイレクトされる場合も同様です。
このサブフォルダをクロールするには、含む機能を使って、そのサブフォルダの正規表現(この例では.*blog.*)を入力する必要があります。
サブドメインやサブフォルダなど、より複雑な設定をしている場合は、両方を指定することができます。
https://de.example.com/uk/に
deサブドメイン
と
UKサブフォルダ
の両方がある場合
サブドメインとサブフォルダーのクロールについては、ビデオガイドをご覧ください。
URLのリストをクローリングする
URLを入力して「Start」をクリックすることでWebサイトをクロールするだけでなく、リストモードに切り替えて、クロールする特定のURLのリストを貼り付けるか、アップロードすることもできます。

これは、URLやリダイレクトを監査する場合など、サイト移行に特に役立ちます。
最適なアプローチについては、「サイト移行におけるリダイレクトの監査方法」のガイドを確認してください。
リストモードのデータをアップロードした順番でエクスポートしたい場合は、ユーザーインターフェースの上部にある「アップロード」と「開始」ボタンの隣に表示される「エクスポート」ボタンを使用します。
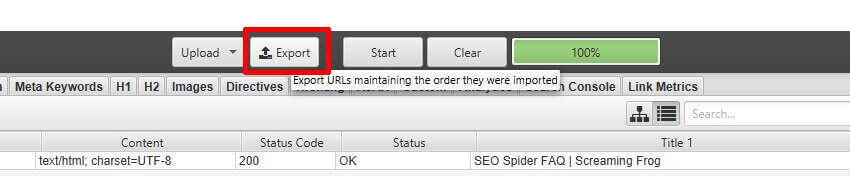
エクスポートされるデータは、同じ順番で、重複や修正されたものも含め、アップロード元のURLと全く同じものが全て含まれます。
大規模なWebサイトのクローリング
SEOスパイダーがクロールできるURLの数は、マシンで利用できるメモリの量と割り当ての有無、そして初期設定のメモリストレージでクロールするか、データベースストレージモードでクロールするかによって決まります。
特に大規模なクロールを行いたい場合は、データベース保存モードに切り替え、SEOスパイダーのRAMメモリ割り当てを増やすことをお勧めします。
データベース保存を選択すると、クロールデータはRAMだけでなく、ディスクに保存されます。
これにより、SEOスパイダーはより多くのURLをクロールすることができ、クロールデータは自動的に保存され、「File > Crawls(ファイル > クロール)」メニューによって、より速く開くことができます。
この設定は、「Configration > System > Storage Mode(設定 > システム > ストレージモード)」→「database storage(データベースストレージ)」を選択することで行えます。

SEOスパイダーは全てのデータをディスクに保存しますが、SEOスパイダーがより多くのURLをクロールできるように、RAMのメモリ割り当てを増やすことができます。
200万URLまでのクロールには、4GBに設定することをお勧めします。この設定は、「Configration > System > Memory Allocation(設定 > システム > メモリ割り当て)」で行うことができます。

もし「このクロールのためのメモリが不足しています」という警告が表示されたら、クロールを保存してデータベース保存モードに切り替えるか、メモリ保存モードでRAM割り当てを増やし、それからクロールを開いて再開してください。
大規模なクロールを行う場合は、大規模なWebサイトをクロールする方法について、ガイドをお読みください。
利用可能なオプションは以下の通りです。
- サブドメイン、または前述したサブフォルダによるクロール。
- 含む機能でクロールを絞り込んだり、除外設定やcustom robots.txt機能でクロールする必要のない領域を除外することが可能。
- クロールしたURLの総数、深さ、クエリ文字列パラメータの数で制限することを検討。
- SEOスパイダーの設定で、画像、CSS、JavaScript、SWF、外部リンクのチェックを外し、内部のHTMLのみをクロールすることを検討。
これらは全て、メモリを節約し、クロールを必要な重要な部分に集中させるのに役立つはずです。
クロールの保存、オープン、エクスポート、インポート
クロールを保存して、ライセンスを持っているSEOスパイダーで再び開くことができます。クロールの保存と再開は、SEOスパイダーの保存モードの設定によって少し異なります。
以下のビデオまたはガイドをご覧ください。
メモリ保存モードでの保存と開放
初期設定のメモリ保存モードでは、クロールはSEOスパイダー専用の.seospiderファイルタイプとして保存することが可能です。
SEOスパイダーを一時停止することでクロールを途中で保存したり、クロールの終了時に「File > Save(ファイル > 保存)」を選択することで保存できます。
クロールを開くには、該当する.seospiderファイルをダブルクリックするか、「File > Open(ファイル > 開く)」を選択してファイルに移動するか、「File > Open Recent(ファイル > 最近開いたファイル)」で最近のクロールを選択するだけです。クロールを一時停止している場合は、再開することができます。
クロールの保存とオープンには、クロールのサイズとデータ量によって、数分からもっと長い時間がかかることがあることに注意してください。
大規模なクロールを行う予定がある場合は、次のセクションで説明するように、クロールを開くのが大幅に速くなるデータベースストレージモードを検討することをお勧めします。
データベース保存モードでの保存と開放
データベース保存モードでは、クロール中に自動的にクロールがデータベースに 「保存」され、コミットされます。クロールを消去したり、新しいURLを入力したり、SEOスパイダーを終了させると、クロールは自動的に保存されます。
誤ってマシンの電源を切ったり、クラッシュや停電が発生しても、クロールは安全に保存されるはずです。
クロールは、メモリ保存モードを使用している他のユーザーとクロールを共有したい場合を除き、.seospiderファイルとして「保存」する必要はありません。
データベース保存モードでクロールを開くには、メインメニューの「File > Crawls(ファイル > クロール)」をクリックします。
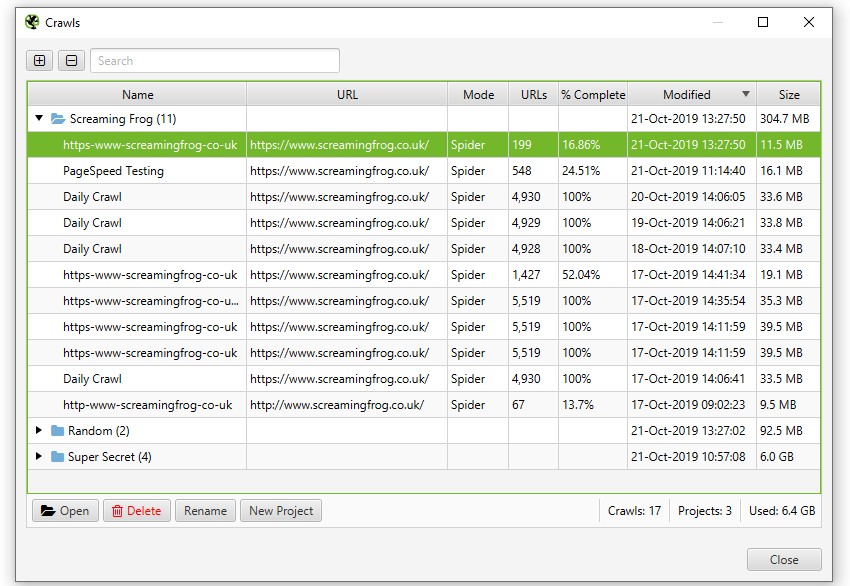
「(クロール)」ウィンドウには、自動的に保存されたクロールの概要が表示され、開く、名前の変更、プロジェクトフォルダーへの整理、複製、エクスポート、一括削除が可能です。
データベースから直接ストアドクロールを開く主な利点は、.seospider ファイルで読み込むよりもかなり速いということです。
「File > Export(ファイル > エクスポート)」で、他のユーザーが開くクロールをエクスポートすることができます。

データベース保存モードのクロールをエクスポートするには、「名前を付けて保存」ダイアログ画面と「名前を付けて保存タイプ」の2つのオプションがあります。

データベースファイル(.dbseospiderファイル)をエクスポートすることができ、データベースストレージのSEOスパイダーにインポートすることができます。
これは、より高速であるため、推奨される初期設定のオプションです。また、クロールを通常の.seospiderファイルとしてエクスポートすることもでき、メモリーストレージとデータベースストレージのどちらのモードを使用している場合でもインポートすることができます。
データベース保存モードでは、.seospiderファイルは変換されてデータベースにコミットされるため、.dbseospiderファイルを開くより時間がかかります。
しかし、いったんデータベースに格納されると、’File > Crawls’ メニューでアクセスできるようになり、より迅速に開くことができるようになります。
データベース保存モードで.dbseospiderファイルをインポートするには、「File > Import(ファイル > インポート)」をクリックします。メモリ保存モードでは、.dbseospiderファイルを開くことはできません。

データベース保存モードで.seospiderファイルをインポートするには、「File > Import(ファイル > インポート)」をクリックし、「File Type(ファイルタイプ)」を「Screaming Frog DB SEO Spider Crawl Data」から「Screaming Frog SEO Spider Crawl Data」に切り替えて該当ファイルをクリックしてください。

上記のように、.seospiderファイルは最初にインポートするのに時間がかかりますが、データベースにカバーされると「ファイル > クロール」メニューで利用できるようになります。
設定
有料版では、初期設定のクロール設定を保存したり、設定プロファイルを保存して、必要なときに読み込むことができます。
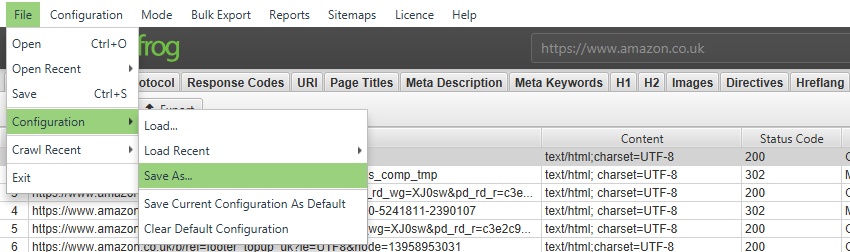
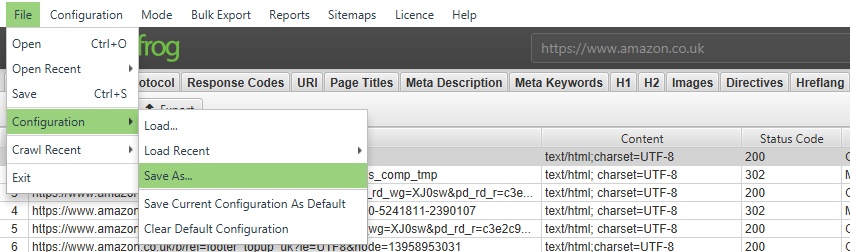
ご自身で設定した内容を、オリジナルの初期設定として保存するには、「File > Configuration > Save Current Configuration As Default」(ファイル > 設定 > 現在の設定を初期設定として保存)を選択します。
将来ロードできるように設定プロファイルを保存するには、「File > Save As(ファイル > 名前をつけて保存)」をクリックし、ファイル名を調整します(すぐに分かる内容が理想的です!)。
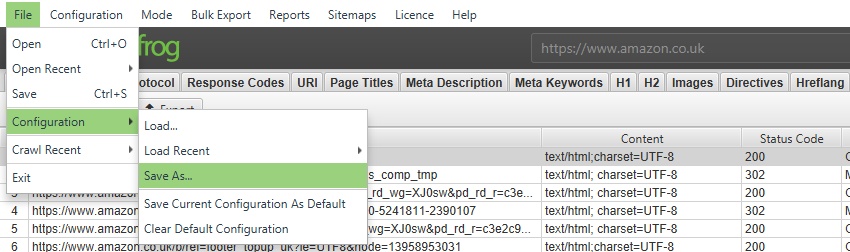
構成プロファイルを読み込むには、「File > Load(ファイル > ロード)」をクリックして構成プロファイルを選択するか、「‘File > Load Recent’」をクリックして最近のリストから選択します。
元のSEOスパイダーの初期設定に戻すには、「File > Configuration > Clear Default Configuration(ファイル > 設定 > 初期設定に戻す)」を選択します。
カスタムコンフィギュレーションに関するビデオガイドをご覧ください。
スケジューリング
SEO Spiderでは、クロールを自動的に実行するようにスケジュールを設定することができます。この機能は、アプリ内の「File > Scheduling(ファイル > スケジューリング)」で確認することができます。
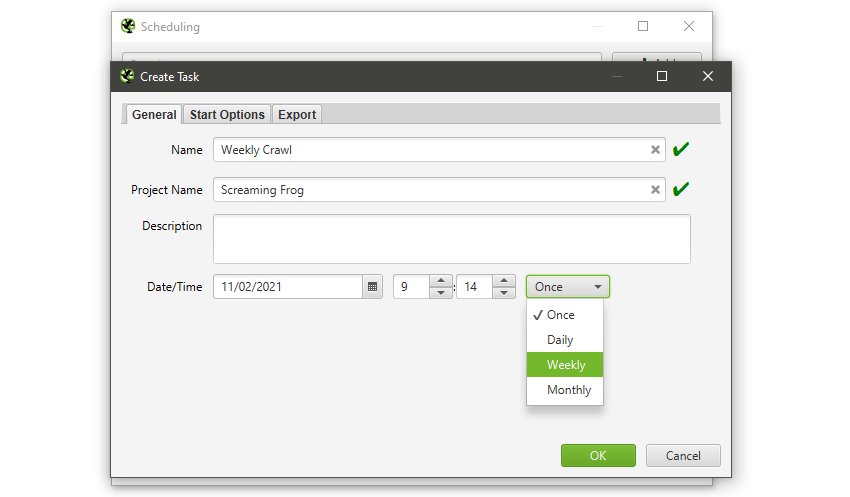
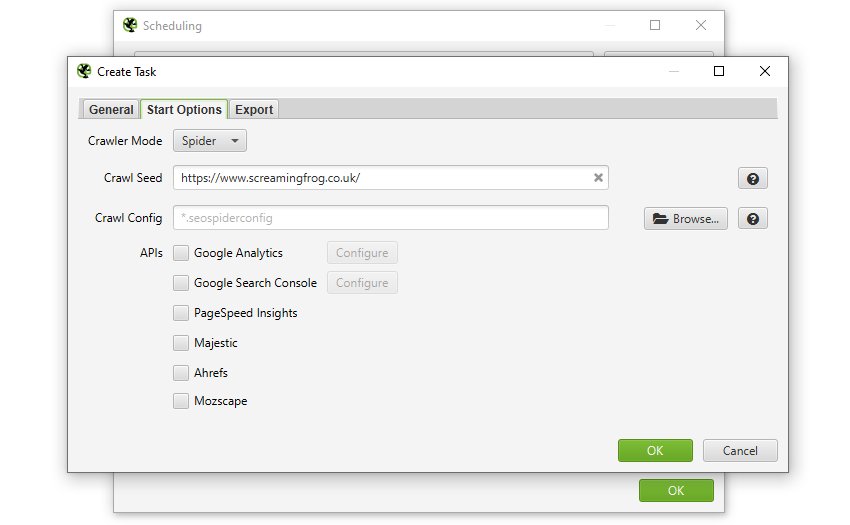
モード(スパイダー、リスト)、保存された設定、API(Google Analytics、Search Console、Majestic、Ahrefs、Moz)をあらかじめ選択し、スケジュールされたクロールに必要なデータを取り込むことが可能です。
また、クロールファイルを自動的に保存し、タブ、一括エクスポート、レポート、XML Sitemapsのいずれかを選択した場所にエクスポートすることができます。
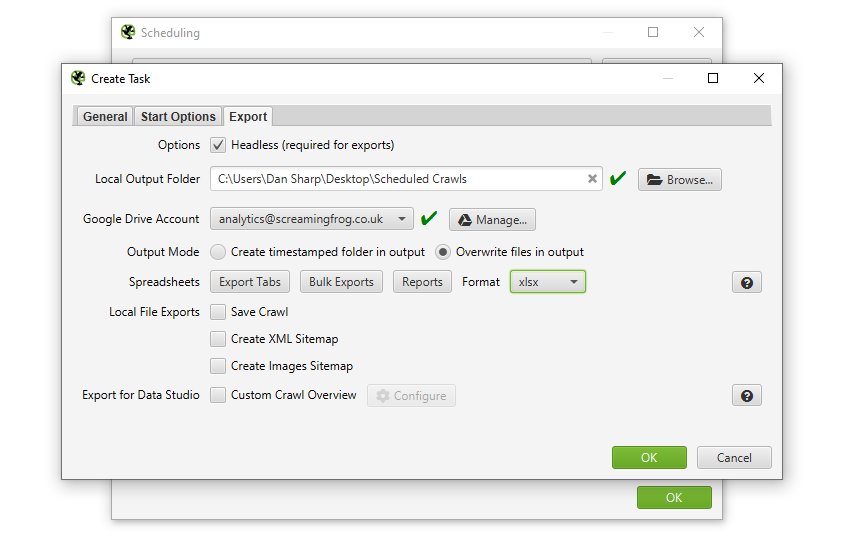
エクスポートを選択する際、「format(フォーマット)」をgsheetに切り替えることで、タブ、フィルタ、エクスポート、レポートを自動的にGoogle Sheetsにエクスポートするように選択することができます。
これにより、Google Driveアカウント内の「Screaming Frog SEO spider」フォルダにGoogleシートが保存されます。
スケジュール管理で使用した「project name(プロジェクト名)」と「crawl name(クロール名)」は、エクスポートのためのフォルダとして使用されます。
例えば、「Screaming Frog」というプロジェクト名と「Weekly Crawl」という名前で、Google Drive内に以下のように配置されます。

また、既存のファイルがある場合は上書きするか、Google Driveにタイムスタンプ付きのフォルダを作成するかを選択することができます。
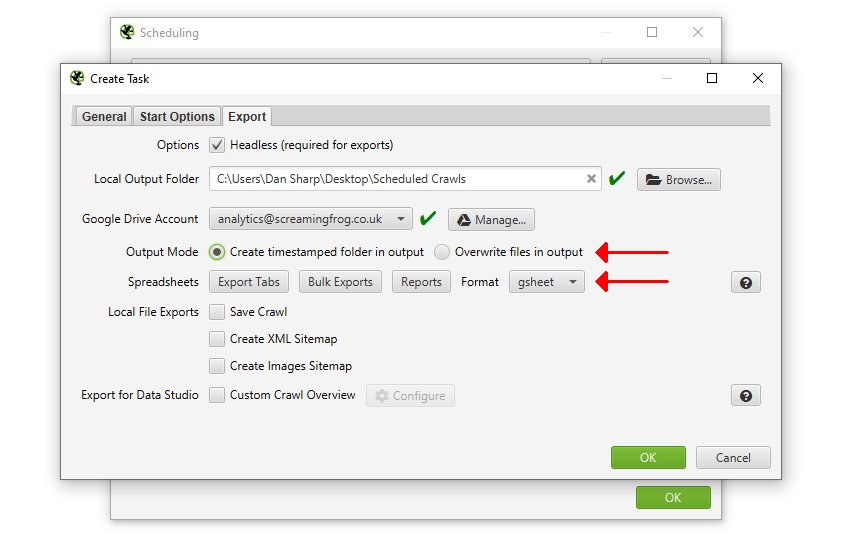
最後に、Google Data Studio に接続するために Google Sheets にエクスポートしたい場合は、「‘Export For Data Studio’」カスタム概要エクスポートを使用します。
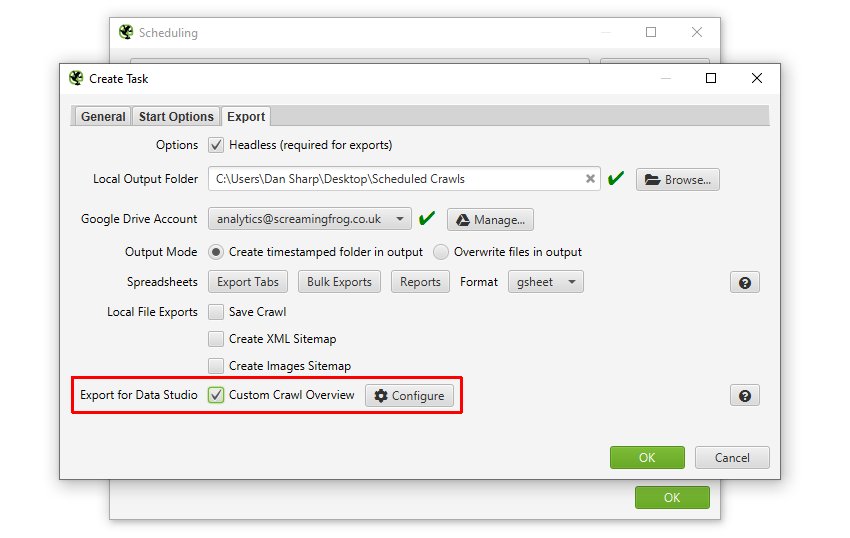
これは、Google Sheetsに1つのサマリー行としてエクスポートされるクロールの概要データをユーザーが選択できるようにすることを目的に作られました。
時系列で同じシートの新しい行に、新しくスケジュールされたエクスポートを自動的に追加します。この設定を行うには、チュートリアル ‘How To Automate Crawl Reports In Data Studio‘ をお読みください。
スケジューリングのコツ
スケジューリングを利用する際には、いくつかの注意点があります。
- データベース保存モードを使用している場合、クロールはSEOスパイダーsのデータベース内に自動的に保存されるため、スケジューリング時に「保存」する必要はありません。クロールは、スケジュールされたクロールが実行された後、アプリケーションの「’File > Crawls’」メニューから開くことが可能です。クロールを保存、開く、エクスポート、インポートする方法については、こちらのガイドをご覧ください。
- スケジュールされたクロールに対して、SEOスパイダーの新しいインスタンスが開始されます。そのため、クロールが重なった場合、前のクロールが完了するまで遅延するのではなく、複数のSEOスパイダーのインスタンスが同時に実行されます。そのため、システムリソースを考慮し、クロールのタイミングを適切に設定することをお勧めします。
- SEOスパイダーは、データのエクスポートが予定されているとき、ヘッドレスモード(インターフェイスなしという意味)で実行されます。これは、ユーザーとのインタラクションや、アプリケーションが目の前で起動し、オプションがクリックされるという、ちょっと奇妙なことを避けるためです。
- このスケジューリングはユーザーインターフェース内で行われます。コマンドラインを使用してSEOスパイダーを操作したい場合は、コマンドラインインターフェースガイドをご覧ください。
エクスポート
インリンク、アウトリンクの一括エクスポートを含め、クロールの全データをエクスポートすることができます。データのエクスポートには、主に以下の3つの方法があります。
タブとフィルター(トップウィンドウのデータ)をエクスポートする
左上の「エクスポート(赤枠)」ボタンをクリックするだけで、トップウィンドウのタブやフィルターからデータをエクスポートすることができます。

トップウィンドウセクションのエクスポート機能は、トップウィンドウに表示されている現在の視野で動作します。
したがって、フィルタを使用している場合、「Export」をクリックすると、フィルタリングされたオプションに含まれるデータのみがエクスポートされます。
Addressデータを書き出す
Addressデータをエクスポートするには、各種データをエクスポートしたいURLの上で右クリックし、いずれかのオプションをクリックするだけです。
この方法で、以下のAddressタブの詳細をエクスポートすることができます。
- URLの詳細
- 内部リンク
- 発リンク
- 画像の詳細
- リソース
- 重複の詳細
- 構造化データの詳細
- スペル・文法詳細
- クロールパスレポート

このデータは、下部のウィンドウタブにある「Export」ボタンからエクスポートすることもできます。

また、URLを複数選択して(キーボードのcontrolまたはshiftを押しながら)、これらのURLのデータを一括してエクスポートすることもできます。
例えば、特定のURLへの「内部リンク」をまとめて同じようにエクスポートすることができます。

一括エクスポート
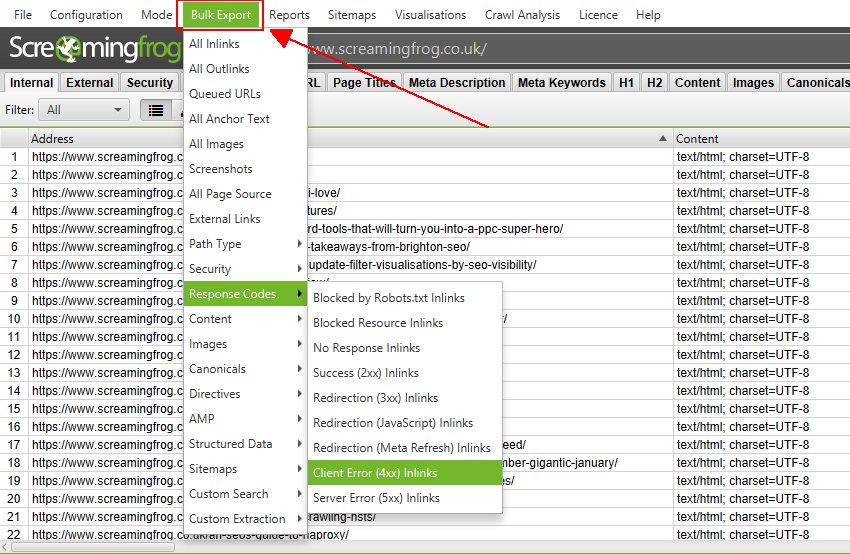
「Bulk Export」はトップレベルメニューの下にあり、全データの一括エクスポートが可能です。
「All inlinks」オプションを使用してクロールで見つかったリンクの全ての情報をエクスポートしたり、2XX、3XX、4XX、5XXレスポンスなど特定のステータスコードを持つURLへの全ての内部リンクをエクスポートできます。
例えば、「Bulk Export > Response codes > Client Error 4XX In Links(一括エクスポート > レスポンスコード > クライアントエラー 4XXエラーリンク)」オプションを選択すると、全てのエラーページ(404エラーページなど)への内部リンクがエクスポートされます。
また、サイト内の全ての画像のaltテキスト、altテキストがない全ての画像、全てのアンカーテキストをエクスポートすることも可能です。
エクスポートに関するビデオガイドをご覧ください。
一括エクスポートオプション
「一括エクスポート」のトップレベルメニューでは、以下のエクスポートオプションが利用可能です。
- Queued URLs:これらは、発見された全てのURLで、クロールするためのキューに入っているものです。これは、GUI の右下隅に表示される「残り」の URL の数とほぼ一致します。
- Links > All Inlinks: SEOスパイダーがサイトをクロールして発見した全ての内部リンク。Response CodesタブのAllフィルターにある全てのURL(ahrefだけでなく、画像、canonical、hreflang、rel next/prevなど)へのリンクが含まれています。
- Links > All Outlinks: SEOスパイダーがクロール中に発見した全てのページ外へのリンク。これは、’All’フィルターのレスポンスコード・タブにある全てのURLに含まれる全てのリンクを含みます。
- Links > All Anchor Text: 「‘Response Codes’」タブの「‘All’」フィルターにあるURLへの全ての内部リンクおよび発リンク。
- Links > External Links:「リンク」タブの「全て」フィルターで見つかったURLへの全てのリンク。
- Links > ‘Other’:「リンク」タブの対応するフィルターにあるURLへの全てのリンク。
- 例:「内部リンク・発リンクにおける非記述的アンカーテキスト」を持つURLへのリンクがあるページ。
- 例:「内部リンク・発リンクにおける非記述的アンカーテキスト」を持つURLへのリンクがあるページ。
- Web > Screenshots: JavaScriptレンダリングモード使用時に保存される、「‘Rendered Page‘」下部ウィンドウタブで見られる全てのスクリーンショットをエクスポートします。
- Web > All Page Source: 静的なHTMLソース、またはクロールしたページのレンダリングHTMLです。レンダリングされたHTMLは、JavaScriptレンダリングモードのときのみ利用可能です。
- Web > All HTTP Headers: 全てのURLとそれに対応するHTTPレスポンスヘッダ。この値を表示するには、「’Config > Spider > Extraction’」で’HTTP Headers‘の抽出を有効にする必要があります。
- Web > All Cookies: クロールで発行された全てのURLと全てのCookie。このデータを取得するためには、「’Config > Spider > Extraction’」で「’Cookies‘」を抽出するよう設定する必要があります。また、JavaScriptやピクセル画像タグを使ってページに読み込まれたCookieを正確に表示するには、JavaScriptレンダリングモードを設定する必要があります。
- Path Type: 特定のパスタイプのリンクを、そのリンク元のページとともにエクスポートします。パス・タイプには、絶対リンク、プロトコル相対リンク、ルート相対リンク、パス相対リンクがあります。
- Security:「‘Unsafe Cross-Origin Links’」を含むサイト上の全てのページへのリンク。
- Response Codes:「Response Codes」タブの対応するフィルターにあるURLへの全てのリンク。例:サイト上で404エラーで応答するURLへの全てのソースリンク。
- Content:「Content」タブに対応するフィルターにあるURLへの全てのリンク。
- 例:ほんんど重複していると判断されたコンテンツURLや、指定した類似率を超える対応する全ての重複コンテンツURL。
- 例:ほんんど重複していると判断されたコンテンツURLや、指定した類似率を超える対応する全ての重複コンテンツURL。
- Images:「images」タブの対応するフィルターにある画像URLへの全ての参照。
- 例:altテキストがない画像への全ての参照。
- 例:altテキストがない画像への全ての参照。
- Canonicals:「Canonicals」タブの対応するフィルターにあるURLへの全てのリンク。
- 例:canonicalsが欠落しているURLへのリンク。
- 例:canonicalsが欠落しているURLへのリンク。
- Directives:「Directives」タブの対応するフィルターにあるURLへの全てのリンク。
- 例:meta robots ‘noindex’ タグを含むサイト上の全てのページへのリンク。
- 例:meta robots ‘noindex’ タグを含むサイト上の全てのページへのリンク。
- AMP: 「AMP」タブの対応するフィルターにあるURLへの全てのリンク。
- 例:200以外のレスポンスのあるamp用のhtmlリンクを持つページ。
- 例:200以外のレスポンスのあるamp用のhtmlリンクを持つページ。
- Structured Data: 「Structured Data」タブの対応するフィルターにあるURLへの全てのリンク。
- 例:検証エラーのあるURLへのリンク。
- 例:検証エラーのあるURLへのリンク。
- Sitemaps: 「Sitemaps」タブの対応するフィルターにある画像URLへの全ての参照。
- 例:インデックス不可能なURLを含む全てのXML Sitemaps。
- 例:インデックス不可能なURLを含む全てのXML Sitemaps。
- Custom Search: 「Custom Search」タブの対応するフィルターにあるURLへの全リンク。
- 例:カスタム検索にマッチしたサイト内の全ページへのリンク。
- 例:カスタム検索にマッチしたサイト内の全ページへのリンク。
- Custom Extraction: 「カスタム抽出」タブの対応するフィルターにあるURLへの全てのリンク。
- 例:[カスタム抽出]で設定された特定のデータ抽出を行うページへのリンク。
- 例:[カスタム抽出]で設定された特定のデータ抽出を行うページへのリンク。
- URL Inspection: Search ConsoleのURL Inspection API統合による粒度の細かい「Rich Results」、「Referring Pages」、「Sitemaps」データが含まれます。「Rich Results」の一括エクスポートには、リッチリザルトタイプ、有効性、重大度、および問題タイプが含まれます。
「Referring Pages」には、検査した各URLで利用可能な最大5つの参照ページが含まれます。「Sitemaps」には、検査したURLと、そのURLの中に発見されたサイトマップが含まれます。 - Issues: 「Issues」タブで発見された全ての課題(その「インリンク」バリアントを含む)を、フォルダー内の個別のスプレッドシートとして(CSV、Excel、Sheetsとして)表示します。
書き出し形式
エクスポートを選択すると、保存するファイルの「種類」を選択することができます。
- CSV
- Excel 97-2004
- Workbook
- Excel Workbook
- Google Sheets
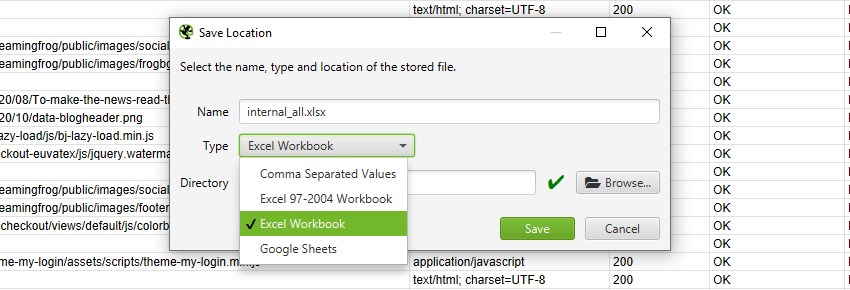
CSV、Excel 97-2004 Workbook、Excel Workbookとしてエクスポートするには、種類を選択し、「Save(保存)」をクリックするだけです。
初めてGoogle Sheetsにエクスポートする場合は、「Type(タイプ)」をGoogle Sheetsにし、「Manage(管理)」をクリックする必要があります。
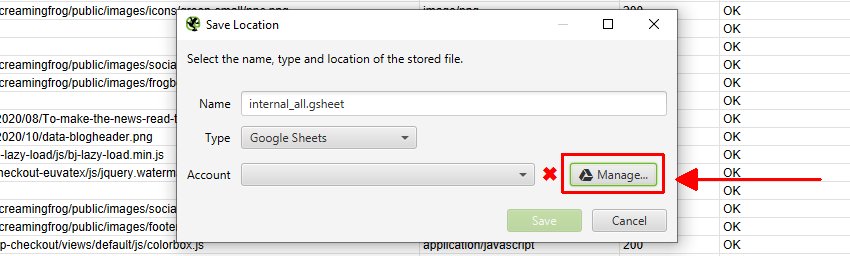
次に、次のウィンドウで「Add(追加)」をクリックして、エクスポートするGoogleアカウントを追加します。
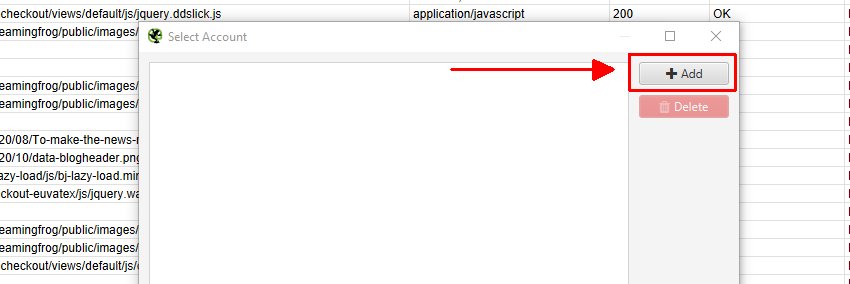
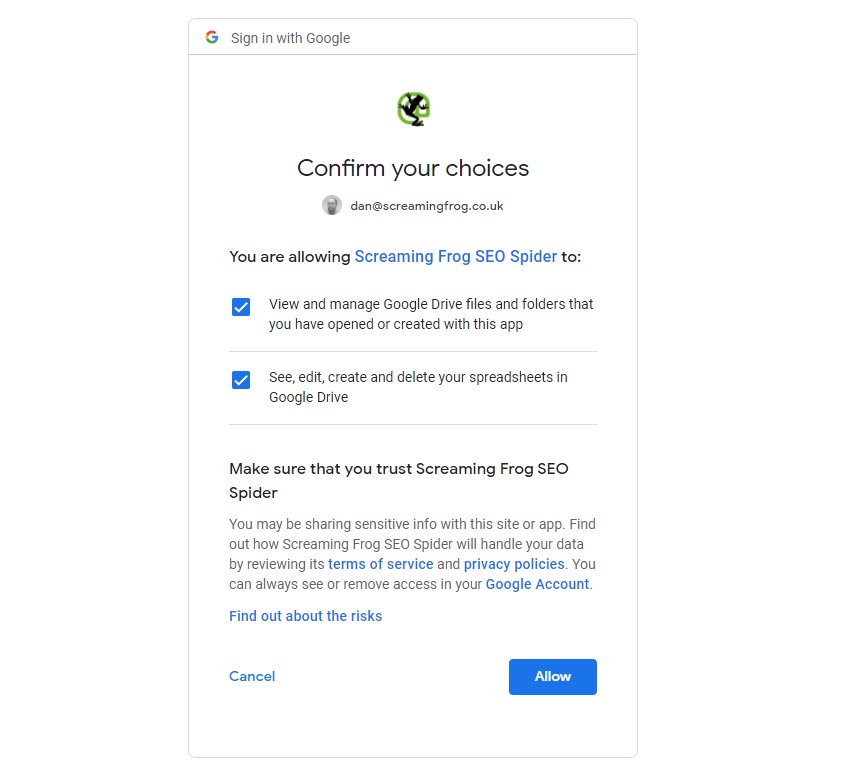
ブラウザでGoogleアカウントを選択し、サインインしてください。
「許可」を2回クリックし、SEOスパイダーがGoogle Driveアカウントにデータをエクスポートすることを「Allow(許可)」するよう選択を確認します。
許可したら、「OK」をクリックすると、「Account(アカウント)」にあなたのアカウントの電子メールが表示され、「Save(保存)」を選択できるようになります。
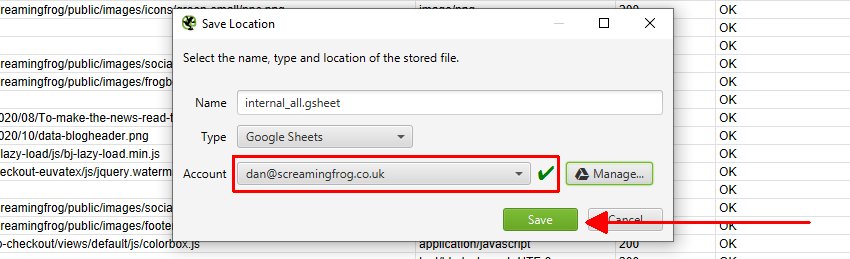
保存を行うと、エクスポートはGoogle Sheetsで利用できるようになります。
また、SEOスパイダーは、Google Driveアカウントにエクスポートを入れた「Screaming Frog SEOスパイダー」フォルダを自動的に作成します。
SEOスパイダーの初期設定では、内部タブに約55カラムがあり、切り捨てられる前に約90,000行までエクスポートできます(55 x 90,000 = 4,950,000 cells)。
より多くの行をエクスポートする必要がある場合は、エクスポートの列数を減らすか、サイズに合わせて構築された別のエクスポート形式を使用してください。
複数のシートに書き出す作業を始めていましたが、Google Sheetsは現在このような使い方をするべきではありません。
Google Sheetsのエクスポートは、スケジューリングと コマンドラインに統合されました。
つまり、クロールをスケジュールすることで、タブ、フィルター、エクスポート、レポートなどを自動的にGoogle Drive内のSheetにエクスポートすることができます。
スケジュール管理で使用する「プロジェクト名」と「クロール名」は、Google Driveにエクスポートする際のフォルダとして使用されます。例えば、「Screaming Frog」というプロジェクト名と「Weekly Crawl」という名前で、Google Drive内に以下のように配置されます。
また、既存のファイルがある場合は上書きするか、Google Driveにタイムスタンプ付きのフォルダを作成するかを選択することができます。
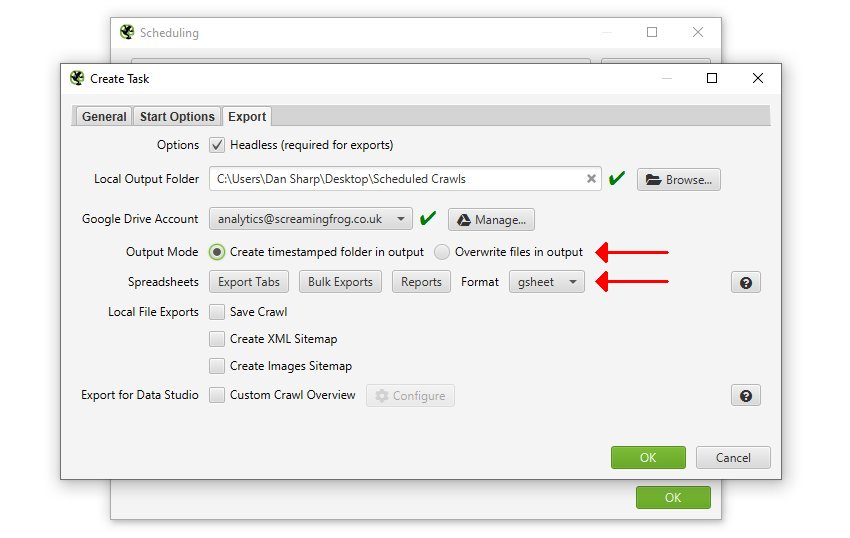
Google Data Studio に接続するために Google Sheets にエクスポートしたい場合は、「Export For Data Studio」カスタム概要エクスポートを使用します。
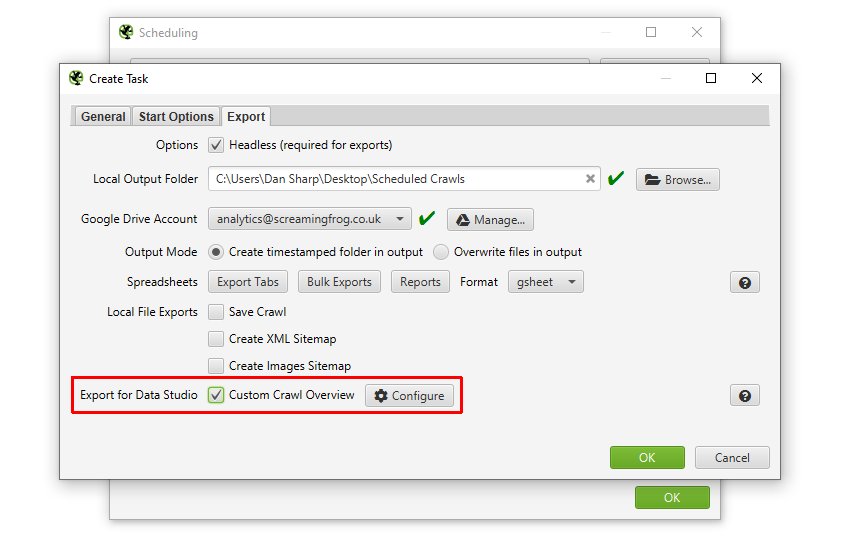
これは、Google Sheetsに1つのサマリー行としてエクスポートされるクロールの概要データをユーザーが選択できるようにすることを目的に作られました。時系列で同じシートの新しい行に、新しくスケジュールされたエクスポートを自動的に追加します。
この設定を行うには、チュートリアル ‘How To Automate Crawl Reports In Data Studio‘ をお読みください。
データベース保存モードを使用している場合、クロールはSEOスパイダーsのデータベース内に自動的に保存されるため、スケジューリングで「Save」する必要はありません。
Robots.txt
ScreamingFrogSEOスパイダーは、robots.txtに準拠しています。Googleと同じようにrobots.txtに従います。
サブドメインのrobots.txtをチェックし、SEOスパイダーのユーザーエージェント(Googlebotでない場合は全てのロボット)専用のディレクティブに従って(許可/不許可)動作します。
現在、初期設定でGooglebot用の挙動に従います。したがって、サイトの特定のページや領域がGooglebotに許可されていない場合、SEOスパイダーはそれらもクロールしません。
Googlebotと同様に、ファイル値のURLマッチング(ワイルドカード * / $)もサポートしています。
有料版では、「Configuration > robots.txt > Settings > Ignore robots.txt(設定 > robots.txt > セッティング > robots.txtを無視する)」を選択することで、robots.txt を無視する(ダウンロードすらしない)ことが可能です。
また、「Response Codes」タブと「Blocked by Robots.txt」フィルタで、robots.txtでブロックされたURLを表示することができます。これは、ブロックされた各URLに対する許可しないのrobots.txtの一致した行も表示されます。
最後に、robots.txtのカスタム設定もあり、「Configuration > robots.txt > Custom(設定 > robots.txt > カスタム)」でサイトのrobots.txtをダウンロード、編集、テストすることが可能です。robots.txt testerとして、ScreamingFrogSEOスパイダーを使用する方法については、ユーザーガイドをお読みください。
robots.txtで覚えておくべきいくつかのこと
- SEOスパイダーは、robots.txtのプロトコルに従って、1組のユーザーエージェントディレクティブにのみ従います。したがって、SEOスパイダーのUAがあればそちらを優先します。そうでない場合、SEOスパイダーはGooglebot UA用のコマンド、または最後に「ALL」またはグローバルディレクティブに従います。
- 上記を繰り返すと、SEOスパイダーまたはGooglebotに挙動を指定した場合、全ての(または「グローバル」)ボットコマンドは無視されます。グローバルディレクティブに従いたい場合は、SEOスパイダーまたはGooglebotのための特定のUAセクションの下にそれらの行を含める必要があります。
- 競合する挙動 (たとえば、同じファイルパスに対する allow と disallow) がある場合、一致する allow 宣言は、コマンドに含まれる文字が同じかそれ以上であれば、一致する disallow よりも優先されることに注意してください。
- robots user agentが空白のままだと、SEOスパイダーは*のルールがある場合のみ従います。
ユーザーエージェント
SEOスパイダーはrobots.txtの指示内容に従います。ユーザーエージェントは「’Screaming Frog SEO Spider’」なので、もし当ツールをブロックしたい場合はrobots.txtに次のように記述してください。
User-agent: Screaming Frog SEO Spider
Disallow: /
また、SEOスパイダー用にサイトの特定の領域を除外したい場合は、通常のrobots.txt構文に当ツールを指定するだけです。
メモリ
概要
SEOスパイダーは、設定可能なハイブリッドストレージエンジンを使用しており、数百万のURLをクロールすることが可能です。ただし、メモリとストレージの設定、および推奨ハードウェアが必要です。
初期設定では、SEOスパイダーはディスクに保存するのではなく、RAMを使用してクロールを行います。これには利点がありますが、多くのRAMを割り当てないと大規模なクロールができません。
SEOスパイダーは、データベースストレージモードを使用してディスクに保存するように設定することができます。これにより、大規模なクロールが可能になり、保存したクロールをより速く開くことができます。
また、クロールデータを継続的に保存することにより、誤ってマシンを再起動したりクロールを「消去」したりすることによる「クロールの喪失」を回避することができます。
メモリ保存モード
標準メモリ保存モードでは、クロールできるページ数に決まりはなく、サイトの複雑さとユーザーのマシンスペックに依存します。SEOスパイダーの最大メモリは32bitで1GB、64bitで2GBに設定されており、通常1万~10万URLのサイトをクロールすることが可能です。
SEOスパイダーのメモリ割り当てを増やすと、RAMだけで何十万ものURLをクロールすることができます。64ビットのマシンで8GBのRAMを搭載している場合、メモリ割り当てを増やせば、一般的に数十万URLのクロールが可能になります。
データベース保存モード
SEOスパイダーはクロールデータをディスクに保存するように設定することができ、これにより何百万ものURLをクロールすることが可能になります。
また、クロールは自動的にデータベース保存モードで保存され、「File > Crawls(ファイル > クロール)」メニューから素早く開くことができます。
ハードディスクドライブはデータの書き込みと読み出しに著しく時間がかかるため、ソリッドステートドライブ(SSD)を使用している全ての利用ユーザーには、データベースストレージモードを初期設定のストレージ構成として推奨しています。
これは、データベースストレージモードを選択することで設定できます(「Configuration > System > Storage(設定 > システム > ストレージ)」の下)。
目安として、SSDと4GBのRAMをデータベースストレージモードに割り当てた場合、SEOスパイダーは約200万件のURLをクロールすることができます。
この構成は、ほとんどのユーザーが日常的に使用する初期設定のセットアップとしてお勧めします。
高いメモリ使用量
クロールを実行する際に、以下のような「メモリ使用量が多い」という警告メッセージが表示される場合があります。
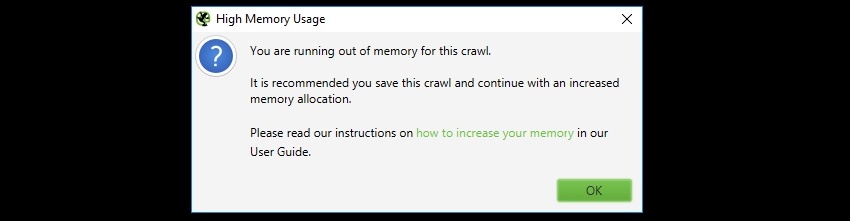
もしくは、大規模なクロールでクロールやプログラム自体の動作が遅くなる場合、メモリ割り当てに達していることが原因である可能性があります。
これは、SEOスパイダーが現在のメモリ割り当てに達したことを警告するもので、より多くのURLをクロールできるようにするには、2つのオプションがあります。
- データベースストレージモードへの切り替え
これが次のステップの推奨事項です。データベースストレージモードは、全てのクロールデータをディスクに保存し、同じメモリ割り当てでより多くのURLをクロールすることができます。 - メモリ割り当ての増加
データベースストレージモードに移行できない場合、またはデータベースストレージモードでのメモリ割り当てに達した場合のみ、メモリ割り当てを増加させることをお勧めします。これにより、RAMに保持できるデータ量が増加し、より多くのURLをクロールできるようになります。
また、これらのオプションを組み合わせて、パフォーマンスを向上させることも可能です。
まず、メモリー保存モードの場合、設定を変更する前に「‘File > Save’」メニューでクロールを保存しておく必要があります。
これにより、変更後にクロールを再開することができます。データベース保存モードの場合、クロールは自動的に保存され、「File > Crawls(ファイル > クロール)」で再開することができます。
データベースストレージへの切り替え
上述したように、データベースストレージモードに切り替えることで、クロール可能なURLの数を増やすことができます。このストレージモードにはSSDの使用を推奨しており、アプリケーション内で素早く設定することができます(「Configuration > System > Storage(設定 > システム > ストレージ)」)。
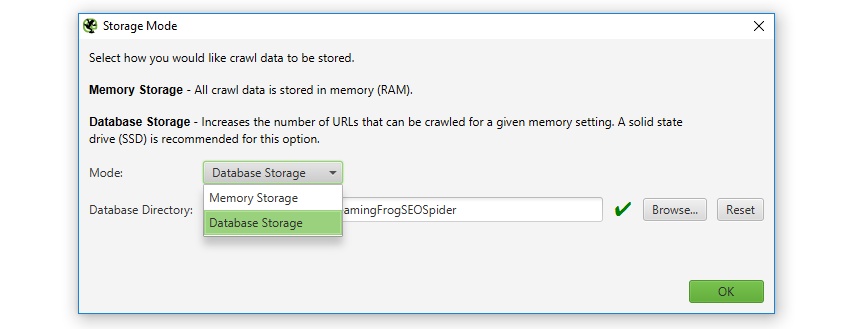
SSDを搭載している利用ユーザーや、大規模なクロールを行う場合は、このストレージを初期設定として使用することをお勧めします。
データベースストレージモードでは、一定のメモリ容量でより多くのURLをクロールすることができ、SSDを搭載したセットアップではRAMストレージに近いクロール速度が得られます。
初期設定のクロール上限は500万URLですが、これは厳しい制限ではなく、SEOスパイダーは(適切なセットアップをすれば)それ以上のクロールが可能です。
200万URL以下のクロールには、データベースストレージと4GBのRAMの割り当てをお勧めします。
推奨はしませんが、SSDではなく高速なハードディスクドライブ(HDD)を使用している場合、このモードでもより多くのURLをクロールすることができます。ただし、ハードディスクの書き込み・読み込み速度がクロールのボトルネックになるため、クロール速度もインターフェイス自体も大幅に遅くなります。
クロール中にマシン上で作業を行う場合、マシンのパフォーマンスにも影響を与えるため、負荷に対応するためにクロール速度を落とす必要があるかもしれません。
SSDは非常に高速なので、原則はこの問題は発生しません。このため、小規模なクロールでも大規模なクロールでも、「database storage(データベースストレージ)」を初期設定として使用することができます。
メモリ保存モードからクロールをインポートするには、クロールの保存、オープン、エクスポート、インポートに関するガイドをお読みください。
メモリ割り当ての増加
「Configuration > System > Memory(設定 > システム > メモリ)」を選択することで、アプリケーション内でメモリ割り当てを設定することができます。これにより、データベース保存モードであっても、SEOスパイダーがより多くのURLをクロールできるようになります。
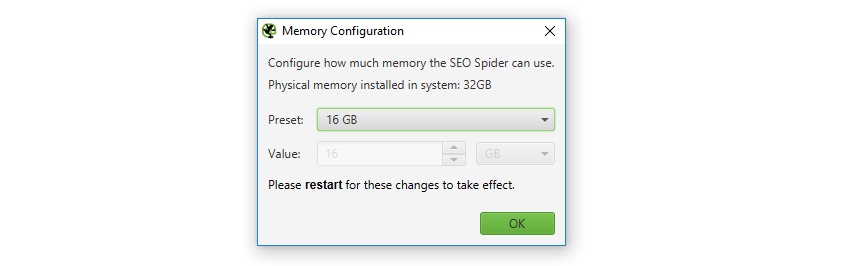
SEOスパイダーはシステムに搭載されている物理メモリを通信し、素早く設定できるようにします。システムには最低でも2~4gbの空きRAMを確保することをお勧めします。例えば、8GBのRAMを搭載している場合、最大4~6GBのRAMを割り当てることをお勧めします。
変更を反映させるために、アプリケーションを再起動することを忘れないでください。設定が反映されていることを確認するには、こちらのガイドに従ってください。
保存したクロールを開くには、クロールの保存、開く、エクスポート、インポートに関するガイドをお読みください。
メモリ割り当ての確認
メモリ設定を更新した後、「Help > Debug(ヘルプ > デバッグ)」で「Memory(メモリ)」の行を見ることで、変更が反映されていることを確認できます。
SEOスパイダーは初期設定で1GB(32ビット)または2GB(64ビット)なので、以下のような行程になります。
- メモリ物理=16.0GB
- 使用=170MB
- 空き=85MB
- 合計=256MB
- 最大=2,048MB
- 使用率8%。
最大値は、常に割り当て量より少し少なくなります。4GBを割り当てる場合、以下のようになります。
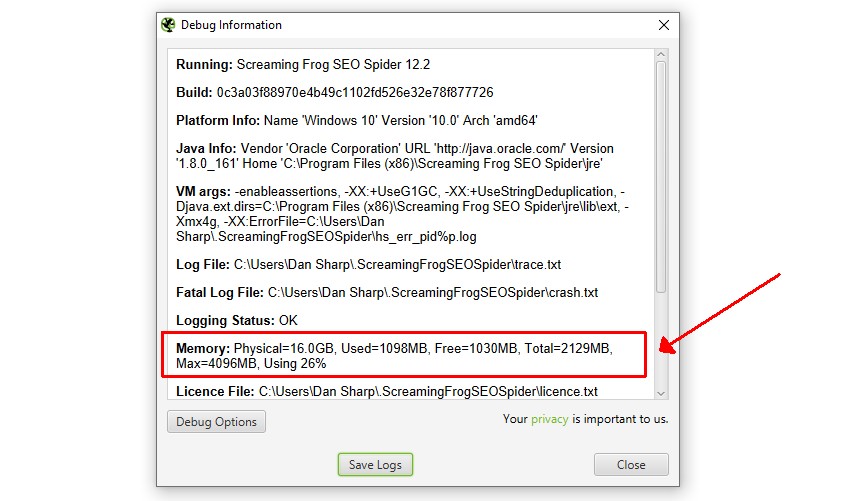
この場合、「Max=4,096MB」は、4GBのRAMが正しく割り当てられたことを示します。
VMのオーバーヘッドはOSやJavaのバージョンによって異なるため、ここに示された数値は正確ではありません。
トラブルシューティング
- C:\Program Files (x86)\Screaming Frog SEO Spider\ScreamingFrogSEOSpider.l4j.ini に余計な -Xmx 行がないことを確認してください。
- メモリの設定を変更しても出力が変わらない場合は、環境変数に_JAVA_OPTSが設定されていないことを確認してください。
クッキー
GoogleはCookieを使わずにWebサイトをクロールしますが、ページを読み込んでいる間はCookieを受けます。一部のWebサイトでは、Cookieを受け入れた場合にのみ表示され、受け入れが無効になっている場合は失敗します。
初期設定では、SEOスパイダーは「セッションのみ」クッキーを受け付けます。これは、ページロード時に受け入れられ、その後クリアされ、Googlebotと同じように追加のリクエストに使用されないことを意味します。
Cookieの保存方法は、「Configuration > Spider > Advanced(設定 > スパイダー > 高度)」で初期設定の「Session Only(セッションのみ)」から「Persistent(持続)」または「Do Not Store(保存しない)」のいずれかに調整できます。
XMLサイトマップ作成
SEOスパイダーでは、トップレベルのナビゲーションにある「Sitemaps」の下にあるXMLサイトマップや特定の画像XMLサイトマップを作成することができます。

「XML Sitemap」は、クロールで発見された全てのHTML 200レスポンスページと、PDF、画像を含むXML Sitemapを作成する機能です。
「画像サイトマップ」は、「XMLサイトマップ」とは少し異なり、「画像」を含むオプションです。このオプションは、200レスポンスの全ての画像と、画像が掲載されているページのみを含みます。
URL数が49,999を超える場合、SEOスパイダーは自動的にサイトマップファイルを追加作成し、サイトマップの場所を参照するサイトマップインデックスファイルを作成することができます。SEOスパイダーはsitemaps.orgのプロトコルに準拠したサイトマップを作成します。
SEOスパイダーをXML Sitemap Generatorとして使用する方法についての詳細なチュートリアルを読むか、XML Sitemapの各設定オプションの簡単な概要を以下に示します。
サイトマップに含まれるページを調整する
初期設定では、クロールからの応答が「200」であるHTMLページのみがサイトマップに含まれるため、3XX、4XX、5XXの応答は含まれません。
また、「noindex」、「canonicalised」(正規のURLとページのURLが異なる)、ページネーション(rel=”prev “が付いたURL)、PDFのページは標準では含まれませんが、XML Sitemapの「pages(ページ)」設定で調整することが可能です。
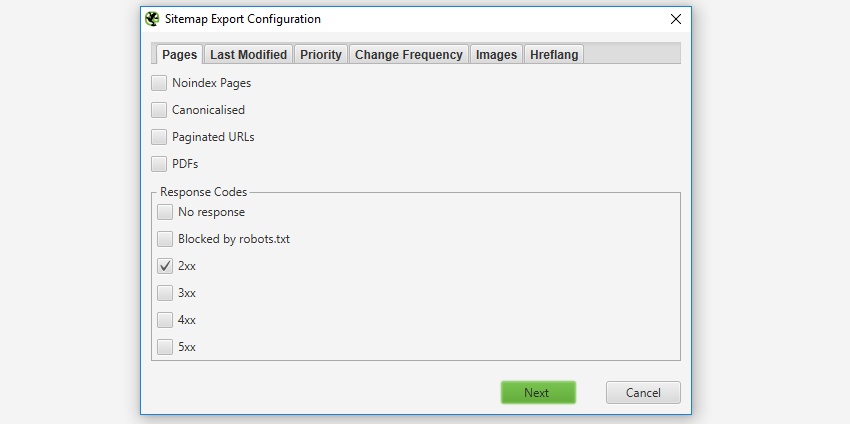
もしXMLサイトマップのエクスポートに含めたくないクロール済みのURLがある場合、XMLサイトマップを作成する前にユーザーインターフェース(Address一覧)でURLを個別に選択後に右クリックして「削除」するだけです。
また、「internal(内部)」タブを Excel にエクスポートし、フィルタリングして不要な URL を削除し、リストモードでファイルを再アップロードしてからサイトマップをエクスポートすることもできます。さらに、クロール前に、除外機能やrobots.txtでブロックすることもできます。
最終更新日
XML Sitemapに「lastmod(最終更新日)」属性を含めるかどうかは任意ですので、当然ながらSEOスパイダーでも任意で作成が可能です。
この設定により、全てのURLについて、サーバーの応答、またはカスタム日付を使用することができます。
優先順位
「Priority(優先順位)」は、XMLサイトマップに含めるオプションの属性です。URLの優先順位を設定しない場合は、「include priority tag(タグを優先にする)」のボックスを外すことで除外できます。

変更頻度
「changefreq(変更頻度)属性」を含めるかどうかはオプションで、SEOスパイダーではURLの「last modification header(最終更新ヘッダー)」や「level(深さ)」を元に設定することが可能です。
「最終更新日時から計算」は、過去24時間以内にページが変更された場合は「毎日」、そうでない場合は「毎月」と設定されることを意味します。
画像
XMLサイトマップに画像を含めるかどうかは、完全に任意です。
「include images(画像を含める)」オプションにチェックを入れると、「internal(内部)」タブ(および「Images(画像))の下にある全ての画像が初期設定で含まれます。
以下の画像のように、CDN上に存在し、UI内の「外部」タブに表示される画像を含めるかどうかを選択することも可能です。
通常、ロゴやソーシャルプロファイルのアイコンのような画像は画像サイトマップに含まれないので、これらを除外するために、特定の数のソース属性参照を持つ画像のみを含めるように選択することもできます。
ロゴのような画像はサイト全体にリンクされることが多いですが、例えば商品ページの画像は1、2回しかリンクされないかもしれません。
「images(イメージ)」タブには、IMG Inlinksカラムがあり、画像が何回参照されたかを示すことで、含めるのに適した「内部リンク」の数を決定することができます。
ビジュアライゼーション
SEOスパイダーのトップレベルメニューには、3つの主要な可視化機能が用意されています。
- クロールの可視化
- ディレクトリツリーの可視化
- ワードクラウド
クロールの視覚化は内部リンクを表示するのに役立ち、ディレクトリツリーの視覚化はURLの構造と組織を理解するのに便利です。
Word Cloudを使用すると、特定のページのテキストにリンクするために単語がどのくらい使用されているかを視覚化することができます。
「Visualisations」トップレベルメニューから利用できる、クロールとディレクトリツリーのビジュアライゼーションの力動図とツリーグラフバージョンがあります。
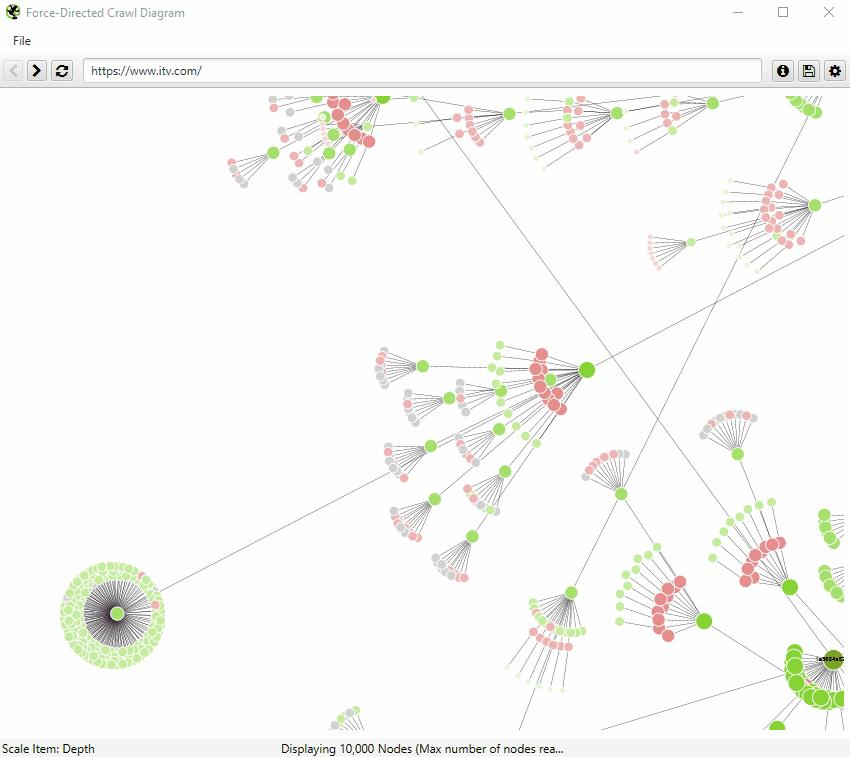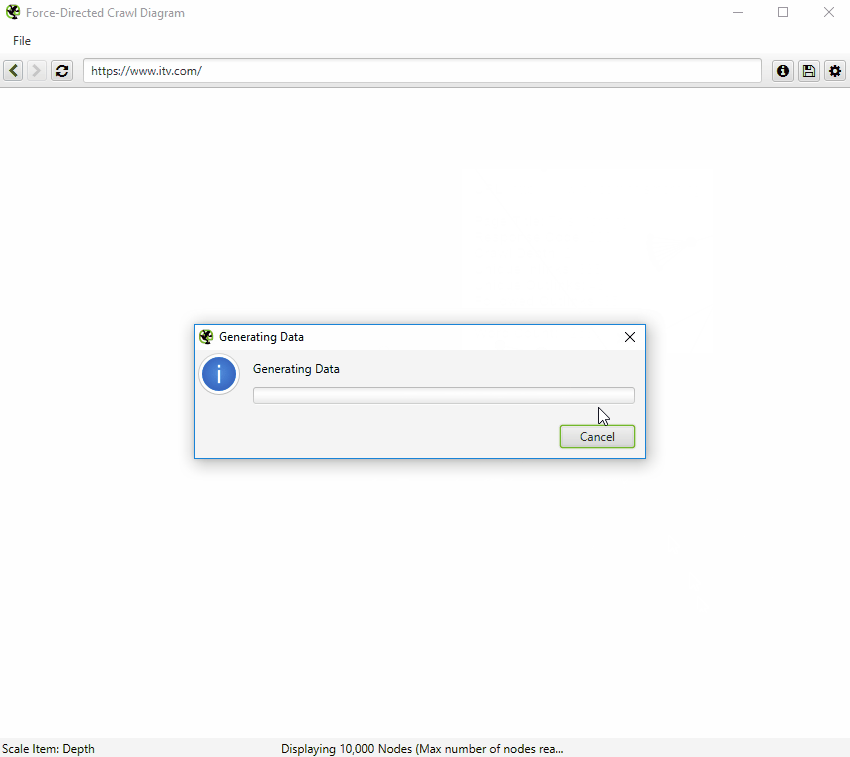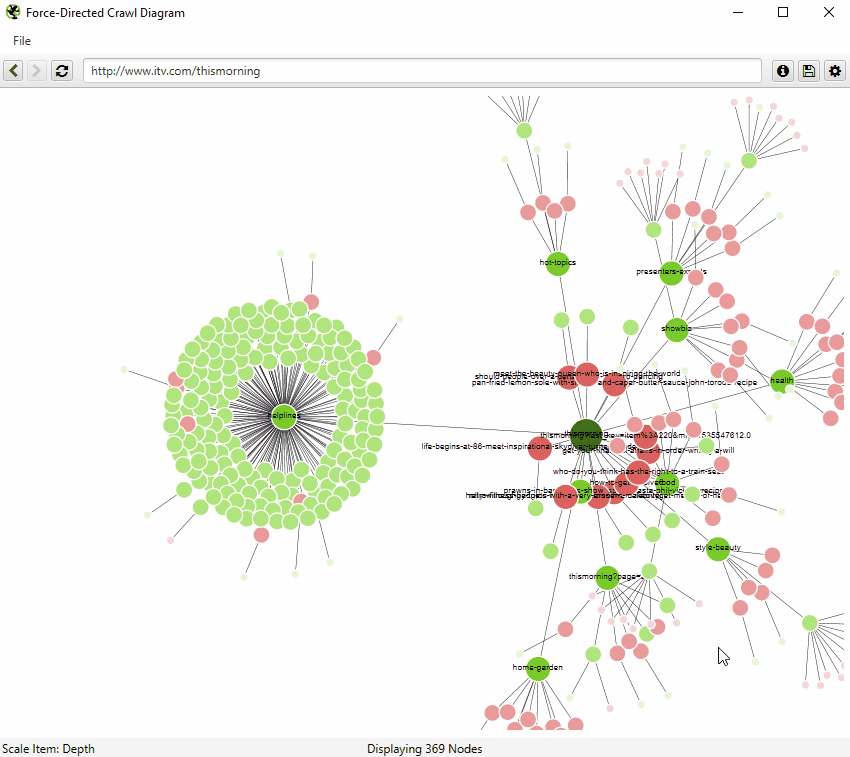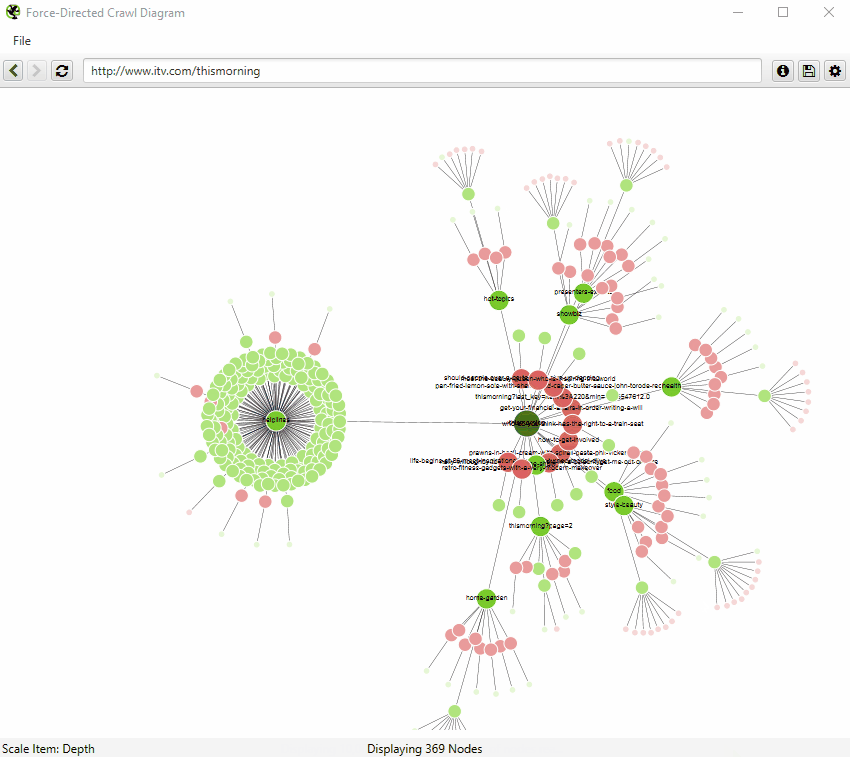
クロールのビジュアライゼーション
クロールの可視化には、「crawl visualisations(強制クロール図)」と「directory tree visualisations(クロールツリーグラフ)」があります。
これらのクロールの可視化は、SEOスパイダーがどのようにサイトをクロールしたかを、ページリンクで表示するため、内部リンクの分析に便利です。ページへの最短パスが複数ある場合(つまり、同じクロール深度の2つのURLからリンクされている場合)、最初にクロールされたURL(多くの場合、ソースの最初のもの)が使用されます。
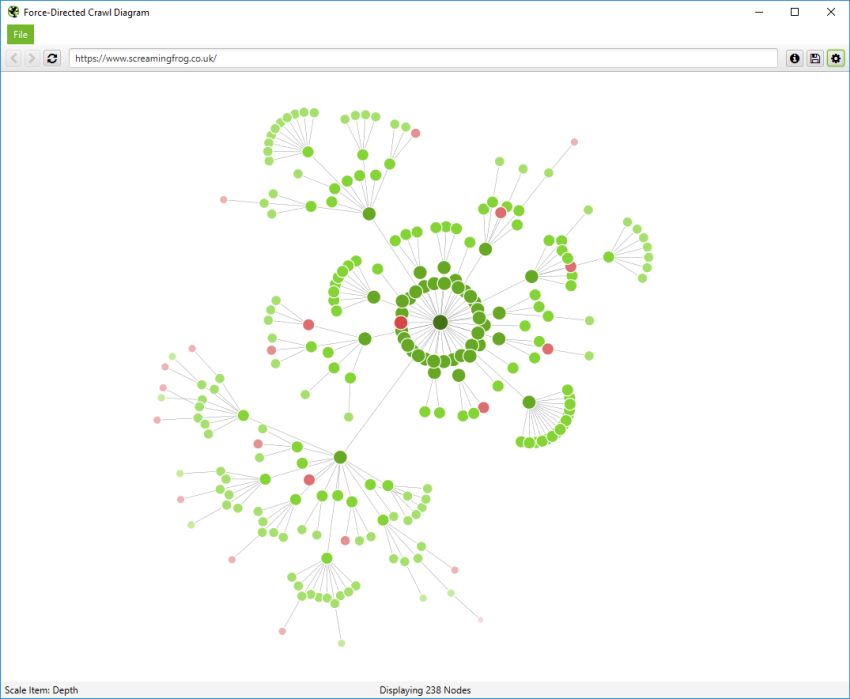
ビジュアライゼーションの右上にある「i」マークをクリックすると、それぞれの色が何を表しているかが説明されます。
可視化では、メモリを非常に消費するため、一度に10,000URLまで表示されます。ただし、任意のURLからその地点から閲覧することも可能です。
また、右クリックして「フォーカス」することで、サイトの特定のエリアを拡大し、そのセクションのURLをより多く表示することができます(さらに最大10,000URLを一度に表示できます)。ブラウザをナビゲーションとして使用し、URLを直接入力し、前方や後方に移動することができます。
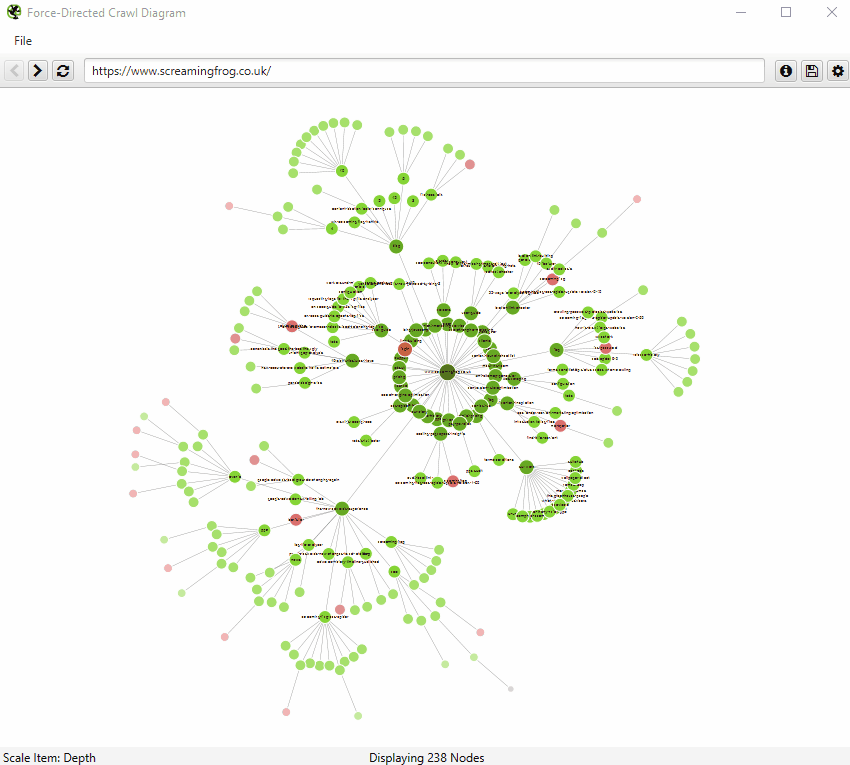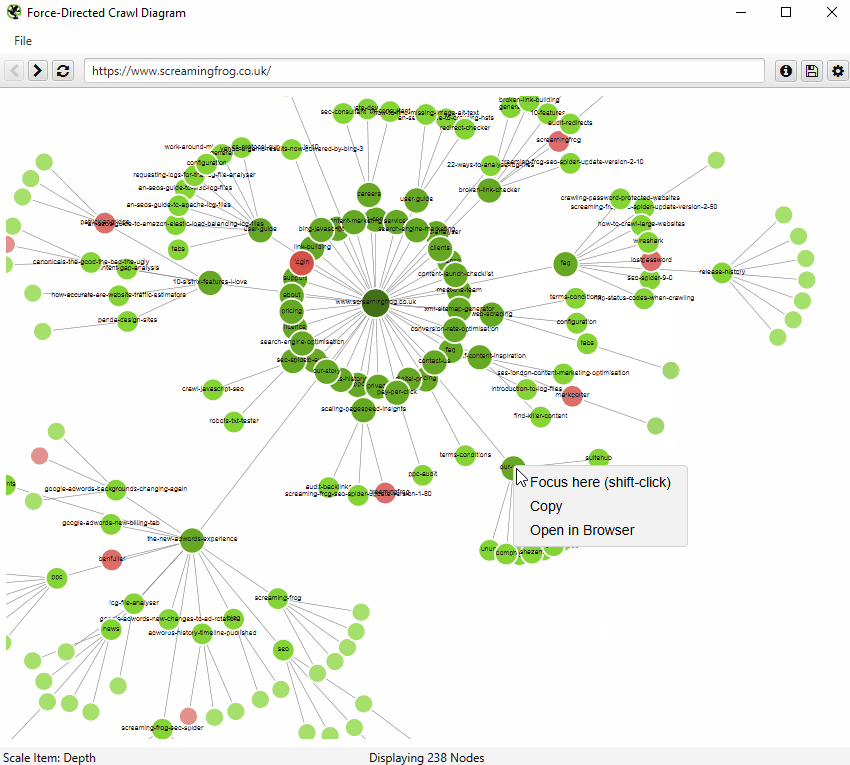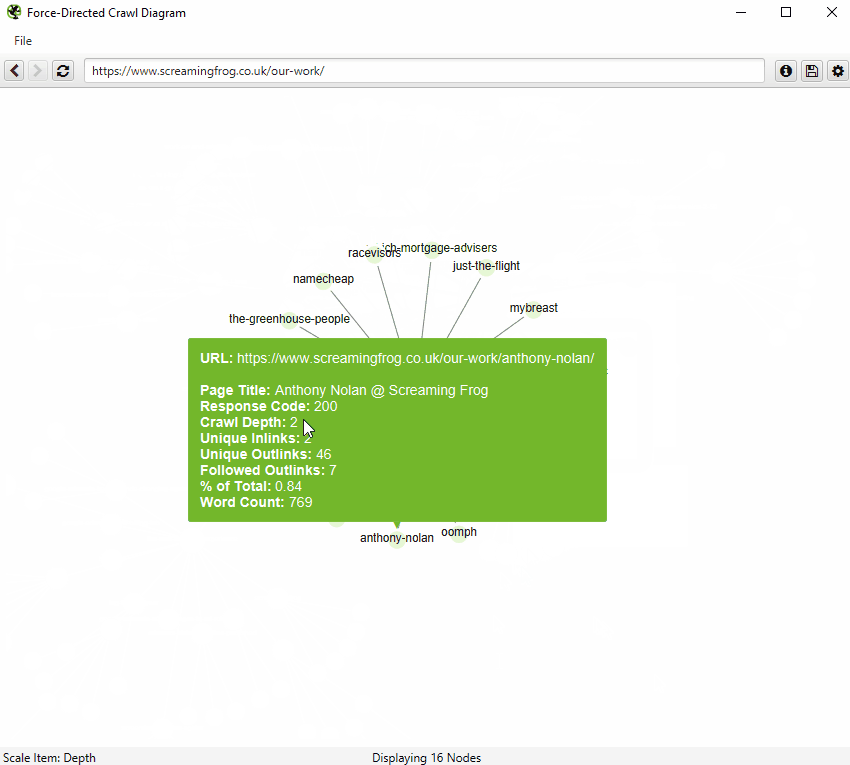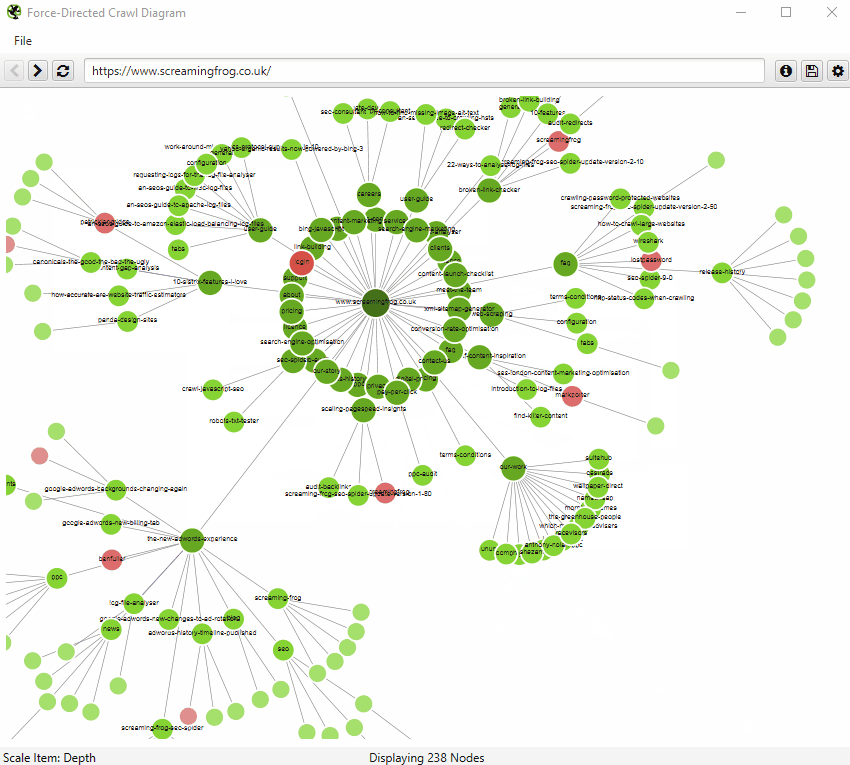
また、ブラウザに直接URLを入力したり、クロール中の任意のURLを右クリックして、その地点からビジュアルURLエクスプローラとして開くことも可能です。

ビジュアライゼーションが10,000URLの制限に達した場合、特定のノードが(サイズ制限のために)切り捨てられた子ノードを持つと、そのノードがグレーに着色されるので把握することができます。
この場合、右クリックして「探索」することで、子ノードを確認することができます。このようにして、クロール内の全てのURLを視覚化することができます。
また、ノードのサイズ、重なり、分離、色、リンクの長さ、テキストを表示するタイミングは、自由に設定することが可能です。
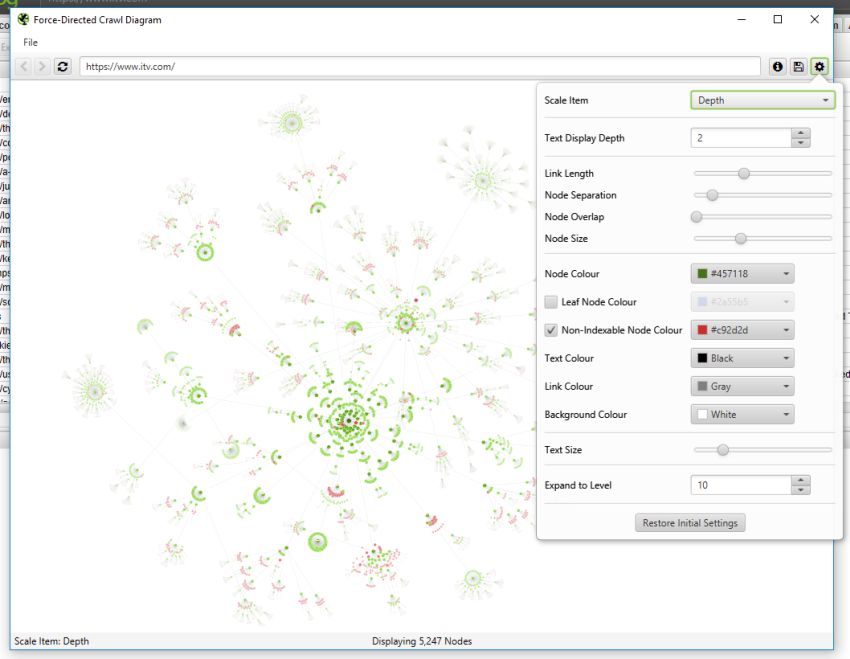
そのため、以下のような色鮮やかなビジュアライゼーションも可能です。

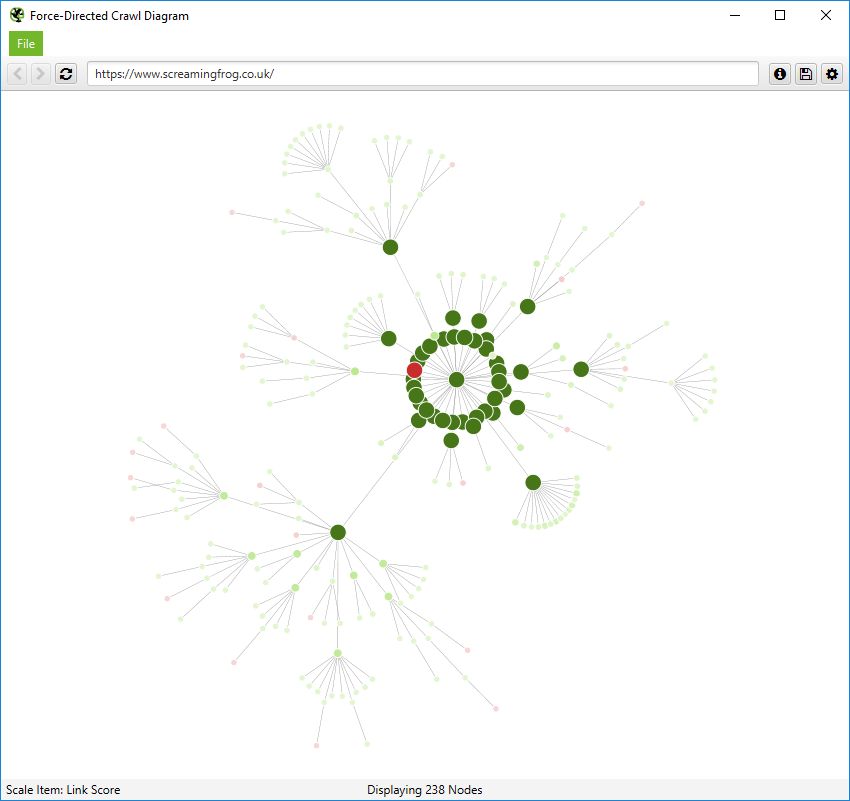
その他に、ユニークインリンク、単語数、GAセッション、GSCクリック数、リンクスコア、Mozページオーソリティなど、他の指標で視覚化を拡大し、より深い洞察を得ることができます。
ノードのサイズと色は、これらの指標に基づいて変化します。この指標は、内部リンクだけでなく、コンテンツの少ないサイトのセクションなど、さまざまなものを可視化するために役立ちます。
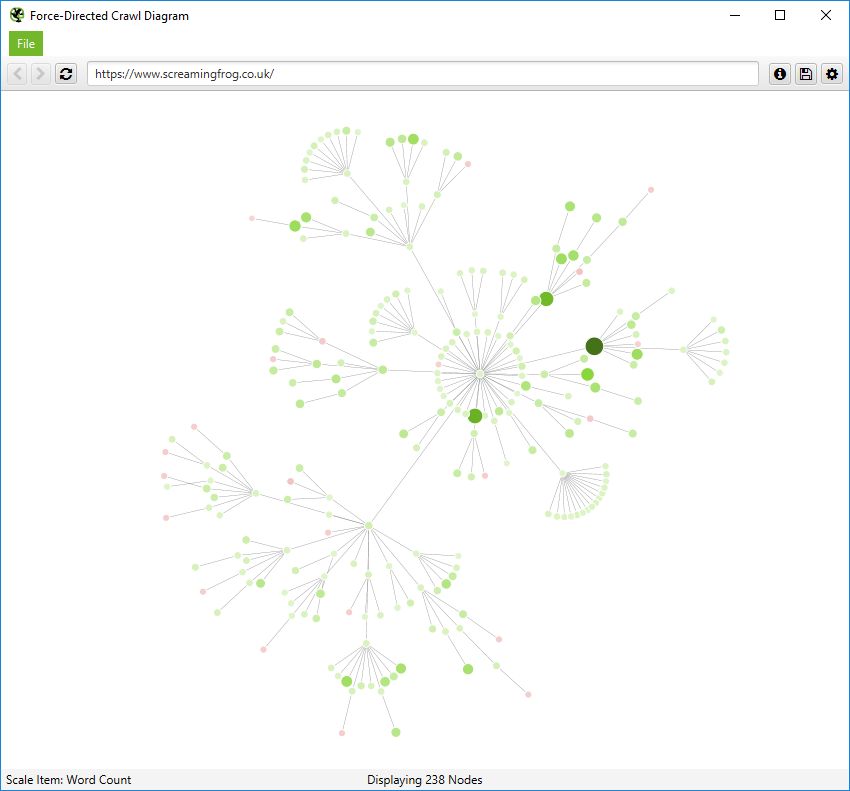
またはリンクスコアによる最高値という可視化も可能です。
さらに、内部リンクをよりシンプルなクロールツリーグラフで表示することもでき、左から右、または上から下の順に表示するように設定することが可能です。

右クリックで、サイトの特定のエリアに「フォーカス」することができます。特定のクロール深度まで拡大・縮小したり、レベルやノードの間隔を調整することもできます。
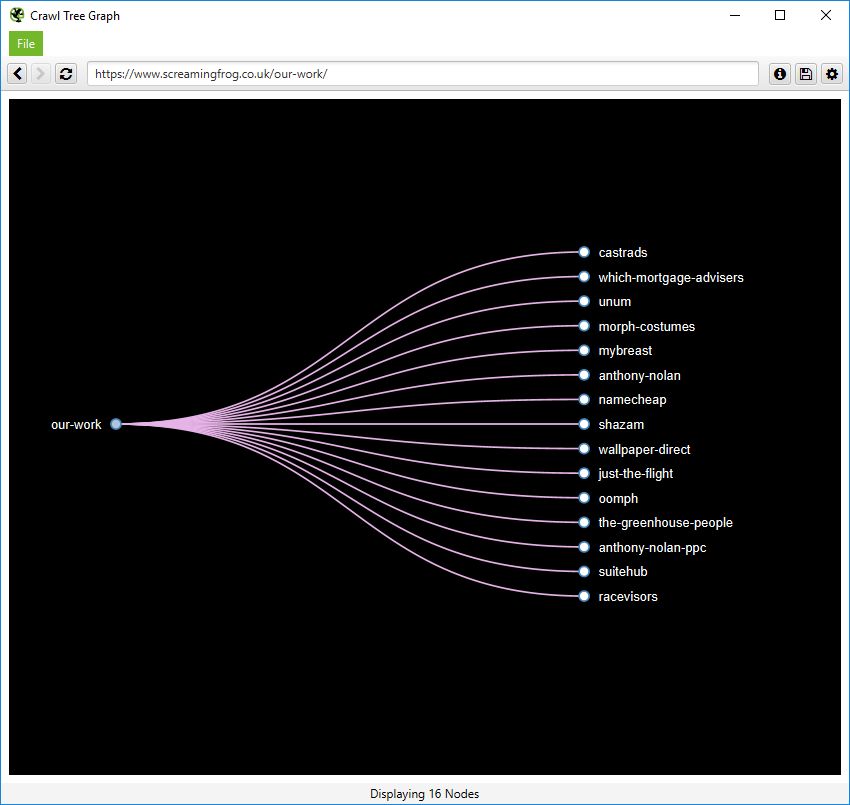
Like the force-directedと同様に、全ての色を調整することも可能です。
ディレクトリツリーのビジュアライゼーション
ディレクトリツリーのビジュアライゼーションには、「Force-Directed Directory Tree Diagram」と「Directory Tree Graph」があります。
「ディレクトリツリー」ビューは、クロールの視覚化の内部リンクとは対照的に、サイトのURLアーキテクチャと、その編成方法を理解するのに役立ちます。これらのグループは、同じページテンプレートやSEOの問題を共有していることが多いので、この分析は非常に便利です。
ディレクトリツリー図は、SEOスパイダー独自のもので、(私たちのサイトのクロールでは、以前のクロール図とは全く異なることがわかります)潜在的な問題を視覚化しやすくなっています。

インデックスを持たない赤いノード(インデックスされていないページ)は、同じテンプレートを持っているため一緒に整理されていますが、クロール図では全体に分散されていることに注意してください。このように表示することで、パターンが見えやすくなります。
また、単純化されたディレクトリツリーグラフの形式でも見ることができます。このグラフはインタラクティブに表示され、ここではWebサイトの一部を拡大し、トップダウン(上から下の順)で表示しています。

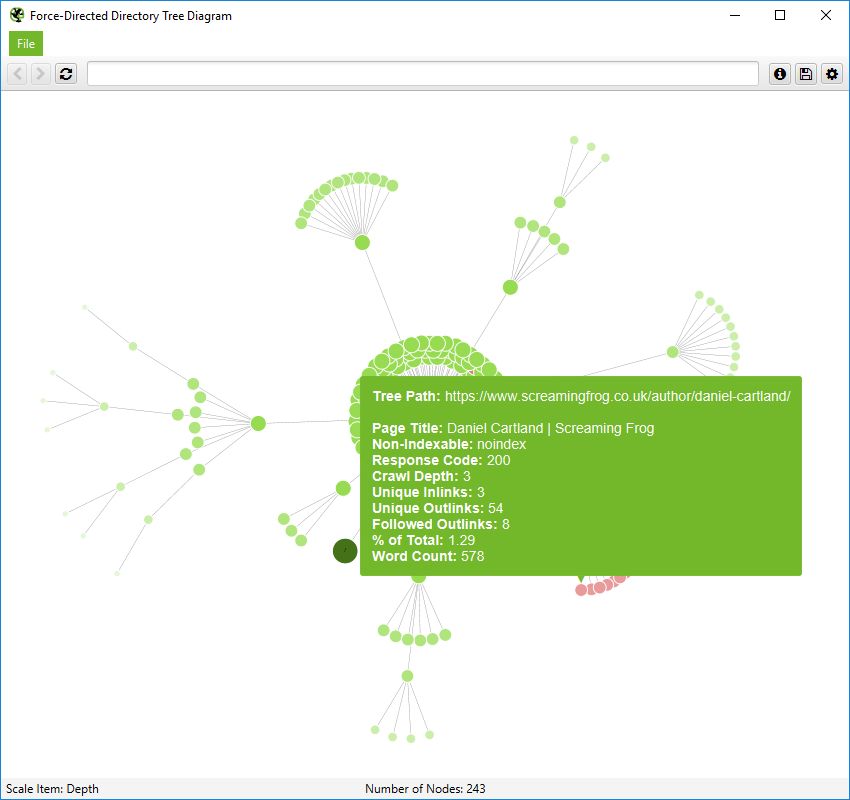
このディレクトリツリービューでは、ノードは常にURLを表すわけではないことを覚えておくことが重要です。単にパスを表すだけで、URLとして存在しないこともあります。この例として、Screaming FrogWebサイトのサブフォルダ「/author/」が挙げられます。
これは、サブフォルダ(/author/name/)に含まれるURLは存在しますが、/author/のパスそのものは存在しないのです。
しかし、ディレクトリツリービューでは、グループ化を可能にするために、これはまだ表示されています。ただし、カーソルを合わせたときに表示されるのは「パス」のみです -。
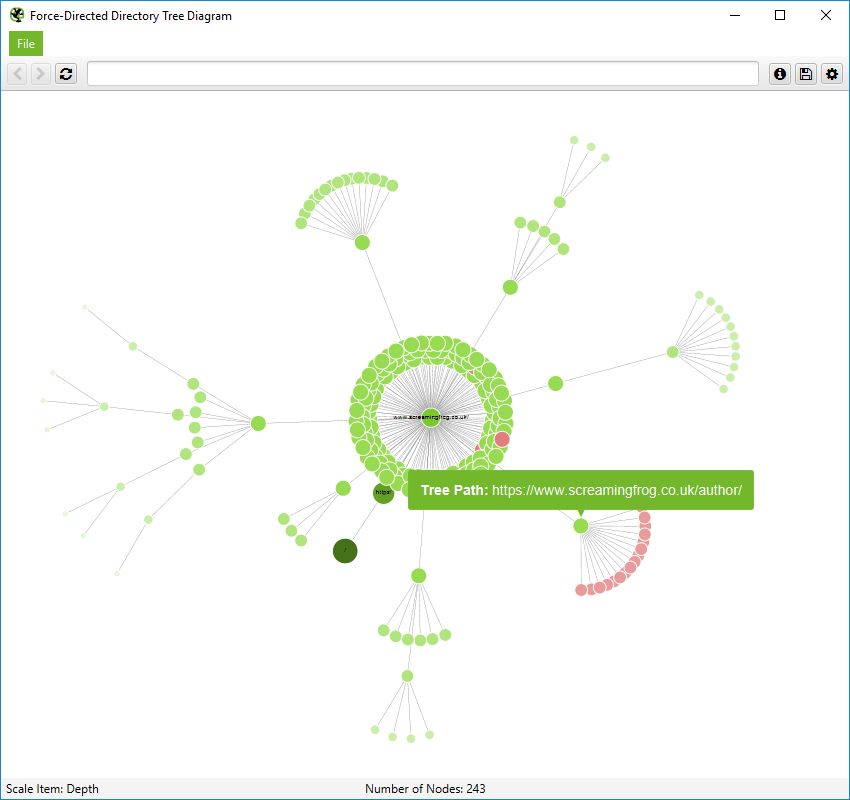
URLには、以下のような詳細な情報が含まれます。
リンクアンカーテキストとボディテキストのワードクラウド
上部のナビゲーションにあるオプションは、クロールの開始点として入力されたURLのワードクラウドを表示します。どのページの URL でもこれらを表示するには、メイン・ウィンドウで URL を右クリックして、「ビジュアライゼーション」に進みます。
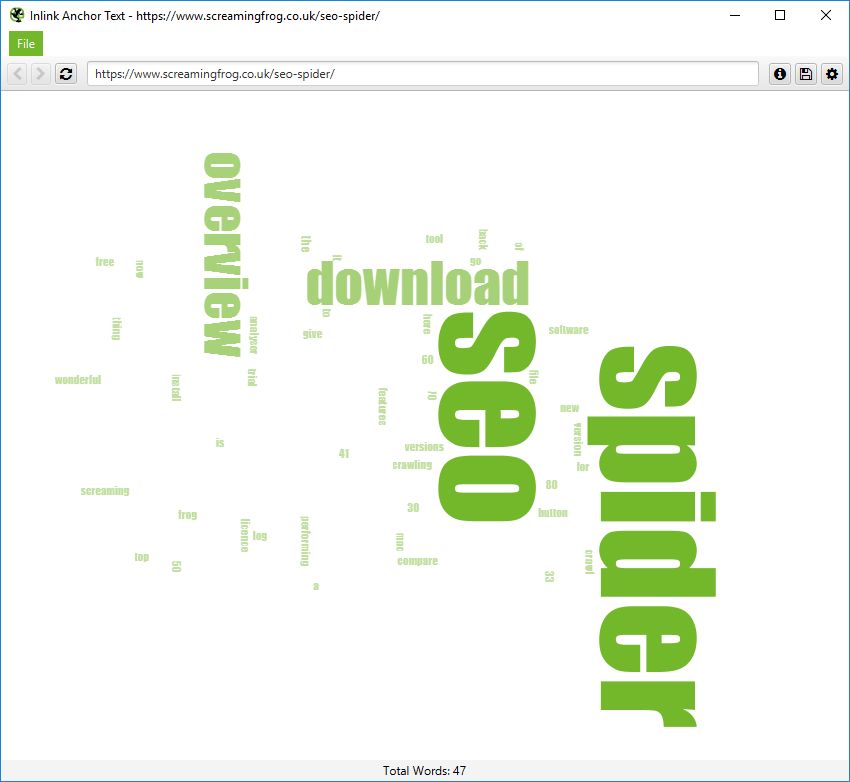
「Inlink Anchor Text Word Cloud」には、指定されたURLへの全ての内部アンカーテキストと、ページへのハイパーリンク画像のaltテキストが含まれます。
「Body Text Word Cloud」には、ページの HTML 本文に含まれる全てのテキストが含まれます。このビジュアライゼーションを表示するには、「HTMLの保存」を有効にする必要があります。
トラブルシューティング
クロール分析
SEOスパイダーは通常、実行する際にデータを分析してからレポートします。その場合は、メトリックス、タブ、フィルターはクロール中に入力されます。ただし、「リンクスコア」と一部のフィルターは、クロールの終了時(またはクロールを停止した時)に計算する必要があります。
「crawl analysis(クロール解析)」を必要とする項目の全リストは、以下の「Crawl Analysis > Configure(クロール解析 > 設定)」で見ることができます。
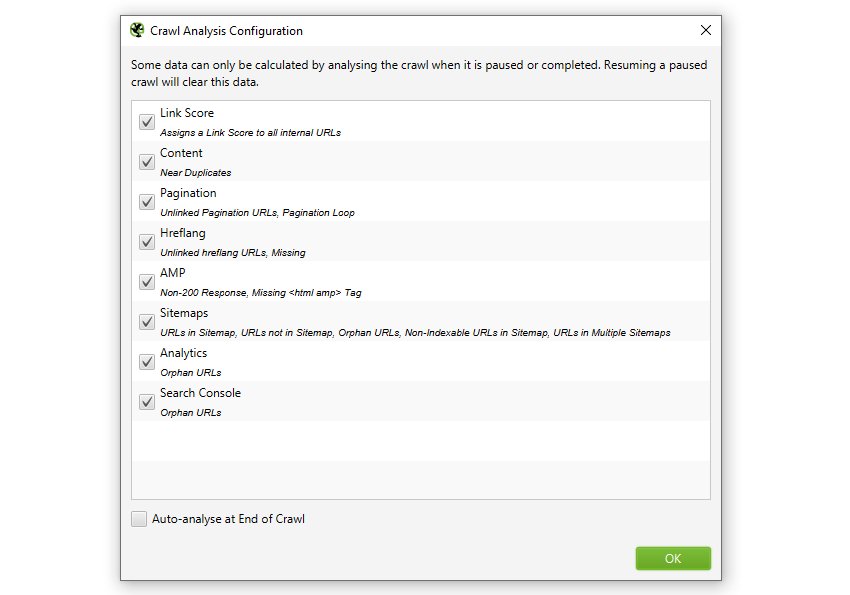
「Link Score(リンクスコア)」はメトリックであり、「Internal(内部)」タブの列として表示されることを除けば、上記は全てそれぞれのタブにあるフィルターです。
右側の「overview(概要)」ウィンドウペインでは、ポスト「crawl analysis(クロール分析)」を必要とするフィルターには、「Crawl Analysis Required(クロール分析)が必要」というマークが表示され、より分かりやすくなっています。特に「Sitemaps」フィルターは、ほとんどがクロール後の解析が必要です。
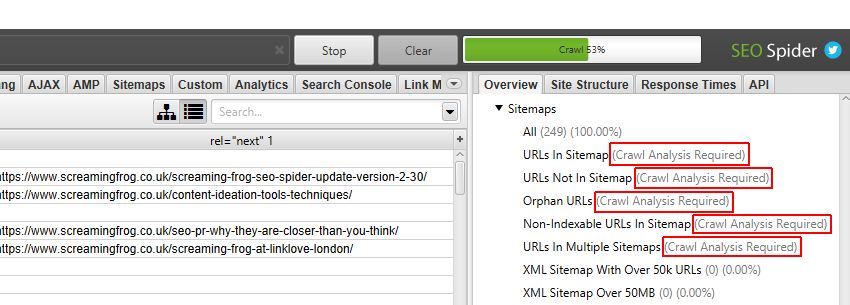
また、メインウィンドウペインでは、
You need to perform crawl analysis for this tab to populate this filter
(このフィルタを設定するには、このタブに対してクロール解析を実行する必要があります)」
と表示されます。

この解析は、「Configure(設定)」の「Auto Analyse At End of Crawl(クロール終了時の自動解析)」チェックボックスをオンにすることで、クロールの終了時に自動的に実行することも、ユーザーが手動で実行することも可能です。
クロール解析を実行するには、「Crawl Analysis > Start(クロール解析 > 開始)」をクリックするだけです。

クロール解析が実行されると、「analysis(解析)」というプログレスバーに完了のパーセンテージが表示されます。この間、SEOスパイダーは通常通り使用できます。

クロール解析が終了すると、「Crawl Analysis Required(クロール解析が必要)」とマークされた空のフィルターに、たくさんの素敵なインサイトデータが入力されます。
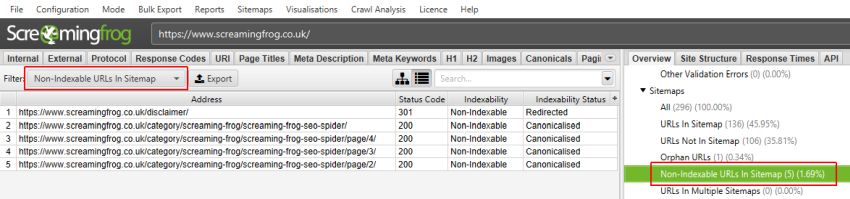
注意 – AnalyticsとSearch Consoleの孤児用URLフィルターは、それぞれのAPIに接続し、「general(一般)」タブで「Google Analytics/Google Search Consoleで発見された新しいURLをクロール」を選択した場合のみ表示されます。それ以外の場合は、「Reports > Orphan Pages(レポート > 離小島のページ)」でのみ、離小島のURLを表示することができます。
詳しくは、クロール解析のビデオガイドをご覧ください。
レポート
トップレベルのナビゲーションである「reports(レポート)」からアクセスできるレポートには、さまざまな種類があります。以下のようなものがあります。
クロールの概要レポート
このレポートは、遭遇したURLの数、robots.txtによってブロックされたURL、クロールされた数、コンテンツタイプ、レスポンスコードなどのデータを含む、クロールの概要を提供します。各タブおよび各フィルター内の数値のトップレベルのサマリーが表示されます。
「total URI description」は、混乱を避けるために、個々の行の「Total URI」列番号が何であるかという情報を提供します。
全てのリダイレクト、リダイレクトチェーン、リダイレクト&カノニカルチェーンレポート
これらのレポートは、Webサイト上で発見されたリダイレクトと、そのソースURLの詳細を示します。

「スパイダーモード(モード > スパイダー)では、これらのレポートは、シングルホップから上の全てのリダイレクトを表示します。「リダイレクトの数」と「チェーンの種類」(HTTPリダイレクト、JavaScriptリダイレクト、Canonicalなど)をカラムで表示します。また、リダイレクトループのフラグも立てます。レポートが空の場合は、短縮可能なループやリダイレクトチェーンがないことを意味します。
「All Redirects」, 「Redirect chains」,「Redirect & canonical chains」 レポートは、全てリストモード (Mode > List) で使用することも可能です。リストで提供される全ての URL の行が表示されます。「Always follow redirects(常にリダイレクトに従う)」と 「always follow canonicals(常にカノニカルに従う)」オプションにチェックを入れると、SEOスパイダーはリストモードでリダイレクトと正規表現をクロールし続け、クロールの深さを無視します。サイト移行時のリダイレクトの監査については、こちらのガイドをご覧ください。
注意 – 部分的なクロールしか行っていない場合、または一部のURLが robots.txt でブロックされている場合、このレポート内の URL に対する全てのレスポンスコードを受信できないことがあります。
カノニカルレポート
「Canonical Chains(カノニカルチェーン)」と「Non-Indexable Canonicals(Noindexカノニカルチェーン)」レポートは、クロール内の正規リンク要素やHTTP canonicalsの実装に関するエラーや問題点を明らかにします。ステップバイステップのガイドについては、「Canonicalの監査方法」を参照してください。
「Canonical Chains(カノニカルチェーン)」レポートは、2つ以上の正規化チェーンがあるURLを強調表示します。これは、あるURLが別の場所に正規のURLを持ち(「正規化」され)、そのURLがまた別のURLに正規のURLを持つ(正規化の連鎖)ことを意味します。
A→正規化→B→正規化→C
「Non-Indexable Canonicals(Noindexカノニカルチェーン)」レポートは、カノニカルのエラーや問題を明らかにします。特に、このレポートでは、応答がない、robots.txt でブロックされている、3XX リダイレクト、4XX または 5XX エラー(200 ‘OK’ 応答以外のもの)がある canonical が表示されます。
A→正規化→B→3XXリダイレクト→C
このレポートでは、canonicalを介してのみ検出され、サイトからリンクされていないURLのデータも提供されます(「true」の場合は「unlinked」列)。
ページネーションレポート
Hreflangレポート
Hreflangレポートは、Webサイト上で発見されたhreflangの実装に関連しています。ステップバイステップのガイドについては、How To Audit Hreflangをお読みください。
データを一括でエクスポートできるhreflangレポートは7種類あり、以下のようなものがあります。
- All Hreflang URLs:これは、クロールで発見された地域と言語の値を含む全てのURLとhreflang URLsの1:1のレポートです。
- 200以外のHreflang URL:このレポートは、hreflangアノテーションの中で、200レスポンス(レスポンスなし、robots.txtでブロック、3XX、4XX、5XXレスポンス)でない全てのURLを表示します。
- Unlinked Hreflang URLs:このレポートは、サイト上のハイパーリンクを介してリンクされていない全てのhreflang URLを表示します。
- Missing Confirmation Links:このレポートは、確認リンクがないページ、およびどのページが確認されていないかを示します。
- Inconsistent Language Confirmation Links:このレポートは、同じページに対して異なる言語コードを使用している確認ページを表示します。
- Non Canonical Confirmation Links:このレポートは、正規化されていないURLへの確認リンクを表示します。
- Noindex Confirmation Links:このレポートは、noindex URLへの確認リンクを表示します。
インセキュアコンテンツレポート
安全でないコンテンツのレポートでは、安全でない要素(内部 HTTP リンク、画像、JS、CSS、SWF、CDN 上の外部画像、ソーシャルプロファイルなど)を持つ安全な(HTTPS) URL が全て表示されます。Webサイトを非セキュア(HTTP)からセキュア(HTTPS)に移行する際、全ての安全でない要素をピックアップすることは困難で、ブラウザで警告が表示されることがあります 。
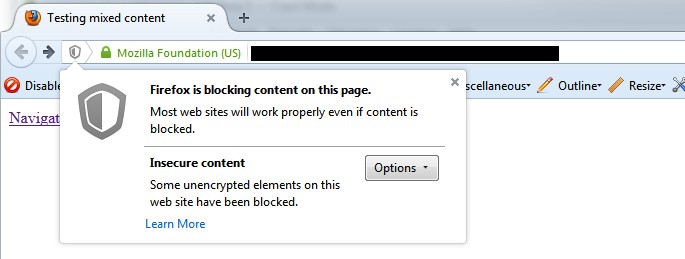
以下は、レポートの簡単な例です(この場合、安全でない画像です)。

SERPサマリーレポート
このレポートでは、URL、ページタイトル、メタディスクリプションを、それぞれの文字数やピクセル幅とともに素早くエクスポートすることができます。
このレポートは、SEOスパイダーに「SERP」モードで再アップロードするためのテンプレートにも使用できます。
オーファン・ページ・レポート
orphan pagesレポートは、Google Analytics API、Google Search Console (Search Analytics API)、XML Sitemapから収集したURLのうち、クロール内で発見されたURLとマッチングしなかったものをリストアップしたものです。
このレポートは、Google Analytics、Search Consoleに接続しているか、XML Sitemapをクロールしてデータを取り込むように設定していない限り、空白になります。
離小島のページのURLはSEOスパイダーで直接見ることもできますが、正しい設定が必要です。離小島のページを見つける方法についてのガイドを読むことをお勧めします。
離小島ページレポートの「ソース」列は、URLが発見されたものの、クロールでURLとマッチしなかったソースを正確に示しています。これには以下が含まれます。
- GA:URLは、Google Analytics APIを介して発見されました。
- GSC:Google Search Consoleで、Search Analytics APIによって、URLが発見されました。
- サイトマップ:このURLはXMLサイトマップによって発見されました。
- GA & GSC & Sitemap:URLはGoogle Analytics、Google Search Console、XML Sitemapで発見されました。
このレポートには、GoogleAnalyticsの連携で選択したクエリに対して、Google Analyticsが返したあらゆるURLを含めることができます。
したがって、ログインエリアやショッピングカートのURLも含まれます。SEOにとって最も有益なデータは、ランディングページのパスディメンションと「オーガニックトラフィック」セグメントを照会することで返されることがよくあります。このクエリによって、以下のことが確認できます。
- Orphan Pages:Webサイトの内部でリンクされていないが、存在するページです。古いページ、古いサイトの移行で見落とされたページ、外部で見つかったページ(外部リンクや参照サイト経由)などが該当する可能性があります。このレポートでは、リストをブラウズして、どれが関連性があるか確認し、リスト・モードを使ってアップロードすることができます。
- Errors:レポートには、404エラーが含まれることがあり、URL内に参照元Webサイトが含まれることもあります(この場合は、「全てのトラフィック」セグメントが必要です)。これは、外部リンクを修正するためにWebサイトを追跡する、または単に正しいページに、エラーのURLを301リダイレクトするのに便利です。このレポートには、正規化されていたり、robots.txtによってブロックされているURLも含まれますが、実際にはまだインデックスされ、トラフィックを配信しています。
- GA or GSC URL Matching Problems:データがクロールのURLに対してマッチしない場合、GAまたはGSC APIを介してどのようなURLが返されているかを確認することができます。これは、特定のGoogle Analyticsビューの問題、例えば’拡張URL’ハックなどのURLのフィルタリングなどを強調する可能性があります。SEOスパイダーがクロールされたURLに対してデータを返すには、URLが一致する必要があります。そのため、何も手を加えていない’生の’GAビューに変更することが有効かもしれません。
構造化データレポート
「Validation Errors & Warnings Summary」レポートは、発見された固有の検証エラーと警告に構造化データを集約し、各問題によって影響を受けたURLの数を、特定の問題を持つサンプルURLとともに表示します。レポートの例を以下に示します。

ページスピードレポート
PageSpeedのレポートは、それぞれの意味をカバーするPageSpeedタブで概説されたフィルタに関連しています。これらのレポートは、速度の機会または診断とページとそれらの特定のリソースをエクスポートする方法を提供します。これらは、PageSpeed Insightsの統合をセットアップして接続する必要があります。
HTTPヘッダーサマリーレポート
クロール中に発見された全てのHTTPレスポンスヘッダを集約したビューを表示します。HTTPレスポンスヘッダと、そのヘッダで応答した個別URLの数が表示されます。
HTTPヘッダーを「Config > Spider > Extraction(設定 > Spider > 抽出)」で抽出するように設定する必要があります。
URLとヘッダーのより詳細な情報は、下のウィンドウの「HTTP Headers(HTTPヘッダー)」タブ、および「Bulk Export > Web > All HTTP Headers(一括エクスポート > Web > 全てのHTTPヘッダー)」エクスポートで確認できます。
また、HTTPヘッダーはInternalタブで照会することも可能で、その場合は一意のカラムに追加されます。
クッキーサマリーレポート
これは、クロール中に発見された個別クッキーを、その名前、ドメイン、有効期限、セキュア、HttpOnlyの値を考慮して集約して表示するものです。
それぞれの個別クッキーが発行された URL の数も表示されます。クッキーの値そのものは、この集計では割引かれます(個別なので!)。
この設定を行うには、「Config > Spider > Extraction(設定 > スパイダー > 抽出)」で’Cookies‘の抽出を有効にする必要があります。また、JavaScriptやピクセル画像タグを使用してページに読み込まれたクッキーを正確に表示するには、JavaScriptレンダリングモードを設定する必要があります。
この集計されたレポートは、GDPR(個人データ保護やその取り扱いについて詳細に定められたEU域内の各国に適用される法令)に極めて有用です。URLとそこで見つかったCookieのより詳細な情報は、下のウィンドウの「Cookies」タブ、および「Bulk Export > Web > All Cookies(一括エクスポート > Web > 全てのクッキー)」エクスポートで見ることができます。
クロールパスレポート
このレポートは、トップレベルメニューの「レポート」ドロップダウンではなく、トップウィンドウ画面でURLを右クリックし、「エクスポート」オプションを選択することで利用できます。例えば、以下のようになります。
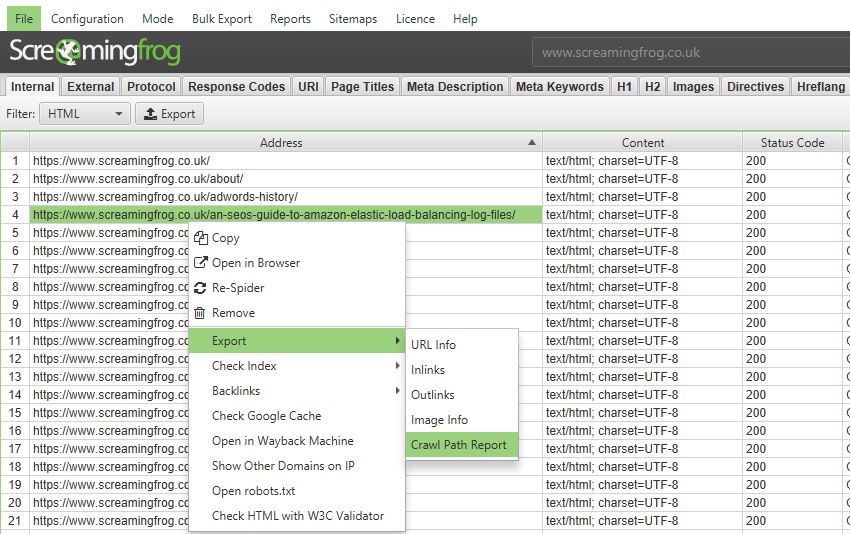
このレポートは、SEOスパイダーがURLを発見するためにクロールした最短経路を示します。
これは、元のソースURLを発見するために多くのURLの「inlinks(内部リンク)」を見るのではなく、深いページにとても便利です(例えば、カレンダーによる無限URLの場合など)。
クロールパスレポートは、下から上へ読むようにします。「source(ソース)」列の一番下にある最初のURLは、一番最初にクロールされたURLです(レベルは’0’)。「destination(リンク先)」は、次にクロールされたURLを示しており、これらが次のレベル(1)の次の「source(ソース)」URLを構成し、さらに上へ上へと続きます。
レポートの一番上にある最終的な「リンク先」URLは、クロールパスレポートのURLとなります。
コマンドラインインターフェイスのセットアップ
もしユーザーインターフェースの実行を一切許可しないプラットフォームで実行している場合は、コマンドライン経由でSEOスパイダーを実行する前に、このガイドの指示に従ってください。
ユーザーインターフェイスを実行できる場合は、コマンドラインで実行する前に実行するようにしてください。これにより、エンドユーザーライセンス契約(EULA)に同意し、ライセンスキーを入力し、ストレージモードを選択することができます。
初期実行を行うためにユーザーインターフェースを利用できない場合、いくつかの設定ファイルを編集する必要があります。これらの場所は、プラットフォームによって異なります。
C:\Users³.ScreamingFrogSEOSpider~/.ScreamingFrogSEOSpider/~/.ScreamingFrogSEOSpider/以降、これを.ScreamingFrogSEOSpiderディレクトリと呼ぶことにします。
ライセンスキーの入力
あなたの.ScreamingFrogSEOSpiderディレクトリにlicence.txtというファイルを作成します。1行目にライセンスユーザー名、2行目にライセンスキーを入力(タイプミスを防ぐためコピー&ペースト)し、ファイルを保存してください。
EULAに同意する
.ScreamingFrogSEOSpiderディレクトリにspider.configファイルを作成または編集します。以下の行を探し、編集または追加します。
eula.accepted=11ファイルを保存して終了します。
ストレージモードの選択
初期設定のストレージモードはメモリです。もしメモリストレージを使用したい場合は、何も変更する必要はありません。データベースストレージに変更するには、.ScreamingFrogSEOSpiderディレクトリのspider.configを編集してください。
storage.mode プロパティを追加または編集して、次のようにします。
storage.mode=DB初期設定のパスは、あなたの.ScreamingFrogSEOSpiderディレクトリのdbというディレクトリです。これを変更したい場合は、storage.db_dirプロパティを追加または編集してください。OSによっては、パスの入力が異なります。
storage.db_dir=C\:\\Users\\USERNAME\\dbfolderstorage.db_dir=/Users/USERNAME/dbfolderstorage.db_dir=/home/USERNAME/dbdirエンベデッドブラウザを無効にする
embeddedBrowser.enable=falseメモリ割り当て
SEOスパイダーのインターフェースから、「Configuration > System > Memory(設定 > システム > メモリ)」でメモリ割り当てを変更することをお勧めします。設定後、CLIでSEOスパイダーを起動してください。
しかし、本当にヘッドレスで(モニタを付けずに)動作しているユーザは、Linuxベースのオペレーティングシステムで動作している傾向があります。ですから、Linuxオペレーティングシステムでこれを設定するには、ホームディレクトリ(すなわち「~/.screamfrogseospider」)に「.screamfrogseospider」という名前のファイルを修正するか作成する必要があります。
以下の行を適宜追加・修正してください(8GB構成の場合を示します)。
-Xmx8gAPIへの接続
API を利用するには、CLI を使用する前に、ユーザー インターフェイスを使用して認証情報をセットアップし、認証することを推奨します。
しかし、ユーザー・インターフェースが利用できない場合、APIによっては、別のマシンで設定した必要なフォルダーをコピーしたり、spider.configファイルを編集することで利用することが可能です。
Google AnalyticsとGoogle Search Consoleは、OAuthの関係でユーザーインターフェースによる接続と認証が必要です。そのため、SEOスパイダーのインターフェイスを利用できる別のマシンで設定する必要があります。一度認証されれば、ユーザーインターフェイスが利用できないマシンに認証情報をコピーすることができます。
ローカルのScreaming Frog SEOスパイダーのユーザーフォルダに移動してください。
C:\Users\USERNAME\.ScreamingFrogSEOSpider\~/.ScreamingFrogSEOSpider/~/.ScreamingFrogSEOSpider/そして、「analytics」 と 「search_console」フォルダをコピーしてください。

そして、ユーザーインターフェースのないマシンのScreaming Frog SEOスパイダーのユーザーフォルダにそれらを貼り付けます。その後、以下のコマンドで通常通りCLIを使用してAPIを利用することができます。
クロール時にGoogle AnalyticsのAPIを使用する。
--use-google-analytics "google account" "account" "property" "view" "segment"クロール時にGoogle Search ConsoleのAPIを使う。
--use-google-search-console "google account" "website"PSI、Ahrefs、Majestic、Mozの場合、いずれも「spider.config」ファイルを編集し、それぞれのAPIキーで更新する必要があります。spider.configファイルは、上記のようにScreaming Frog SEOスパイダーのユーザーフォルダ内にあります。
各APIを利用するには、該当するAPI行を貼り付け、「APIKEY」を各プロバイダが提供するAPIキーに置き換えるだけです。
PSI.secretkey=APIKEYahrefs.authkey=APIKEYmajestic.authkey=APIKEYmoz.secretkey=APIKEYその後、通常通りCLIを使用して、以下のコマンドでAPIを利用することができます。
--use-pagespeed--use-ahrefs--use-majestic--use-mozscapeGoogle Driveへの書き出し
CLI で Google Drive エクスポートを使用するには、他の API と同様に適切な認証情報が必要です。
これらの認証情報は、ユーザーインターフェースを通じて、または上記のように他のマシンから「google_drive」フォルダをコピーすることによって認証することができます。
クロールを設定する
機能または設定オプションが特定のコマンドラインオプションとして利用できない場合(除外設定や JavaScriptレンダリングなど)、ユーザーインターフェースを使用して希望する設定を正確に行い、設定ファイルを保存する必要があります。
そして、CLIを使用する際にその設定ファイルを提供することで、それらの機能を利用することができます。
ユーザーインターフェースが利用できない場合、まず利用可能なマシンで設定ファイルをセットアップし、保存した.seospiderconfigファイルを転送し、コマンドラインから供給することをお勧めします。supercool-config.seospiderconfigのコマンドラインは次のようになります。
--config "C:\Users\Your Name\Desktop\supercool-config.seospiderconfig"コマンドラインインターフェース
SEOスパイダーは全てコマンドラインで操作できます。
これには、起動、完全な設定、保存、ほぼ全てのデータのエクスポート、レポート作成が含まれます。また、SEOスパイダーはCLIを使ってヘッドレスで実行することもできます。
本書では、対応する3つのOSのコマンドラインの使用方法と、使用できる引数を簡単に説明します。
Windows
macOS
Linux
コマンドラインオプション
トラブルシューティング
Windows
コマンドプロンプトを開きます(スタートボタンから「cmd」と入力するか、プログラムとファイルから「Windowsコマンドプロンプト」を検索します)。SEOスパイダーのディレクトリ(64ビット)に移動します。
cd "C:\Program Files (x86)\Screaming Frog SEO Spider"あるいは32bitの場合。
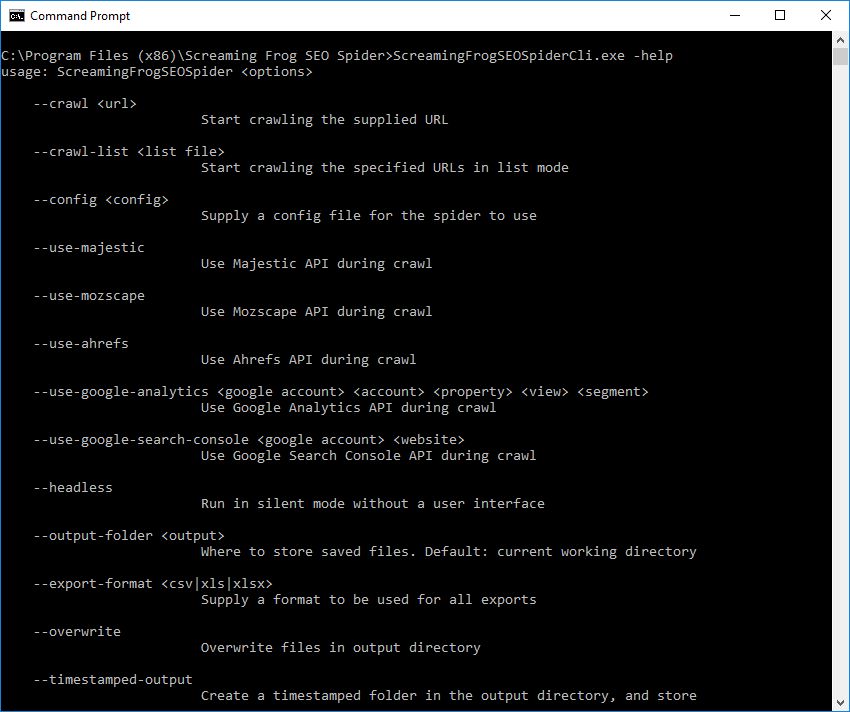
cd "C:\Program Files\Screaming Frog SEO Spider"Windowsでは、ScreamingFrogSEOSpiderCli.exeというSEOスパイダーの別ビルドがあります(通常のScreamingFrogSEOSpider.exeではありません)。これはWindowsのコマンドラインから実行することができ、典型的なコンソールアプリケーションのように動作します。次のように入力します。
ScreamingFrogSEOSpiderCli.exe --help全ての引数を表示し、全てのログがCLから出力されるのを見るにはまた、次のように入力することもできます。
–-help export-tabs, –-help bulk-export, –-help save-report, or –-help export-custom-summary各エクスポートタイプで利用可能な引数の全リストを見るには、こちらをご覧ください。
自動でクロールを開始するには
ScreamingFrogSEOSpiderCli.exe --crawl https://www.example.com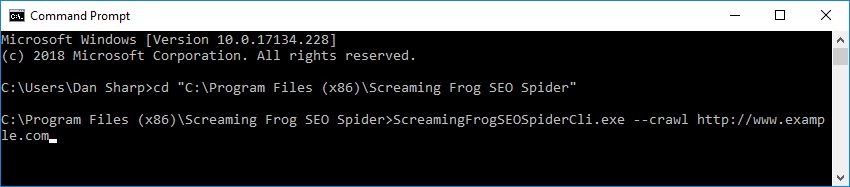
その場合、追加の引数は単にスペースで追加することができる。
例えば、以下のようにすると、SEOスパイダーがヘッドレスで動作し、クロールを保存し、デスクトップに出力し、内部コードタブとレスポンスコードタブ、クライアントエラーフィルターをエクスポートすることになります。
ScreamingFrogSEOSpiderCli.exe --crawl https://www.example.com --headless --save-crawl --output-folder "C:\Users\Your Name\Desktop" --export-tabs "Internal:All,Response Codes:Client Error (4xx)"
保存したクロールをロードするには?
ScreamingFrogSEOSpiderCli.exe --headless --load-crawl "C:\Users\Your Name\Desktop\crawl.dbseospider"クロールは.seospiderまたはdbseospiderのいずれかのファイルでなければなりません。
クロールを読み込むだけでは意味がないので、データをエクスポートするには、次のように追加の引数が必要です。「内部」タブをデスクトップにエクスポートします。
ScreamingFrogSEOSpiderCli.exe --headless --load-crawl "C:\Users\Your Name\Desktop\crawl.dbseospider" --output-folder "C:\Users\Your Name\Desktop\" --export-tabs "Internal:All"
SEOスパイダーの引数として指定できるコマンドラインオプションの一覧はこちらをご覧ください。
MacOS
アプリケーションフォルダ内のユーティリティフォルダにあるターミナルを開くか、スポットライトを使って直接「Terminal」と入力します。
コマンドラインからSEOスパイダーを起動するには、2つの方法があります。openコマンドを使うか、ScreamingFrogSEOSpiderLauncherスクリプトを使うか、どちらかです。openコマンドはすぐに復帰し、ターミナルを閉じることができます。
ScreamingFrogSEOSpiderLauncherは、SEOスパイダーが終了するまでターミナルにログを残し、ターミナルを閉じるとSEOスパイダーが終了します。
open "/Applications/Screaming Frog SEO Spider.app"/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher --help
以下の例では、両方の方法でSEOスパイダーを起動する方法を示しています。
open "/Applications/Screaming Frog SEO Spider.app" --args /tmp/crawl.seospider/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher /tmp/crawl.seospideropen "/Applications/Screaming Frog SEO Spider.app" --args --headless --load-crawl "C:\Users\Your Name\Desktop\crawl.dbseospider" --output-folder "C:\Users\Your Name\Desktop\" --export-tabs “Internal:All”/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher --headless --load-crawl "/Users/Your Name/Desktop/crawl.dbseospider" --output-folder "/Users/Your Name/Desktop" --export-tabs "Internal:All"open "/Applications/Screaming Frog SEO Spider.app" --args --crawl https://www.example.com//Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher --crawl https://www.example.com/ヘッドレスを開始するには、すぐにクロールを開始し、Internal->AllとResponse Codes->Client Error (4xx) フィルターと一緒にクロールを保存します。
open "/Applications/Screaming Frog SEO Spider.app" --args --crawl https://www.example.com --headless --save-crawl --output-folder /tmp/cli --export-tabs "Internal:All,Response Codes:Client Error (4xx)"/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher --crawl https://www.example.com --headless --save-crawl --output-folder /tmp/cli --export-tabs "Internal:All,Response Codes:Client Error (4xx)"SEOスパイダーの引数として指定できるコマンドラインオプションの一覧はこちらをご覧ください。
Linux
このscreamfrogseospiderのバイナリはインストール時にあなたのパスに置かれます。これを実行するには、ターミナルを開いて、以下の例に従ってください。
screamingfrogseospiderscreamingfrogseospider /tmp/crawl.seospiderscreamingfrogseospider --help
screamingfrogseospider --crawl https://www.example.com/ヘッドレスで開始するには、すぐにクロールを開始し、
Internal->All と Response Codes->Client Error (4xx) のフィルタとともにクロールを保存します。
screamingfrogseospider --crawl https://www.example.com --headless --save-crawl --output-folder /tmp/cli --export-tabs "Internal:All,Response Codes:Client Error (4xx)"保存されたクロールファイルをロードして「’Internal(内部)」タブをデスクトップにエクスポートするには?
screamingfrogseospider --headless --load-crawl ~/Desktop/crawl.seospider --output-folder ~/Desktop/ --export-tabs "Internal:All"Linux でヘッドレスに JavaScript レンダリングを利用するためには、ディスプレイが必要です。Virtual Frame Bufferを使用することで、ディスプレイが接続されている状態をシミュレートすることができます。コマンドラインオプションの全リストは以下をご覧ください。
コマンドラインオプション
SEOスパイダーの引数として利用できるコマンドラインオプションの完全なリストは、アプリの–helpを使用して、以下のリストと同様にご覧ください。
各エクスポートタイプで利用可能な引数の完全なリストを表示するには、「–help export-tabs」「–help bulk-export」「–help save-report」「–help export-custom-summary」を指定してください。
--crawl https://www.example.com--crawl-list "list file"(例: -load-crawl “C:\UsersYour Name</Desktop)
--load-crawl "crawl file"(例: -config “C:\Users)
--config "config"(例:-auth-config “C:\UsersYour Name﹑Supercool-auth-config.seospiderauthconfig”)
--auth-config "authconfig"--headless--save-crawl(例: -output-folder “C:\UsersYour NameDesktop”)
--output-folder "output"--overwriteデータベース保存モードでクロールを保存する際のプロジェクト名と、Google Driveのフォルダ名に使用するプロジェクト名を設定します。エクスポートは初期設定で「Screaming Frog SEOスパイダー」のGoogle Driveディレクトリに保存されますが、この引数を使用すると「Screaming Frog SEO Spider > Project Name(Screaming Frog SEOスパイダー > プロジェクト名)」内に保存されることになります。例:-project-name “Awesome Project”.
--project-name "Name"データベース保存モードでクロール名として使用するタスク名を設定します。これは、プロジェクトフォルダの子であるGoogle Driveのフォルダとしても使用されます。例えば、プロジェクト名を指定すると「Screaming Frog SEO Spider > Project Name > Task Name(’Screaming Frog SEOスパイダー > プロジェクト名 > タスク名)」となります。例:-task-name “Awesome Task”
--task-name "Name"出力ディレクトリにタイムスタンプフォルダを作成し、全ての出力をそこに格納します。Google Driveにもタイムスタンプ付きのディレクトリが作成されます。
--timestamped-outputエクスポートするタブとフィルタのリストをカンマ区切りで指定します。タブ名とフィルター名はコロンで区切って指定します。タブ名はユーザーインターフェースに表示されているものをそのまま使用します。例:Meta Description:Over X Characters.例:-export-tabs “Internal:All”。
--export-tabs "tab:filter,..."実行する一括エクスポートをカンマで区切ったリストで指定します。エクスポート名は、UI の一括エクスポートメニューと同じです。サブメニューのエクスポートにアクセスするには、「サブメニュー名:エクスポート名」を使用します。例:-bulk-export “Response Codes:Client Error (4XX) Inlinks”
--bulk-export "submenu:export,..."保存するレポートのコンマ区切りリストを指定します。レポート名は、UI の[レポート]メニューと同じです。サブメニューのレポートにアクセスするには、「サブメニュー名:レポート名」を使用します。例:-save-report “Redirects:All Redirects”
--save-report "submenu:report,..."自動化されたData Studioクロールレポートの「Export For Data Studio(データスタジオへ抽出)」 Custom Crawl Overviewレポートに項目のカンマ区切りリストを指定します。
カスタムクロール概要の設定可能なレポート項目は、CLIでは「-help export-custom-summary」で確認でき、英語版ではスケジューリングUIでも同じ名前になります。これには、Google Driveのアカウントも使用する必要があります。(例:-export-custom-summary “Site Crawled,Date,Time” -google-drive-account “yourname@example.com”)
--export-custom-summary "item 1,item 2,item 3..."--create-sitemap--create-images-sitemap(例: -export-format csv)
--export-format csv xls xlsx gsheet(例:-google-drive-account “yourname@example.com”)
--google-drive-account "google account"(例:-use-google-analytics “yourname@example.com” “Screaming Frog” “https://www.screamingfrog.co.uk/” “All Web Site Data” “Organic Traffic”)
--use-google-analytics "google account" "account" "property" "view" "segment"(例: -use-google-analytics-4 “yourname@example.com” “Screaming Frog” “Screaming Frog – GA4” “All Data Streams “となります。)
--use-google-analytics-4 "google account" "account" "property" "data stream"(例:-use-google-search-console “yourname@example.com” “https://www.screamingfrog.co.uk/”)
--use-google-search-console "google account" "website"--use-pagespeed--use-majestic--use-mozscape--use-ahrefs--help保存された設定を使用する
もし、ある機能や設定オプションが、上記のような特定のコマンドラインオプションとして利用できない場合(除外設定や JavaScriptレンダリングなど)、ユーザーインターフェースを使用して、希望する設定を正確に行い、設定ファイルを保存する必要があります。
保存した設定ファイルをCLIで使用する際に供給することで、それらの機能を利用することができます。
トラブルシューティング
- ヘッドレスクロールで結果のエクスポートに失敗した場合は、-output-folderが存在し、空であるか、-timestamped-outputオプションを使っていることを確認してください。
- 引用する場合は、エスケープされるため、引用の前に “second “をつけないでください。
検索機能
インターフェイスの右上にある検索ボックスで、表示されている全ての列を検索することができます。初期設定では、「Address(URL)」列の通常テキスト検索が行われますが、正規表現への切り替え、さまざまな定義済みフィルター(「正規表現に一致しない」を含む)の選択、ルールの結合(および/または)、列の選択を行うことができます。
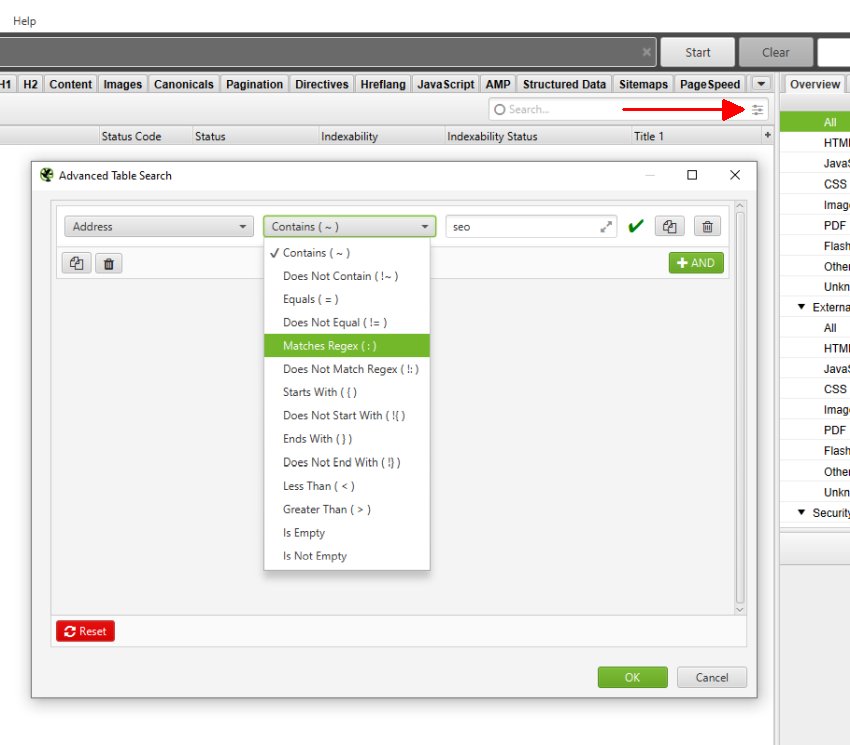
検索結果を入力後、Enterキーを押すと、一致するセルを含む行のみが表示されます。
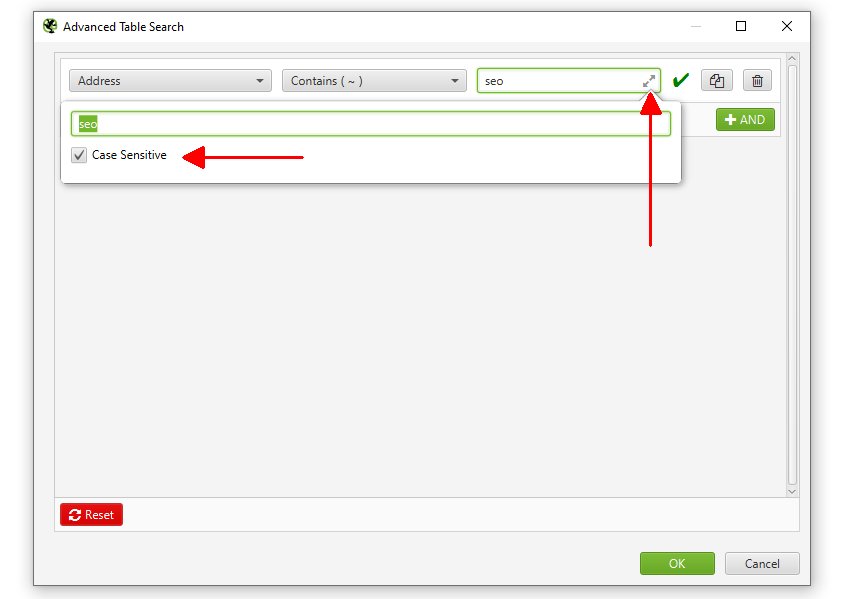
大文字と小文字を区別せずに検索したい場合は、検索クエリボックスの右側にある矢印をクリックし、「大文字と小文字を区別する」を有効にすることができます。
検索バーには、検索やフィルターシステムで使用される構文が表示されるので、これをパワーユーザーが定式化すれば、ボタンをクリックして検索を実行しなくても、一般的な検索やフィルターを素早く構築することができます。

構文は、検索ボックスに直接貼り付けたり、書き込んだりして、検索を実行するだけです。
重複する単語や繰り返される単語を検索するには、大文字と小文字を区別するキャプチャグループを使用することができます。
(keyword)(.*\1+)同じ機能を持つ追加の検索ボックスは、テーブ ルデータを含む大部分の下部のウィンドウタブで見つけることができます。
また、「ソースを見る」タブには、保存されている任意のHTMLを検索する機能があります。
ユーザーインターフェース
テーマ
SEOスパイダーには、ライトモードとダークモードの2つのテーマがあります。これは、以下の項目で変更することができます。
Configuration > User Interface > Theme(設定>ユーザーインターフェース>テーマ)
タブ
タブをマウスでドラッグ&ドロップすることで、タブの並び順を変更することができます。これは、メインウィンドウだけでなく、下のウィンドウのタブにも適用されます。

これらは、任意のタブを右クリックして「閉じる」を選ぶと隠すことができます。「他を閉じる」は選択したタブ以外の全てのタブを隠し、「全てを閉じる」は全てのタブを隠します。

タブの可視性は、タブの右側にある⌄メニューから管理することができます。

タブの表示と位置を初期設定に戻すことができます。
Configuration > User Interface > Reset Tabs(設定 > ユーザーインターフェース > タブをリセット)
カラム
列は、ドラッグ&ドロップで好きな位置に移動できます。
これらは、メインウィンドウの列行の右側にある+メニューで非表示にすることができます。
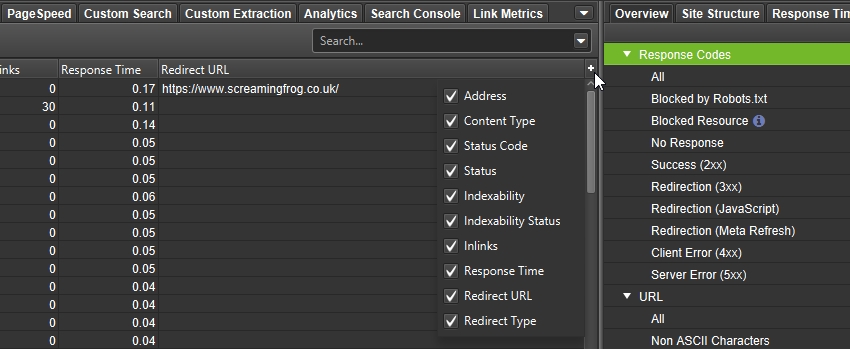
列の表示と位置は、以下の方法で初期設定に戻すことができます。
Configuration > User Interface > Reset Columns for All Tables(設定 > ユーザーインターフェイス > 全てのテーブルの列をリセット)
ペインサイズの変更
右と下のウィンドウを選択し、その間にあるペインをドラッグして好みのサイズに変更することが可能です。