

このページでは、ScreamingFrogのスパイダークロールタブの英語ページを日本語で紹介しています。
詳細は原文を確認してください。
2023年2月現在において、日本初となる『Screaming Frog SEO Spider』の日本語訳です。
Crawlタブ
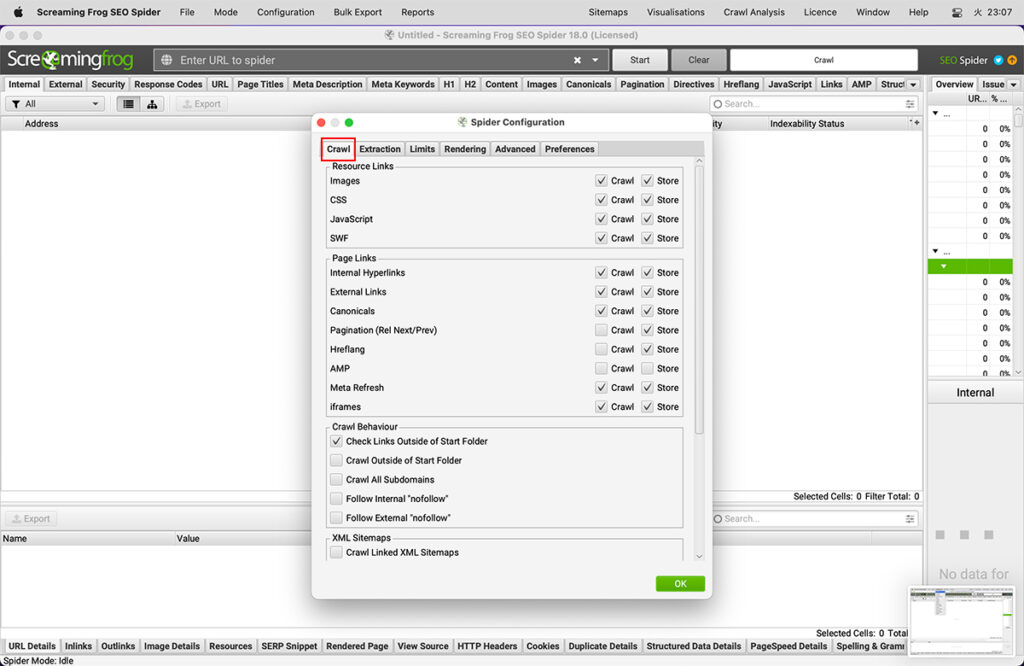
設定内にある「Crawl」タブの機能およびチェック有無の効果の違いを説明します。
画像
Configuration > Spider > Crawl > Images
(設定 > スパイダー > クロール > 画像)
画像の保存とクロールを別々に選択することができます。
「store(保存)」の設定を解除すると、img要素内の画像ファイルは保存されず、SEOスパイダーにも表示されなくなります。
<img src="image.jpg">「crawl(クロール)」の設定を解除すると、img要素内の画像ファイルは、レスポンスコードを確認するためにクロールされなくなります。
その他の方法でリンクされた画像は、アンカータグを使用するなどして保存され、クロールされます。
アンカータグでリンクされた画像には、「exclude(除外)」または「custom robots.txt(カスタムrobots.txt)」を使用することができます。
「Altテキストを表示する方法と、見つからないAltテキストを探す方法」をお読みください。
CSS
Configuration > Spider > Crawl > CSS
(設定 > スパイダー > クロール > CSS)
これにより、CSSファイルの保存とクロールを独立して行うことができます。
「store(保存)」の設定を解除すると、CSSファイルが保存されなくなり、SEOスパイダーに表示されなくなります。
「crawl(クロール)」設定を解除すると、CSSをクロールしてレスポンスコードを確認することはありません。
JavaScript
Configuration > Spider > Crawl > JavaScript
(設定 > スパイダー > クロール > JavaScript)
JavaScriptファイルの保存とクロールを別々に選択することができます。
「store(保存)」設定を解除すると、JavaScriptファイルが保存されず、SEOスパイダーに表示されなくなります。
「crawl(クロール)」設定を解除すると、JavaScriptファイルをクロールしてレスポンスコードを確認することができなくなります。
SWF
Configuration > Spider > Crawl > SWF
(設定>スパイダー>クロール>SWF)
SWF(Adobe Flash File形式)ファイルの保存とクローリングを別々に選択することができます。
「store(保存)」設定を解除すると、SWFファイルは保存されず、SEOスパイダーにも表示されなくなります。
「crawl(クロール)」設定を解除すると、SWFファイルをクロールしてレスポンスコードを確認することができなくなります。
内部リンク
Configuration > Spider > Crawl > Internal Hyperlinks
(設定 > スパイダー > クロール > 内部ハイパーリンク)
初期設定では、SEOスパイダーは内部リンクをクロールして保存します。
ここで言う内部リンクとは、SEOスパイダーに入力されたものと同じサブドメインまで含めたURLのことを指します。ハイパーリンクとは、HTMLのアンカータグに含まれるURLのことです。
「crawl(クロール)」を無効にすることで、アンカータグに含まれるURLのうち、開始URLと同じサブドメインにあるURLは、追跡・クロールされなくなります。
「store(ストア)」と「crawl(クロール)」の両方を無効にすることは、リストモードでクロールの深さを削除する際に便利です。これは、SEOスパイダーがアップロードされたURLと選択された他のリソースやページリンクをクロールすることを可能にしますが、内部リンクはもうありません。
例えば、リストモードでURLのリストを提供し、それらとhreflangリンクのみをクロールすることができます。
あるいは、デスクトップ用URLのリストを提供し、そのAMPバージョンのみを監査することもできます。URLのリストをアップロードし、その中の画像や外部リンクなどを監査することも可能です。
外部リンク
Configuration > Spider > Crawl > External Links
(設定 > スパイダー > クロール > 外部リンク)
外部リンクの保存とクロールを別々に選択することができます。
外部リンクとは、クロール中に発見した、クロールを開始したドメインとは異なるドメインのURLのことです。
「store(保存)」設定を解除すると、外部リンクは保存されず、SEOスパイダーにも表示されなくなります。
「crawl(クロール)」設定を解除すると、外部リンクがクロールされて応答コードが確認されなくなります。
なお、これには画像、CSS、JS、hreflang属性、canonicals(外部の場合)が含まれることがあります。
Caonical(正規化)
Configuration > Spider > Crawl > Canonicals(設定 > スパイダー > クロール > カノニカル)
初期設定では、SEOスパイダーはcanonical(canonical link elementまたはHTTPヘッダー)を保存してクロールし、その中に含まれるリンクを発見に使用します。
「store(保存)」設定を解除すると、canonicalが保存されず、SEOスパイダーに表示されなくなります。
「crawl(クロール)」設定を解除すると、正規化されたURLはクロールされなくなります。「store」 のみを選択した場合、それらはインターフェイスで報告され続けますが、発見には使用されないだけです。
canonicalを監査する方法については、こちらのガイドをご覧ください。
ページネーション(rel next/prev)
Configuration > Spider > Crawl > Pagination (Rel Next/Prev)
(設定 > スパイダー > クロール > ページネーション(Rel Next/Prev))
初期設定では、SEOスパイダー は rel=”next” と rel=”prev” 属性をクロールせず、その中に含まれるリンクを発見するために使用することはありません。
「store(保存)」設定を解除すると、rel=”next” と rel=”prev” の属性が保存されず、SEOスパイダーに表示されなくなります。
「crawl(クロール)」の設定を解除すると、rel=”next” と rel=”prev” で検出されたURLはクロールされなくなります。
rel=”next “とrel=”prev “のページネーション属性の監査方法については、こちらのガイドをご覧ください。
Hreflang
Configuration > Spider > Crawl > Hreflang(設定 > スパイダー > クロール > Hreflang)
SEOスパイダーは初期設定でhreflang属性を抽出し、hreflangの言語・地域コードとURLをhreflangタブに表示します。
ただし、「Crawl hreflang(hreflangをクロール)」にチェックされていない限り、hreflang属性で見つかったURLはクロールされず、発見に使用されません。
この設定を有効にすると、リストモードでアップロードされたXMLサイトマップからhreflang URLが抽出されるようになります。
「store(保存)」の設定を解除すると、hreflang属性が保存されず、SEOスパイダーに表示されなくなります。
「crawl(クロール)」の設定を解除すると、hreflangで発見されたURLはクロールされなくなります。
Hreflangを監査する方法については、こちらのガイドをご覧ください。
AMP
Configuration > Spider > Crawl > AMP(設定 > スパイダー > クロール > AMP)
初期設定では、SEOスパイダーはrel=”amphtml “リンクタグに含まれるAMP URLの詳細を抽出せず、その後AMPタブの下に表示されます。
「store(保存)」の設定を解除すると、rel=”amphtml” リンクタグに含まれるURLは保存されず、SEOスパイダーに表示されなくなります。
「crawl(クロール)」の設定を解除すると、rel=”amphtml “のリンクタグに含まれるURLはクロールされなくなります。
AMPを監査する際には、両方の設定オプションを有効にすることをお勧めします。Accelerated Mobile Pages (AMP)の監査と検証の方法については、こちらのガイドをご覧ください。
メタリフレッシュ
Configuration > Spider > Crawl > Meta Refresh
(設定 > スパイダー > クロール > メタリフレッシュ)
初期設定では、SEOスパイダーはmeta refreshに含まれるURLを保存し、クロールします。
<meta http-equiv="refresh" content="4; URL='www.screamingfrog.co.uk/meta-refresh-url'"/>。「sotre(ストア)」設定を解除すると、meta refreshの詳細が保存されず、SEOスパイダー内に表示されなくなります。
「crawl(クロール)」の設定を解除すると、meta refreshで発見されたURLはクロールされなくなります。
iframe
Configuration > Spider > Crawl > iframes(設定 > スパイダー > クロール > iframes)
初期設定では、SEOスパイダーはiframe内に含まれるURLを保存し、クロールします。
<iframe src="https://www.screamingfrog.co.uk/iframe/"></iframe>「store(保存)」設定を解除すると、iframeの詳細が保存されず、SEOスパイダー内に表示されなくなります。
「crawl(クロール)」の設定を解除すると、iframe内で発見されたURLはクロールされなくなります。
開始フォルダ以外のリンクのチェック
Configuration > Spider > Crawl > Check Links Outside of Start Folder
(設定 > スパイダー > クロール > 開始フォルダ外のリンクをチェックする)
開始するサブフォルダ外のリンクをクロールしない場合は、このボックスのチェックを外してください。このオプションを使用すると、開始サブフォルダ内をクロールしても、それらのURLのリンク先が開始フォルダの外にある場合は、そのリンクをクロールする機能が提供されます。
開始フォルダ外をクロールする
Configuration > Spider > Crawl > Crawl Outside of Start Folder
(設定 > スパイダー > クロール > 開始フォルダ外をクロールする)
初期設定では、SEOスパイダーはクロールするサブフォルダ(またはサブディレクトリ)だけを前方からクロールします。しかし、特定のサブフォルダからクロールを開始し、Webサイト全体をクロールしたい場合は、このオプションを使用します。
すべてのサブドメインをクロールする
Configuration > Spider > Crawl > Crawl All Subdomains
(設定 > スパイダー > クロール > すべてのサブドメインをクロールする)
初期設定では、SEOスパイダーはあなたがクロールを指示したサブドメインのみをクロールし、それ以外のサブドメインは外部サイトとして扱います。これらは1つのレベルまでしかクロールされず、「外部」タブに表示されます。
例えば、開始URLとして「https://www.screamingfrog.co.uk」を入力した場合、「https://cdn.screamingfrog.co.uk」や「https://images.screamingfrog.co.uk」などのクロールで発見された他のサブドメインは、www.google.co.uk などの他のドメインと同様に「外部」として扱われることになります。
CDNs設定オプションを使用すると、外部URLを内部URLとして扱うことができます。
内部または外部の「nofollow」をフォローする
Configuration > Spider > Crawl > Follow Internal/External “Nofollow”
(設定 > スパイダー > クロール > 内部/外部 “Nofollow “をフォローする)
初期設定では、SEOスパイダーは「nofollow」「sponsored」「ugc」属性を持つ内部リンクや外部リンク、meta nofollowタグやX-Robots-Tag HTTP Headerにnofollowを持つページからのリンクはクロールしません。
SEOスパイダーにクロールさせたい場合は、この設定オプションを有効にするだけです。
クロールリンクされたXMLサイトマップ
Configuration > Spider > Crawl > Crawl Linked XML Sitemaps
(設定 > スパイダー > クロール > リンクされたXMLサイトマップをクロールする)
SEOスパイダーは初期設定でXML Sitemapsをクロールしません(通常の「Spider」モードの場合)。XML Sitemapsをクロールし、Sitemapsタブのフィルタに情報を入力するには、この設定を有効にする必要があります。
「Crawl Linked XML Sitemaps(XML Sitemaps内のリンクをクロールする)」の設定を有効にすると、「Auto Discover XML Sitemaps via robots.txt」を選択するか、「Crawl These Sitemaps」にチェックを入れてXML Sitemapのリストを提供し、表示されるフィールドに貼り付けることができます。
注意:クロールが完了したら、サイトマップフィルタに入力するために「クロール分析」を実行する必要があります。「XMLサイトマップの監査方法」についてのガイドをお読みください。
Extractionタブ
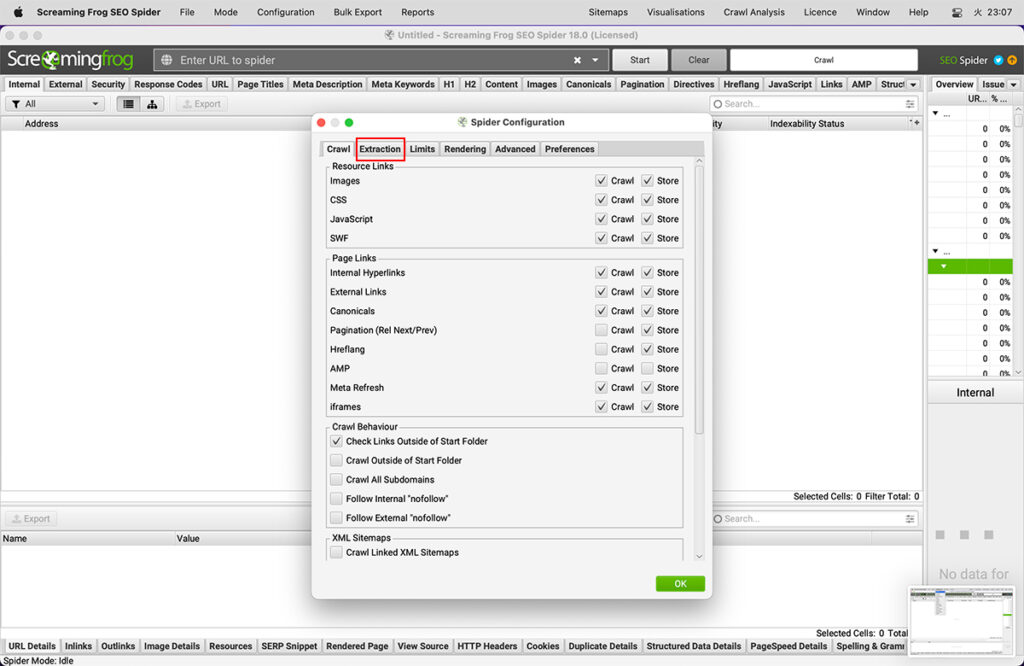
設定内にある「Extraction」タブの機能およびチェック有無の効果の違いを説明します。
ページ詳細
Configuration > Spider > Extraction > Page Details
(設定 > スパイダー > 抽出 > ページ詳細)
SEOスパイダーに格納するページ上の要素は、以下のものが設定可能です。
- ページタイトル
- メタディスクリプション
- メタ・キーワード
- H1
- H2
- インデクサビリティ(&インデクサビリティステータス)
- 単語数
- 読みやすさ
- テキストとコードの比率
- ハッシュ値
- ページサイズ
- フォーム
上記のオプションを無効にすると、SEOスパイダーのインターフェースで、それぞれのタブ、カラム、フィルターに表示されなくなります。
いくつかのフィルタやレポートは、無効にすると明らかに機能しなくなります。例えば、「ハッシュ値」を無効にすると、「URL > Duplicate」フィルタが入力されなくなります。これは、ハッシュ値を使用してURLの完全な重複をアルゴリズムでチェックするためです。
各要素のデータを保存しない分、少量のメモリを節約することができます。
URLの詳細
Configuration > Spider > Extraction > URL Details
(設定 > スパイダー > 抽出 > URLの詳細)
SEOスパイダーに保存されるURLの詳細として、以下の設定が可能です。
上記のオプションを無効にすると、SEOスパイダーのインターフェイスで、それぞれのタブやカラムに表示されなくなります。
各要素のデータを保存しない分、少量のメモリを節約することができます。
ディレクティブ
Configuration > Spider > Extraction > Directives
(設定 > Spider > 抽出 > ディレクティブ)
SEOスパイダーに格納するディレクティブは、以下のものが設定可能です。
- メタロボット
- XRobotsタグ
上記のオプションを無効にすると、SEOスパイダーのインターフェイスで、それぞれのタブ、カラム、フィルターに表示されなくなります。
データを保存しない分、少量のメモリが節約されます。
構造化データ
Configuration > Spider > Extraction > Structured Data
(設定 > スパイダー > 抽出 > 構造化データ)
構造化データはSEOスパイダーに保存されるように完全に設定することができます。構造化データのテストと検証方法についての詳細なガイドをご覧いただくか、以下の設定オプションをご参照ください。
初期設定では、SEOスパイダーは構造化データを抽出してレポートすることはありません。「Structured Data(構造化データ)」タブに表示される異なる構造化データ形式を有効にするには、以下の設定オプションが必要です。
また、Schema.orgやGoogleのリッチリザルト機能に対して、構造化データの検証を選択することができます。
Schema.orgの検証・確認
この機能を有効にすると、SEOスパイダーは構造化データをSchema.orgの仕様に照らして検証することができます。タイプやプロパティが存在するかどうかをチェックし、問題が発生した場合は「エラー」を表示します。
例えば、プロパティとして 「http://schema.org/author」 が存在するかどうか、型として 「http://schema.org/Book」 が存在するかどうかをチェックする。メインスキーマとペンディングスキーマの語彙を最新バージョンで検証します。構造化データタブとフィルターには、検証エラーの詳細が表示されます。
さらに、この検証では、DataVocabulary.orgの古いスキーマが使われていないかをチェックできます。
Google リッチリザルト機能の検証
この機能を有効にすると、SEOスパイダーはGoogleのリッチリザルト機能の要件に照らして、Googleのドキュメントに従って構造化データの検証を行います。必須のプロパティの検証問題はエラーとして分類され、推奨プロパティに関する問題は、Google独自の構造化データテストツールと同じように、警告として分類されます。
Structured Dataタブとフィルターには、Google機能の検証エラーと警告の詳細が表示されます。
SEOスパイダーが検証できるGoogleのリッチリザルト機能の全リストは、構造化データのテストと検証方法についてのガイドで見ることができます。
HTML
Configuration > Spider > Extraction > Store HTML / Rendered HTML
(設定 > スパイダー > 抽出 > HTMLの保存/レンダリング)
HTMLの保存
これにより、SEOスパイダーがクロールしたすべてのURLの静的HTMLをディスクに保存し、「View Source(ソースの表示)」下部ウィンドウペイン(左側の「Original HTML(オリジナルHTML)」下)で表示することができます。また、「Bulk Export > Web > All Page Source(一括エクスポート > Web > 全てのソース)」で一括エクスポートすることができます。
これにより、ブラウザの右クリックによる「ソースの表示」と同じように、JavaScriptが動作する前のオリジナルのHTMLを表示することができます。これは、デバッグや、レンダリングされたHTMLとの比較に最適です。
レンダリングされたHTMLを保存する
これにより、SEOスパイダーがクロールしたすべてのURLのレンダリングHTMLをディスクに保存し、「View Source(ソースの表示)」ウィンドウの下部ペイン(右側の「レンダリングHTML」)で表示することができます。また、「Bulk Export > Web > All Page Source(一括エクスポート > Web > 全てのソース)」で一括エクスポートすることができます。
これにより、JavaScriptが処理された後のDOMを「inspect element(Chromeのデベロッパーツール)」のように表示することができます。
このオプションは、JavaScriptのレンダリングが有効な場合にのみ機能することに注意してください。
Configuration > Spider > Extraction > PDF
(設定 > スパイダー > 抽出 > PDF)
PDFの保存
この機能により、クロール中にPDFを保存することができます。「Bulk Export > Web > All PDF Documents(一括エクスポート > ウェブ > すべての PDF ドキュメント)」で一括エクスポートすることもできますし、「Bulk Export > Web > All PDF Content(一括エクスポート > ウェブ > すべての PDF コンテンツ)」でコンテンツのみを .txt ファイルとしてエクスポートすることもできます。
PDFが保存されている場合、PDFは「レンダリングページ」タブで、PDFのテキスト内容は「ソース表示」タブと「可視コンテンツ」フィルターで確認することが可能です。
PDFのプロパティを抽出する
初期設定では、PDFのタイトルとキーワードが抽出されます。これらはSEOスパイダーの内部タブの「Title(タイトル)」と「Meta Keywords(メタキーワード)」カラムに表示されます。
GoogleはPDFをHTMLに変換し、PDFのタイトルをtitle要素、キーワードをmeta keywordsとして使用しますが、meta keywordsは順位決めの要素に使用しません。
「Extract PDF properties(PDFのプロパティを抽出する)」を有効にすることで、以下の追加プロパティも抽出されます。
- 課題
- 著者名
- 作成日
- 修正日
- ページ数
- 単語数
これらの新しい列は、「内部」タブに表示されます。
Limitsタブ
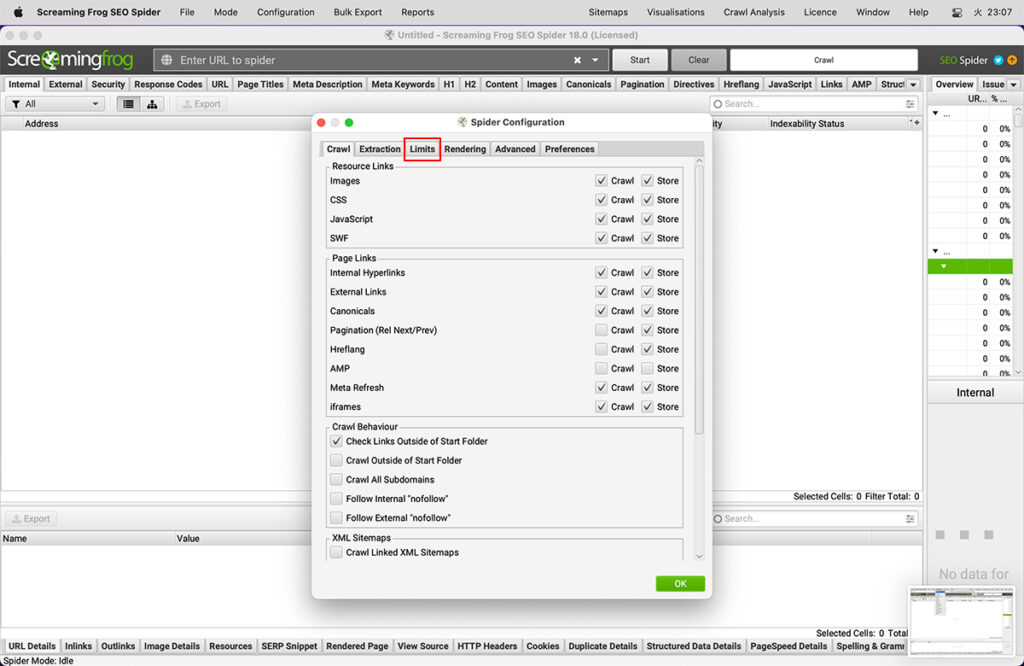
設定内にある「Limits」タブの機能およびチェック有無の効果の違いを説明します。
クロールの合計を制限する
Configuration > Spider > Limits > Limit Crawl Total
(設定 > スパイダー > 制限 > クロールの合計を制限する)
無料版では、500URLのクロール制限があります。ライセンス版のツールの場合、これは500万URLに置き換わりますが、ここに任意の数を入れることで、クロールしたいページ数をより細かく制御することができます。
クロールの深さを制限する
Configuration > Spider > Limits > Limit Crawl Depth
(設定 > スパイダー > 制限 > クロールの深さを制限する)
SEOスパイダーがどの程度深くサイトをクロールするかを選択できます(選択した開始点からのリンク数で)。
クロール深度ごとのURL制限
Configuration > Spider > Limits > Limit URLs Per Crawl Depth
(設定 > スパイダー > 制限 > クロールの深さごとにURLを制限する)
各クロール深度でクロールされるURLの数を制御します。
最大フォルダ深度の制限
Configuration > Spider > Limits > Limit Max Folder Depth
(設定 > スパイダー > 制限 > 最大フォルダ深度の制限)
SEOスパイダーがクロールするフォルダー(またはサブディレクトリ)の数を制御します。
Spiderは、ドメイン以降のURLパスの一部で、末尾にスラッシュがあるフォルダを分類しています。
- https://www.screamingfrog.co.uk/ ← フォルダの深さ 0
- https://www.screamingfrog.co.uk/seo-spider/ ← フォルダの深さ 1
- https://www.screamingfrog.co.uk/seo-spider/#download ← フォルダの深さ 1
- https://www.screamingfrog.co.uk/seo-spider/fake-page.html ← フォルダの深さ 1
- https://www.screamingfrog.co.uk/seo-spider/user-guide/ ← フォルダの深さ 2
クエリ文字列の数量を制限する
Configuration > Spider > Limits > Limit Number of Query Strings
(設定 > スパイダー > 制限 > クエリ文字列の数量を制限)
SEOスパイダーがクロールするクエリ文字列パラメータ(?x=)の数を制御します。
クロールするURLの最大長を制限する
Configuration > Spider > Limits > Limit Max URL Length
(設定 > スパイダー > 制限 > URLの最大長を制限)
SEOスパイダーがクロールするURLの長さを制御します。
データベースストレージの制限により、初期設定の最大URL長は2,000となっています。
最大限のリダイレクトを実現
Configuration > Spider > Limits > Limit Max Redirects to Follow
(設定 > スパイダー > 誠意源 > 最大限のリダイレクトを制限)
このオプションは、SEOスパイダーがたどるリダイレクトの数を制御する機能を提供します。
URLパスで制限する
Configuration > Spider > Limits > Limit by URL Path
(設定 > スパイダー > 制限 > URLパスで制限)
URLパスでクロールするURLの数を制御します。URLパターンのリストと、それぞれについてクロールする最大ページ数を入力します。
Renderringタブ
設定内にある「Renderring」タブの機能およびチェック有無の効果の違いを説明します。
レンダリング
Configuration > Spider > Rendering
(設定 > スパイダー > レンダリング)
この設定では、クロールのレンダリングモードを設定することができます。
- Windows 10
- Windows 8 & 8.1
- Windows Server 2008 R2
- Windows Server 2012
- Windows Server 2016
- Ubuntu 14.04+ (64ビットのみ)
- Mac OS X 10.9以上
確認方法は、インストール先のディレクトリ(c:\Program Files (x86)↪Screaming Frog SEOスパイダーに移動し、ScreamingFrogSEOSpider.exeを右クリックして「プロパティ」→「互換性」タブを選択し、「互換モード」セクションに何もチェックが入っていないことを確認してください。
レンダリングページのスクリーンショット
Configuration > Spider > Rendering > JavaScript > Rendered Page Screenshots
(設定 > スパイダー > レンダリング > JavaScript > レンダリングページのスクリーンショット)
この設定は、JavaScriptレンダリングを選択すると初期設定で有効になり、レンダリングされたページのスクリーンショットがキャプチャされ、下のウィンドウペインの「レンダリングページ」タブで見ることができます。
Googlebotデスクトップ、Googlebotスマートフォン、その他様々なデバイスから様々なウィンドウサイズを選択することができます。
レンダリングされたスクリーンショットは、
「C:\Users\User Name\.ScreamingFrogSEOSpider\screenshots-XXXXXXXXXXXXXXX」に保管もできますし、「Bulk Export > Web > Screenshots(一括エクスポート > Web > スクリーンショット)」から任意の場所にエクスポートできます。
隠れたDOMの平均化
Configuration > Spider > Rendering > JavaScript > Flatten iframes
(設定 > スパイダー > レンダリング > JavaScript > Shadow DOMをフラットにする)
Google は、ページのレンダリング HTML の一部としてShadow DOMコンテンツを平坦化してインデックス化することができます。この設定は初期設定で有効になっていますが、無効にすることも可能です。
iframeの平均化
Configuration > Spider > Rendering > JavaScript > Flatten iframes
(設定> スパイダー >レンダリング>JavaScript>iframeを平坦にする)
Googleは、条件が許す限り、親ページのレンダリングされたHTMLのdivにiframeをインラインで表示します。これには、高さが設定されていること、モバイルビューポートであること、noindexでないことなどが含まれます。Googleの挙動を模倣するようにしています。 この設定は初期設定で有効になっていますが、無効にすることもできます。
AJAXのタイムアウト
Configuration > Spider > Rendering > JavaScript > AJAX Timeout
(設定 > Spider > レンダリング > JavaScript > AJAXタイムアウト)
この時間設定は、SEOスパイダーがページの読み込みを判断する前にJavaScriptの実行を許可する時間を秒単位で指定します。このタイマーは、Chromiumブラウザがウェブページと、JS、CSS、画像などの参照リソースを読み込んだ後に開始されます。
実際には、Googleは上記の5秒という数字よりも柔軟で、ページのコンテンツ読み込みにかかる時間を基に、ネットワークの動きやキャッシュなども考慮しながら適応しています。しかし、Googleは永遠に待ってはくれません。したがって、クロールやインデックスに登録させたいコンテンツは、素早く利用できるようにしなければ、単に見てもらえないだけです。
5秒ルールは、ユーザーにとっても、Googlebotにとっても、合理的な経験則です。
ウィンドウの大きさ
Configuration > Spider > Rendering > JavaScript > Window Size
(設定 > スパイダー > レンダリング > JavaScript > ウィンドウサイズ)
これはJavaScriptレンダリングモードでのビューポートサイズを設定するもので、「レンダリングページ」タブでキャプチャしたレンダリングページのスクリーンショットで確認することができます。
Googlebotのデスクトップとスマートフォンの両方のウィンドウサイズに対して、Googlebotの動作をエミュレートして、できるだけ多くのデータを取得するために、ページを非常に長くリサイズするようにしています。
SEOスパイダーは、モバイルでは411×731ピクセル、デスクトップでは1024×768ピクセルでページを読み込み、8,192pxまで縦にリサイズして表示します。これは現在、内蔵のChromiumブラウザーで取り込める限界値です。Googleは縦12,140pxまでリサイズが可能です。
まれに、ウィンドウサイズがレンダリングされるHTMLに影響を与えることがあります。例えば、一部のWebサイトでは、小さなビューポートでは特定の要素が表示されないことがあり、この場合、文字数やリンクなどの結果に影響を与えることがあります。
Advancedタブ
設定内にある「Advance」タブの機能およびチェック有無の効果の違いを説明します。
クッキーの保存
Configuration > Spider > Advanced > Cookie Storage
(設定 > スパイダー > 詳細 > クッキーの保存)
GoogleはCookieを使わずにステートレスでウェブをクロールしますが、ページを読み込んでいる間はCookieを受け付けます。一部のWebサイトでは、Cookieを受け入れた場合にのみ表示され、受け入れが無効になっている場合は失敗します。
初期設定では、SEOスパイダーは「セッションのみ」クッキーを受け付けます。これは、ページロード時に受け入れられ、その後クリアされ、Googlebotと同じように追加のリクエストに使用されないことを意味します。
あなたは、Cookieの保存方法を、セッションを越えてCookieを記憶する「Persistent」、またはCookieを一切受け付けない「Do Not Store」に変更することができます。
クッキーは、新しいクロールの開始時にリセットされます。
問題となるインデックス化不可能なURLを無視
Configuration > Spider > Advanced > Ignore Non-Indexable URLs for Issues
(設定 > スパイダー > 詳細 > インデックス化されていないURLを無視して問題を解決する)
この機能を有効にすると、SEOスパイダーはページがインデックス可能な場合にのみ、問題に関連するフィルタを入力するようになります。これには、ページタイトル、メタディスクリプション、メタキーワード、H1およびH2タブのすべてのフィルタと、次の他の課題が含まれます。
- コンテンツタブの「低コンテンツページ」
- 構造化データ」タブの「欠落」、「検証エラー」、「検証警告」
- Sitemapsタブの「Orphan URLs」
- アナリティクスタブで「GAデータなし」
- Search Consoleタブの「検索アナリティクスデータがありません」
- リンクタブの「クロール深度が高いページ」
- 例:「noindex」に設定されているURLは、「重複」、「X文字以上」、「X文字以下」とはみなされず、インデックスされないことを意味します。
大規模サイトでnoindexを持つステージングサイトをクロールする場合は、この機能を無効にすることをお勧めします。
重複フィルタリングのためにページ分割されたURLを無視する
Configuration > Spider > Advanced > Ignore Paginated URLs for Duplicate Filters
(設定 > スパイダー > 詳細 > 重複フィルタリングのためにページ分割されたURLを無視)
この機能を有効にすると、ページタイトル、メタディスクリプション、メタキーワード、H1およびH2タブの「重複」フィルターにおいて、一連のURLのうちrel=”prev “を持つURLは考慮されなくなります。rel=”next “属性を持つ、ページ分割されたURLのうち、最初のURLのみが考慮されます。
つまり、ページ分割されたURLは、例えば分割された最初のページとページタイトルが「重複」しているとはみなされません。これは正常で期待される動作です。したがって、この設定により、問題としてフラグが立てられることはありません。
常にリダイレクトに従う
Configuration > Spider > Advanced > Always Follow Redirects
(設定 > スパイダー > 詳細 > 常にリダイレクトに従う)
この機能は、SEOスパイダーがリストモードで、クロールの深さを無視して最終的なリダイレクト先URLまでリダイレクトを追いかけることができるようにするものです。これは特にサイトの移行時に、URLが最終目的地に到達するまでに何度も3XXリダイレクトを実行するような場合に有効です。
サイト移行時のリダイレクトを表示するには、「all redirects(すべてのリダイレクト)」レポートを使用することをお勧めします。
この設定の活用方法については、「リストモードの使い方」のガイドをご覧ください。
常にカノニカルに従う
Configuration > Spider > Advanced > Always Follow Canonicals
(設定 > Spider > 詳細 > 常にカノニカルに従う)
この機能により、SEOスパイダーはリストモードで、クロールの深さを無視して、最終的なリダイレクト先URLまでcanonicalを追跡することができます。これは特にサイトの移行時に便利で、canonicalが最終目的地に到達するまでに複数回canonical化される可能性があります。
canonicalチェーンを表示するには、この設定を有効にして、「canonical chains」レポートを使用することをお勧めします。
この設定を「常にリダイレクトを追う」ように活用する方法については、「リストモードの使い方」のガイドをご覧ください。
noindexを尊重する
Configuration > Spider > Advanced > Respect Noindex
(設定 > スパイダー > 詳細 > Noindexを尊重する)
このオプションは、「noindex」を持つURLはSEOスパイダーで報告されないことを意味します。これらのURLはまだクロールされ、そのアウトリンクをたどりますが、ツール内には表示されません。
Caonicalを尊重する
Configuration > Spider > Advanced > Respect Canonical
(設定 > スパイダー > 詳細 > Canonicalを尊重する)
このオプションは、別のURLに正規化されたURLはSEOスパイダーで報告されないことを意味します。これらのURLはまだクロールされ、そのアウトリンクをたどりますが、ツール内には表示されません。
next/prevを尊重する
Configuration > Spider > Advanced > Respect Next/Prev
(設定>スパイダー> 詳細 > next/prevを尊重する)
このオプションは、rel=”prev “属性を持つURLはSEOスパイダーで報告されないことを意味します。rel=”next “属性を持つ、ページ分割されたシーケンスの最初のURLのみが報告されます。
これらのURLは引き続きクロールされ、そのアウトリンクをたどりますが、ツール内には表示されません。
HSTSポリシーを尊重する
Configuration > Spider > Advanced > Respect HSTS Policy
(設定 > スパイダー > 詳細 > HSTSポリシーを尊重する)
HTTP Strict Transport Security(HSTS)は、RFC6797で定義されている規格で、Webサーバーがクライアントに対して、HTTPSによるアクセスのみを許可することを宣言するためのものです。
クライアント(この場合はSEOスパイダー)は、HTTPのURLへのリンクを辿っている場合でも、今後すべてのリクエストをHTTPSで行うようになります。この場合、SEOスパイダーはステータスコード307、ステータス “HSTSポリシー”、リダイレクトタイプ “HSTSポリシー “を表示します。
この機能を無効にすると、リダイレクトの背後にある「真の」ステータスコードを見ることができます(たとえば、301パーマネントリダイレクトなど)。
詳しくは、「An SEOs guide to Crawling HSTS & 307 Redirects」の記事をご覧ください。
自己参照メタリフレッシュを尊重する
Configuration > Spider > Advanced > Respect Self Referencing Meta Refresh
(設定 > スパイダー > 詳細 > 自己参照メタリフレッシュを尊重)
「Respect Self Referencing Meta Refresh(自己参照メタリフレッシュを尊重)」の設定を無効にすることで、自己参照メタリフレッシュURLを「インデックス非対応」と判断しないようにすることができます。
様々な理由で自己参照メタリフレッシュを行うサイトはかなり一般的で、一般的にこれはページのインデックスには影響しません。しかし、自分自身にリダイレクトしているため、さらに調査する必要があり、そのため「インデックス不可」のフラグが立っています。
img srcset 属性から画像を抽出する
Configuration > Spider > Advanced > Extract Images From IMG SRCSET Attribute
(設定 > スパイダー > 詳細 > IMG SRCSET 属性から画像を抽出する)
有効にすると、<img>タグのsrcset属性から画像を抽出します。下の例では、image-1x.png、image-2x.png、image-src.pngが抽出されます。
<img src="image-src.png" srcset="image-1x.png 1x, image-2x.png 2x" alt="Retina friendly images" />クロール断片の識別子
Configuration > Spider > Advanced > Crawl Fragment Identifiers
(設定 > スパイダー > 詳細 > クロール断片の識別子)
この機能を有効にすると、SEOスパイダーはハッシュフラグメントを含むURLをクロールし、それらを別のユニークなURLと見なします。
初期設定では、SEOスパイダーは検索エンジンのようにハッシュ値から何かを無視します。しかし、これは例えばページ内ジャンプリンクやブックマークなどを分析する際に有効です。
応答タイムアウト
Configuration > Spider > Advanced > Response Timeout (secs)
(設定 > スパイダー > 詳細 > 応答タイムアウト (秒))
SEOスパイダーは、初期設定でURLから何らかのHTTPレスポンスを取得するのに20秒待ちます。非常に遅いWebサイトの場合は、待ち時間を長くすることができます。
5XX レスポンスリトライ
Configuration > Spider > Advanced > 5XX Response Retries
(設定 > スパイダー > 詳細 > 5XX レスポンスリトライ)
このオプションは、5XX応答を自動的に再試行する機能を提供します。多くの場合、これらの応答は一時的なものであるため、URLを再試行すると2XX応答が返されることがあります。
preferences(環境設定)タブ
設定内にある「Preferences」タブの機能およびチェック有無の効果の違いを説明します。
ページタイトルとメタディスクリプションの幅
Configuration > Spider > Preferences > Page Title/Meta Description Width
(設定>スパイダー>環境設定>ページタイトル/メタ説明文の幅)
このオプションは、ページタイトルとメタディスクリプションタブのSEOスパイダーフィルターにおける文字数とピクセル幅の制限を制御する機能を提供します。
例えば、ページタイトルの幅の最小ピクセル幅の初期設定値「200」を変更すると、「ページタイトル」タブの「200ピクセル以下」フィルタが変更されます。このように、自分の好みに合わせて、文字やピクセル幅を設定することができます。
注意:現時点では、SERPスニペットのプレビューは更新されず、タブ内のフィルタのみが更新されます。
リンク
Configuration > Spider > Preferences > Links
(設定> スパイダー> 環境設定 >リンク)
これらのオプションは、「リンク」タブで「外部リンクが多いページ」、「内部リンクが多いページ」、「クロールの深さが高いページ」、「内部リンクのアンカーテキストが非記述的」フィルターをトリガーするタイミングを制御する機能を提供します。
例えば、「内部アウトリンクが多い」の初期設定値を1,000から2,000に変更すると、「リンク」タブのこのフィルターで表示されるページには2,000以上の内部アウトリンクが必要であることを意味します。
その他の設定
Configuration > Spider > Preferences > Links
(設定 > その他 > 環境設定 > その他)
これらのオプションは、
- URLの文字数
- h1
- h2
- 画像のaltテキスト
- 最大画像サイズ
- 低コンテンツページ
上記のフィルターをそれぞれのタブで制御する機能を提供します。
例えば、「最大画像サイズ・キロバイト」を100から「200」に調整した場合、「画像>Xキロバイト以上」タブとフィルターに200kb以上の画像のみが表示されるようになります。
その他の設定オプション
その他、タブ以外の説明を行ないます。
コンテンツ領域
Configuration > Content > Area
(設定>コンテンツ>エリア)
- ワードカウント
- 重複コンテンツに近い分析
- スペルや文法のチェックに使用するコンテンツエリア
これらを指定することで、ページのメインコンテンツ領域に分析を集中させ、既知の定型的なテキストを避けることができます。
初期設定では、SEOスパイダーはウェブページのbody HTML要素に含まれるテキストのみを考慮します。初期設定では、ページのメインコンテンツに使用されるコンテンツ領域に焦点を当てるために、ナビとフッターの両方のHTML要素が除外されます。
しかし、すべてのWebサイトがこれらのHTML5セマンティック要素を使用して構築されているわけではなく、分析に使用するコンテンツ領域をさらに絞り込むことが有効な場合もあります。使用するコンテンツに対して、除外または含めるHTML要素、クラスまたはIDのリストを追加することができます。
例えば、Screaming FrogのWebサイトでは、nav要素の外側にモバイルメニューがあり、初期設定でコンテンツ分析に含まれます。モバイルメニューは、重複コンテンツをチェックする際に、以下に示す「重複の詳細」タブのコンテンツプレビューで確認できます(「スペル・文法の詳細」タブと同様)。

右クリックしてWebサイトのHTMLのソースを見ると、このメニューには「mobile-menu__dropdown」クラスがあることが分かります。mobile-menu__dropdown’は、’Exclude Classes’ボックスで除外することができます – 。
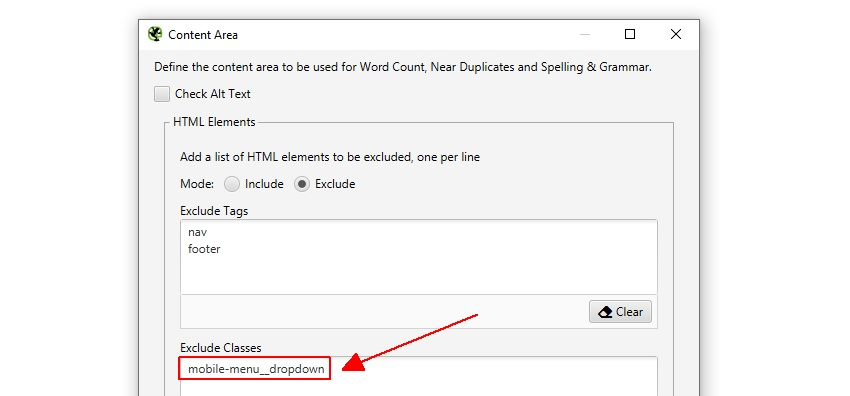
その後、モバイルメニューはニアダプリケート分析から除外され、コンテンツは重複の詳細タブに表示されます(スペル&グラマーやワードカウントも同様です)。
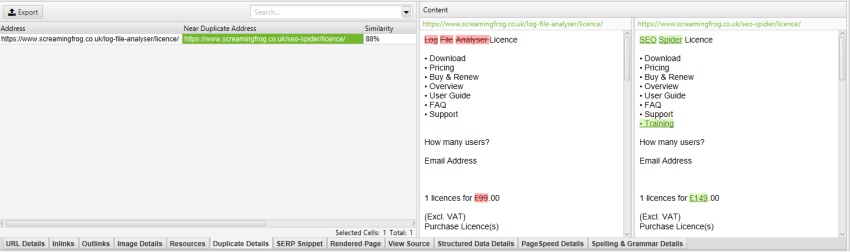
コンテンツエリアの設定は、クロール後に重複コンテンツ解析とスペル・文法の調整を行うことができます。また、スペル・文法については、右側の「スペル・文法」タブまたは下部の「スペル・文法の詳細」タブで、解析結果を更新する必要があります。
重複コンテンツの発見や スペル・文法チェックについては、チュートリアルをご覧ください。
重複
Configuration > Content > Duplicates
(設定 > コンテンツ > 重複)
SEOスパイダーは、ページが全く同じである完全な重複と、異なるページ間で一部のコンテンツが一致する近しい重複率を検出することができます。これらの情報は、「コンテンツ」タブとそれに対応する「Exact Duplicates(完全な重複)」「Near Duplicates(近しい重複)」フィルターで確認することができます。
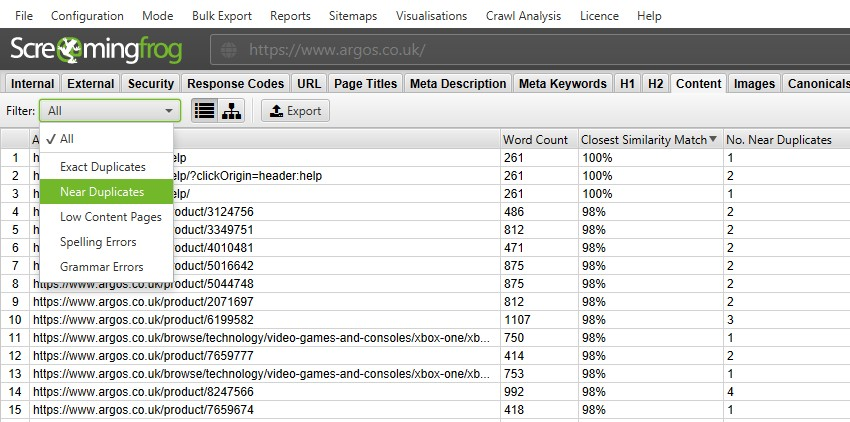
完全な重複ページは初期設定で検出されます。「Near Duplicates(近しい重複)」をチェックするには、SEOスパイダーが各ページのコンテンツを保存できるように、設定を有効にする必要があります。

SEOスパイダーは、ミンハッシュアルゴリズムを使用して類似度90%で一致するニアデュプリケート(重複)を特定します。このアルゴリズムは、類似度の閾値を低くしてコンテンツを見つけるように調整することができます。
また、SEOスパイダーは「インデックス可能な」ページのみ重複をチェックします(完全な重複とそれに近い重複の両方について)。
つまり、2つのURLが同じで、一方がもう一方に正規化されている場合(つまり「インデックス非作成」)、このオプションが無効になっていなければ、このことは報告されません。
重複しているURLの詳細については、「Duplicate Details(重複の詳細)」の下部のタブで確認することができます。これは、特定されたすべての重複するURLとその類似性の一致を表示します。
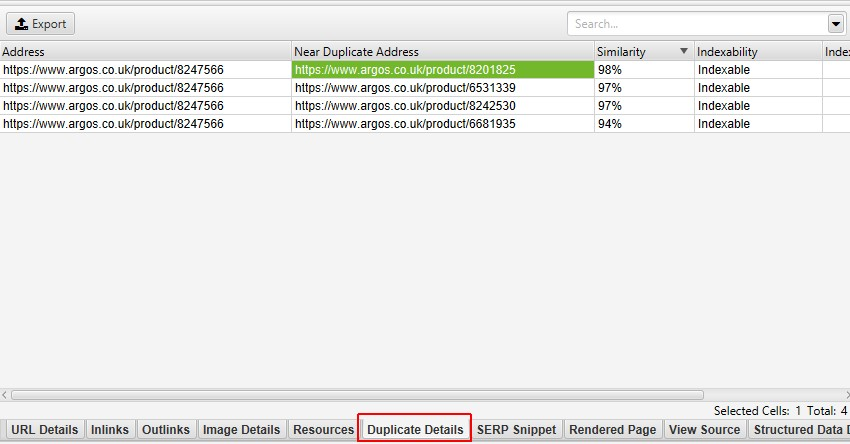
また、「Duplicate Details(重複の詳細)」タブで「Near Duplicate Address(重複に近いアドレス)」をクリックすると、ページ間で発見された重複に近い内容が表示され、相違点が強調表示されます。

近接重複分析に使用するコンテンツ領域は、「Configuration > Content > Area(設定 > コンテンツ > 領域)」で調整することができます。HTML要素、クラス、IDのリストを追加して、使用するコンテンツに除外したり、含めたりすることができます。
重複コンテンツに近い閾値と解析に使用するコンテンツ領域は、いずれもクロール後に更新することができ、クロール解析を再実行することで、再クロールの必要なく結果を精緻化することができます。
スペル・文法
Configuration > Content > Spelling & Grammar
(設定 > コンテンツ > スペル&グラマー)
SEOスパイダーは、クロール中のHTMLページに対して、スペルチェックや文法チェックを行うことが可能です。その他のコンテンツタイプには現在対応していませんが、将来的に対応する可能性があります。
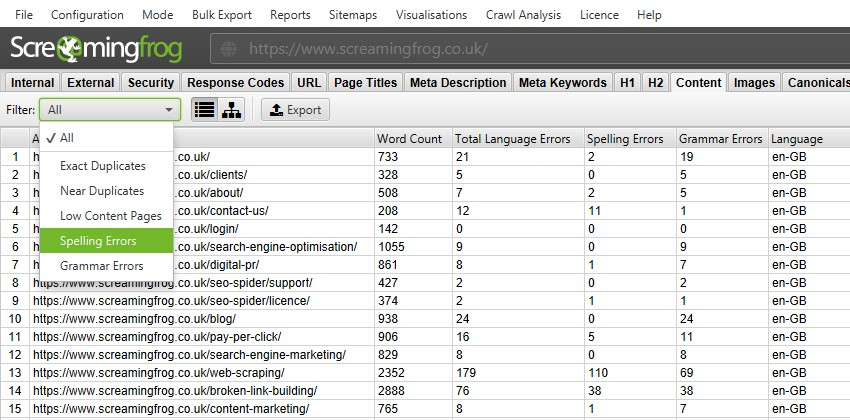
スペルチェックと文法チェックは初期設定では無効になっており、「コンテンツ」タブと対応する「Spelling Errors(スペルエラー)」「Grammar Errors(文法エラー)」フィルターにスペルや文法のエラーを表示させるには、有効にする必要があります。

スペルチェックと文法機能は、ページで使用されている言語を(HTMLの言語属性によって)自動的に識別しますが、設定内で必要に応じて言語を手動で選択することも可能です。

その中には(言語)も含まれています。
- アラビア語
- オーストラリア語
- ベラルーシ語
- ブルトン語
- カタロニア語
- 中国語
- デンマーク語
- オランダ語
- 英語(オーストラリア、カナダ、ニュージーランド、南アフリカ、アメリカ、イギリス)
- フランス語
- ガリシア語
- ドイツ語(オーストリア、ドイツ、スイス)
- ギリシャ語
- イタリア語
- 日本語
- カンボジア語
- ペルシャ語(アフガニスタン、イラン)
- ポーランド語
- ポルトガル語(アンゴラ、ブラジル、モザンビーク、ポルトグアル)
- ルーマニア語
- ロシア語
- スロバキア語
- スロベニア語
- スペイン語
- スウェーデン語
- タガログ語
- タミル語
- ウクライナ語
スペルや文法に対応した新しい言語をご覧になりたい場合は、FAQをご覧ください。
下のウィンドウの「スペル・文法の詳細」タブには、エラーの種類(スペルまたは文法)、詳細、および問題を修正するための提案が表示されます。また、詳細タブの右側には、ページのテキストと識別されたエラーがビジュアルで表示されます。

右側のペイン「Spelling & Grammar(スペル&文法)」タブには、発見された上位100の個別エラーと、それらが影響するURLの数が表示されます。これは、テンプレート間でエラーを見つけたり、辞書や無視リストを作成するのに便利です。
右クリックして「Ignore grammar rule(文法規則を無視する)」、「Ignore All(すべてを無視する)」、「Add to Dictionary(辞書に追加する)」のいずれかを選択することができます。
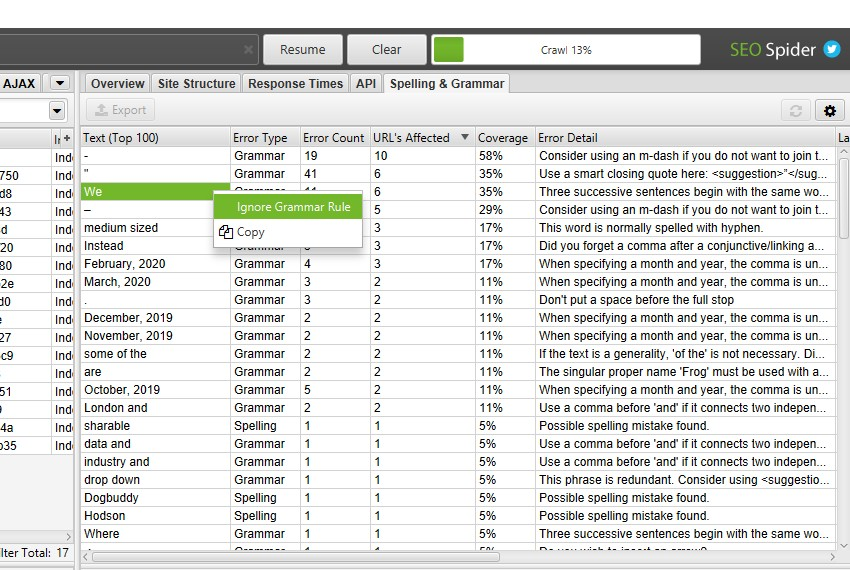
スペル&文法設定
スペルチェックと文法チェックに使用するコンテンツ領域は、「Configuration > Content > Area(設定 > コンテンツ > 領域)」で調整することができます。HTML要素、クラス、IDのリストを追加して、分析されるコンテンツに除外したり、含めたりすることができます。
文法ルール、無視する単語、辞書、解析に使用したコンテンツエリアの設定はすべてクロール後(または一時停止中)に更新でき、スペルチェックや文法チェックを再実行することで、再クロールの必要なく結果を精緻化することができます。

Robots.txtの設定
Robots.txtを尊重する、無視する
Configuration > Robots.txt > Settings > Respect Robots.txt / Ignore Robots.txt(設定 > Robots.txt > 設定 > robots.txtを尊重する / robots.txtを無視する)
SEOスパイダーは初期設定でrobots.txtのプロトコルに従い、「Respect robots.txt(robots.txtを尊重する)」に設定されています。つまり、robots.txtで禁止されているサイトはSEOスパイダーがクロールすることができません。
「Ignore Robots.txt(robots.txtを無視する)」設定は、通常のクロール制御設定を無視することができます。この設定はSEOスパイダーがrobots.txtファイルをダウンロードしないことを意味します。つまり、すべてのrobotsディレクティブが完全に無視されることを意味します。
「Ignore Robots.txt, but report status(Robots.txtを無視し、ステータスを報告する)」設定は、Webサイトのrobots.txtをダウンロードしてSEOスパイダーで報告することを意味します。しかし、その中のディレクティブは無視されます。これにより、Webサイトをクロールしながら、どのページがクロールからブロックされるべきかを確認することができます。
Robots.txtでブロックされた内部URLの表示
初期設定では、robots.txtによってブロックされた内部URLは、「内部」タブにステータスコード「0」、ステータス「Blocked by Robots.txt」で表示されます。これらのURLを非表示にするには、このオプションの選択を解除します。このオプションは、「Ignore robots.txt(robots.txtを無視する)」がチェックされている場合は使用できません。
また、「レスポンスコード」タブと「Robots.txtでブロック」フィルタで、robots.txtによってブロックされた内部URLを表示することができます。これは、ブロックされている各URLに対するdisallowのrobots.txtディレクティブ(’matched robots.txt line’ column)も表示されます。
Robots.txtでブロックされた外部URLの表示
初期設定では、robots.txtによってブロックされた外部URLは非表示になっています。ステータスコード「0」、ステータス「Blocked by Robots.txt」で「外部」タブに表示する場合は、このオプションをチェックしてください。このオプションは、「Ignore robots.txt(robots.txtを無視する)」がチェックされている場合は使用できません。
また、「レスポンスコード」タブと「Robots.txtでブロック」フィルタで、robots.txtでブロックされた外部URLを表示することができます。これは、ブロックされている各URLに対してdisallowのrobots.txtディレクティブ(matched robots.txt line(一致したrobots.txtの行の列))も表示されます。
robots.txtのカスタマイズ
Configuration > Robots.txt > Custom
(設定 > Robots.txt > カスタム)
カスタム robots.txt 機能を使用すると、サイトの robots.txt をダウンロード、編集、テストすることができ、クロールのためにサイト上のライブバージョンを無効化します。この機能は、サイト上のライブrobots.txtを上書きしてクロールします。
この機能により、サブドメインレベルで複数のrobots.txtを追加し、SEOスパイダーでディレクティブをテストし、ブロックまたは許可されているURLを表示することができます。カスタムrobots.txtは、設定で選択されたユーザーエージェントを使用します。

クロール中に、カスタム robots.txt (Response Codes > Blocked by robots.txt) に基づいてブロックされた URL をフィルタリングし、一致する robots.txt ディレクティブ行を確認することができます。
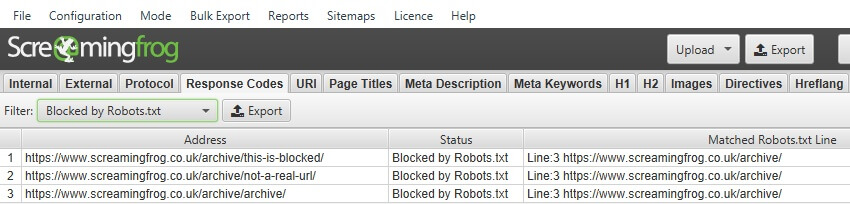
SEOスパイダーをrobots.txtのテスターとして使用する方法については、特集のユーザーガイドをご覧ください。
URLリライト
Configuration > URL Rewriting
(設定 > URLリライト)
URLリライト機能は、URLをその場で書き換えることができる機能です。多くの場合、「remove parameters(パラメータを削除)」と共通オプション(「options」下)で十分です。しかし、我々はさらに制御を提供する高度な正規表現による置換機能を提供しています。
URLリライト機能は、Webサイトをクロールする過程で発見されたURLにのみ適用され、「スパイダー」モードでクロールの開始点として入力されたURLや、「リスト」モードでURLの集合の一部として入力されたURLは対象外です。
パラメータを削除する
この機能は、URL内のパラメータを自動的に削除することができます。セッションIDやGoogle Analyticsのトラッキング、削除したいパラメータがたくさんあるWebサイトでは非常に便利です。例えば、以下のような場合です。
WebサイトにセッションIDがあり、URLの表示が「example.com/?sid=random-string-of-characters」のようになる場合において、セッションIDを削除するには、「remove parameters(パタメーターの削除)」タブの「parameters(パラメーター)」フィールドに「sid」(アポストロフィを除く)を追加するだけです。
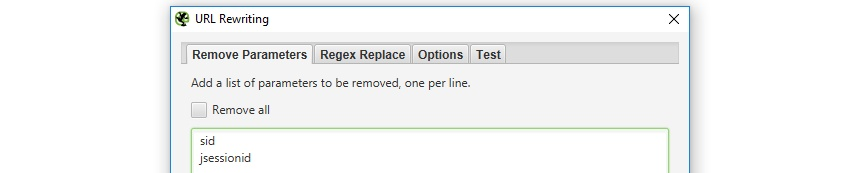
SEOスパイダーは、URLからセッションIDを自動的に削除します。SEOスパイダーがどのようにURLを書き換えるかは、「test」タブでテストすることができます。

この機能は、Google Analyticsのトラッキングパラメータを削除する場合にも使用できます。例えば、「remove parameters」の下に以下のように記述するだけです。
- utm_source
- utm_medium
- utm_campaign
これは、URLから標準のトラッキングパラメータを取り除くものです。
正規表現による置き換え
この高度な機能は、クロール中またはリストモードで見つかった各URLに対して実行されます。正規表現にマッチするURLの各サブストリングを、与えられた置換文字列で置き換えます。「Regex Replace(正規表現による置換)」機能は、「URL Rewriting(URLリライト)」設定ウィンドウの「テスト」タブでテストすることができます。

例としては、以下のようなものがあります。
1)すべてのリンクをHTTPからHTTPSに変更する。
正規表現: http
置換: https
2) example.comへのリンクをすべてexample.co.ukに変更する。
正規表現:.com
置換:.co.uk
3) page=numberを含むリンクはすべて固定番号にする。
www.example.com/page.php?page=1
www.example.com/page.php?page=2
www.example.com/page.php?page=3
www.example.com/page.php?page=4
これらすべてを作るには、www.example.com/page.php?page=1 にアクセスします。
正規表現: page=Gentad+
置換: page=1
4) 空の「置換」を使用して、任意のURLからwww.ドメインを削除する。
クエリ文字列のパラメータを削除したい場合は、「Remove Parameters(パラメータの削除)」機能を使用してください – Regexはこの作業に適したツールではありません!
正規化: www
置換:
5) すべてのパラメータを削除する
正規表現: \?.*
置換:
6) example.comのサブドメインだけのリンクをHTTPからHTTPSに変更する
正規表現: http://(.*example.com)
置換: https://$1
7)JavaScriptレンダリングモードでハッシュ値の後ろのanythingを削除する
Regex: #.*
置換:
8) URLにパラメータを追加する
正規表現: $
置換: ?パラメータ=値
これは、遭遇したURLの末尾に「?parameter=value」を追加します。
すでにパラメータを持つサイトでは、パラメータを正しく追加するために、より複雑な表現が必要になります。
正規表現: (.*?\?.*)
置換: $1¶meter=value
正規表現: (^((?!\?).)*$)
置換: $1?parameter=value
これらは上記の順序で入力しないと、既存のクエリー文字列に新しいパラメータを追加するときに動作しません。
オプション
このセクションには、一般的なオプションが含まれています。発見されたURLを小文字にする」クロールされたすべてのURLを小文字に変換するため、URLの大文字小文字の区別に問題があるWebサイトにとって便利です。
CDN
Configuration > CDNs
(設定 > CDN)
CDNs機能では、クロール時に「Internal(内部リンク)」として扱うCDNのリストを入力することができます。
内部情報として扱うドメインのリストを指定することができます。また、サブフォルダーをドメインと一緒に指定すると、そのサブフォルダー(およびその中のコンテンツ)が内部として扱われます。
「内部」リンクは、「外部」ではなく「内部」タブに含まれ、そこからより詳細な情報が抽出されます。
含む設定
Configuration > Include
(設定 > 含む)
この機能により、SEOスパイダーが正規表現の部分一致でクロールするURLパスを制御することができます。正規表現にマッチしたURLのみをクロールすることで、初期設定の検索を絞り込むことができ、大規模サイトや直感的でないURL構造を持つサイトには特に有効です。マッチングはURLのエンコード版に対して実行されます。
この機能を使うには、クロールを開始するページに正規表現に一致するアウトバウンドリンクがなければ、それ以降はクロールされません。もし開始ページから正規表現に一致するURLがない場合、SEOスパイダーは何もクロールしません。
例えば、URLの文字列に「search」を含むページを https://www.screamingfrog.co.uk からクロールしたい場合、「include(含む設定)」機能に「search」という正規表現を含めるだけでよいでしょう。
この場合、/search-engine-marketing/ と /search-engine-optimisation/ のページは両方とも 「search」 が含まれているため、検索(表示)されることになります。
含む設定機能については、ビデオガイドをご覧ください。
トラブルシューティング
マッチングはURLエンコードされたアドレスに対して行われます。これが何であるかは、下のウィンドウペインのURL情報タブまたは内部タブのそれぞれのカラムで確認できます。
正規表現はURLの一部ではなく、全体にマッチする必要があります。
1つのURLだけがクロールされ、その後クロールが停止する場合は、そのページからのアウトバウンドリンクを確認してください。http://www.example.com/ に 「/news/」を含んでしてクロールし、1つのURLしかクロールされない場合は、http://www.example.com/ にサイトのニュースセクションへのリンクがないことが原因です。
除外設定
Configuration > Exclude
(設定 > 除外)
除外設定により、部分的な正規表現マッチングを使用してURLをクロールから除外することができます。excludeにマッチしたURLは全くクロールされません。これは、除外にマッチしないが、除外されたページからしか到達できない他のURLもクロールで発見されないことを意味します。
除外リストは、クロール中に発見された新しい URL に適用されます。この除外リストは、クロールモードまたはリストモードで最初に提供されたURLには適用されません。
クロール中に除外リストを変更すると、新しく発見されたURLに影響し、保留中のURLのリストに遡って適用されますが、既にクロールされたURLは更新されません。
照合は、URLのURLエンコード版に対して行われます。メインウィンドウでURLを選択し、下のウィンドウペインの詳細タブにある「URLの詳細」タブの2行目のラベル「URL Encoded Address(エンコードURLパス)」の値で、URLのエンコード版を確認することができます。
以下は一般的な例です。
http://www.example.com/do-not-crawl-this-page.html
http://www.example.com/do-not-crawl-this-folder/
http://www.example.com/.*/brand.*
(?は正規表現における特殊文字であり、バックスラッシュでエスケープする必要があることに注意してください)
\?price
jpg$
-[0-9]{6}$
exclude
https
http://www.domain.com/
これらを個別に探すよりも、以下のように記述して探すほうがよいでしょう。
\Qhttp://www.example.com/test.php?product=specialE
つまり、パイプ | を含むすべての URL を除外したい場合
%7C
google-analytics.com
除外機能についてのビデオガイドをご覧ください。
スピード
Configuration > Speed
(設定 > スピード)
速度設定では、SEOスパイダーの速度を、同時実行スレッド数、または1秒間にリクエストされるURL数で制御することができます。
速度を下げる場合、常に「Max URI/s」オプションで制御するのが簡単です。これは、1秒あたりのURLリクエストの最大数です。例えば、以下のスクリーンショットは、1秒間に1つのURLでクロールすることを意味します。
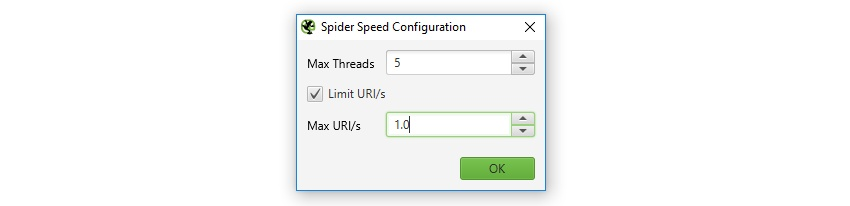
「Max Threads(最大スレッド数)」オプションは、1秒あたりのURL数で速度を調節する場合、単に放置しておくことができます。
スレッド数を増やすことで、SEOスパイダーの速度を大幅に向上させることができます。初期設定では、サーバーに負荷をかけないよう、SEOスパイダーは5スレッドでクロールします。
クロールの速度を上げるためにスレッド数を多く設定すると、サーバーへのHTTPリクエストの数が増え、サイトの応答時間に影響を与える可能性がありますので、責任を持ってスレッド設定を使用してください。非常に極端なケースでは、サーバーに過負荷がかかり、クラッシュする可能性があります。
まずWebマスターとクロール速度と時間を承認し、応答時間を監視して、問題があれば初期設定の速度を調整することをお勧めします。
ユーザーエージェント
Configuration > User-Agent
(設定 > ユーザーエージェント)
ユーザーエージェントの設定では、SEOスパイダーが行うHTTPリクエストのユーザーエージェントを切り替えることができます。初期設定では、SEOスパイダーは独自の「Screaming Frog SEO spider user-agent」という文字列を使用してリクエストを行います。
しかし、Googlebot、Bingbot、各種ブラウザなどに対応したユーザーエージェントがあらかじめ組み込まれています。これにより、必要なときに素早く切り替えることができます。また、この機能には、独自のユーザーエージェントを指定することができるカスタムユーザーエージェント設定があります。
SEOスパイダーによるrobots.txtの扱いの詳細はこちらでご確認ください。
HTTPヘッダー
Configuration > HTTP Header
(設定 > HTTPヘッダー)
HTTPヘッダーの設定では、クロール中に完全にカスタム化されたヘッダーリクエストを供給することができます。

つまり、accept-language、cookie、referer、あるいは任意のユニークなヘッダー名を設定することが可能です。例えば、ロケールに適応したコンテンツをクロールするために、SEOスパイダーのリクエストにAccept-Language HTTPヘッダーを指定したい場合があります。
ヘッダー値フィールドには、必要な言語と地域のペアを選択することができます。
ユーザーエージェントは、他のヘッダとは別に「Configuration > User-Agent(設定 > ユーザーエージェント)」で設定します。
カスタム検索
Configuration > Custom > Search
(設定>カスタム>検索)
SEOスパイダーは、Webサイトのソースコードから任意の情報を探すことができます。カスタム検索機能では、クロールしたすべてのページのHTML(ページテキスト、または検索対象として選択した特定の要素)をチェックします。
初期設定では、カスタム検索はWebサイトの生のHTMLソースコードをチェックしますが、これはブラウザでレンダリングされるテキストとは異なる場合があります。JavaScriptレンダリングモードに切り替えると、レンダリングされたHTMLを検索することができます。
カスタム検索設定では、最大100個の検索フィルターを設定することができ、テキストまたは正規表現を入力すると、選択した入力内容を「contains(含む)」または「does not contain(含まない)」ページを検索することができます。
これは、「Config > Custom > Search(設定>カスタム>検索)」で確認できます。

右下の「add(追加)」をクリックするだけで、フィルターを設定することができます。
左から順に、検索フィルターの名前、「contains(含む)」または「does not contain(含まない)」の選択、「text(テキスト)」または「regex(正規表現)」の選択、検索クエリの入力 – そして検索を実行する場所(HTML、ページテキスト、要素、または XPath など)を選択できます。

例えば、「Out of stock(在庫切れ)」のようなページには「contains(含む)」を選択し、これを含むすべてのページを見つけたい場合です。Google Analyticsのコードのようなものを検索する場合は、「does not contain(含まない)」フィルターを選択し、コードを含まないページを検索します(コードを含むページをすべてリストアップするのではありません!)。
入力したデータを「contains(含む)」「does not contain(含まない)」ページは、「カスタム検索」タブで確認することができます。

「contains(含む)」フィルタでは、検索対象の出現回数が表示され、「does not contain(含まない)」検索では、「contains(含む)」または「does not contain(含まない)」のいずれかが返されます。
この検索では、「Out of stock(在庫切れ)」のテキストを含む2URLがあり、それぞれ1回だけその単語を含んでいます。一方、GTMコードは10ページ中1つも見つかっていません。
SEOスパイダーは、こちらに記載されているように、Java regex libraryを使用しています。データを「スクレイピング」または「抽出」するには、カスタム抽出機能をご利用ください。
カスタム検索では、正規表現を使用して正確な単語を検索することができます。例えば
\bexample\bのように、特定の単語(この場合は「example」)にマッチします。
大文字と小文字の区別、完全一致と複数単語の検索、検索の組み合わせ、特定の要素での検索、複数行のコードのスニペットなど、より高度なシナリオについては、チュートリアルの「カスタム検索の使用方法」を参照してください。
カスタム抽出
Configuration > Custom > Extraction
(設定 > カスタム > 抽出)
カスタム抽出では、URLのHTMLから任意のデータを収集することができます。抽出は、内部のHTMLページが2xx応答コードで返す静的なHTMLに対して実行されます。
JavaScriptレンダリングモードに切り替えると、レンダリングされたHTMLからデータを抽出することができます(クライアントサイドのみの任意のデータについて)。
SEOスパイダーは、データ抽出を行うために以下のモードをサポートしています。
- XPath: XPathセレクタ(属性を含む)
- CSS Path: CSS Path とオプションの属性。
- Regex: HTMLコメントやインラインJavaScriptのスクレイピングなど、より高度な用途に使用します。
XパスやCSSパスを使ってHTMLを収集する場合、何を抽出するか?の選択ができます。
- Extract HTML Element: 選択された要素とその内部のHTMLコンテンツ
- Extract Inner HTML: 選択された要素の内側のHTMLの内容です。セレクトした要素が他のHTML要素を含んでいる場合は、それらも含まれます。
- Extract Text: 選択された要素のテキスト内容と、任意のサブ要素のテキスト内容を抽出します。
- Function Value: 例えば、count(//h1) は、ページ上の h1 タグの数を調べます。
カスタム抽出を設定するには、「Config > Custom > Extraction(設定 > カスタム > 抽出)」をクリックします。

抽出機能を使用するには、「add(追加)」をクリックし、関連する構文を挿入するだけです。
Webサイトからデータをスクレイピングするために、最大100個の個別の抽出構文を設定することができます。

抽出されたデータは、「Custom Extraction(カスタム抽出)」タブで確認することができます。抽出されたデータは、「Internal(内部)」タブにも列として含まれます。
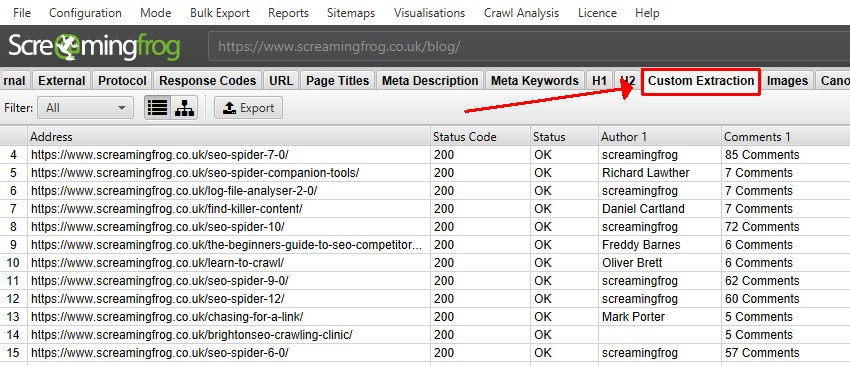
カスタム抽出の使用方法については、SEOスパイダーウェブスクレイピングガイドをお読みください。カスタム抽出式の例については、XPathの例と Regexの例を参照してください。
Regexのトラブルシューティング
- SEOスパイダーは正規表現を実行する前にHTMLを処理することはありません。しかし、ブラウザでソースを閲覧する際に表示されるHTMLは、SEOスパイダーが見ているものと異なる可能性があることをご了承ください。これは、Webサイトがユーザーエージェントやクッキーに基づいて異なるコンテンツを返す場合や、ページのコンテンツがJavaScriptを使用して生成され、JavaScriptレンダリングを使用していない場合などに起こります。
- SEOスパイダーが使用している正規表現エンジンの詳細は、こちらをご覧ください。
- 正規表現エンジンは、ドット文字が改行と一致するように設定されています。
カスタムリンクの位置
Configuration > Custom > Link Positions
(設定>カスタム>リンク位置)
SEOスパイダーは、ナビゲーション、ページコンテンツ、サイドバー、フッターなど、ページ上のあらゆるリンク位置を分類しています。
分類は、各リンクの「link path(リンクパス)」(XPathとして)を使用して、既知の意味的な部分文字列に対して行われ、「inlinks(内部リンク)」と「outlinks(発リンク)」タブで見ることができます。
これにより、例えば、メインナビゲーションやフッターにあるリンクを無視して、本文中にあるページへの「inlinks(内部リンク)」を特定することができ、内部リンクの分析をより効果的に行うことができます。
あなたのWebサイトがセマンティックHTML5要素(またはdiv id=”nav “などのよく知られた非セマンティック要素)を使用していれば、SEOスパイダーはウェブページの異なる部分とその中のリンクを自動的に判断することができるようになります。

初期設定のリンクポジションの設定では、以下の検索語を用いてリンクを分類しています。

しかし、すべてのWebサイトがこの方法で構築されているわけではないので、各サイト独自の設定に基づいてリンク位置の分類を構成することができます。これにより、リンクパスの部分文字列を使用して、リンクを分類することができます。
例えば、Screaming FrogのWebサイトでは、nav要素の外にあるモバイルメニューリンクは「content(コンテンツ)」リンクにあると判断されています。これは、モバイルではサイト全体のナビゲーションを追加しているに過ぎず、正しくありません。これは、nav要素内になく、クラス名に’nav’を持つなど、うまく名付けられていないためです。(ドン!)
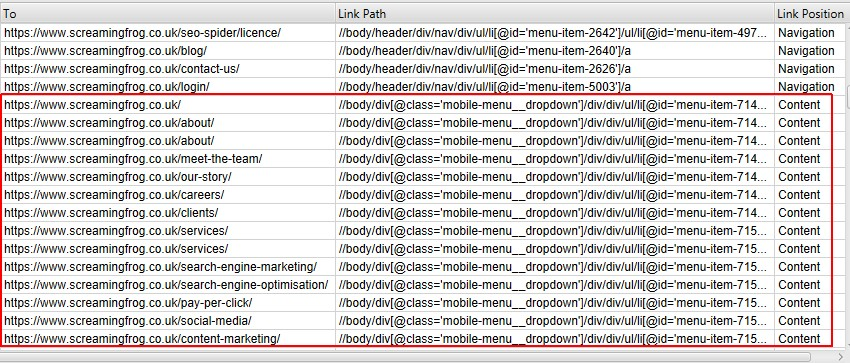
「mobile-menu__dropdown」というCSSのクラス名(上記のようにリンクパスにある)は、リンクポジション機能を使用して、その正しいリンクポジションを定義するために使用することができます。

これらのリンクは、サイトワイドナビゲーションリンクとして正しく帰属されます。
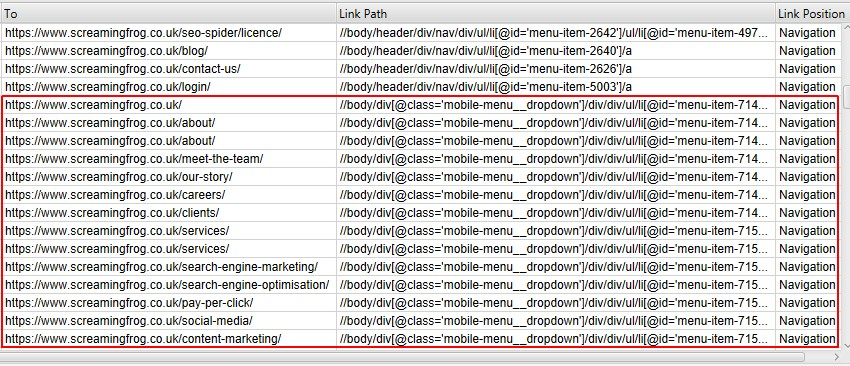
リンク位置の分類に使用される検索語または部分文字列は、優先順位に基づいています。コンテンツ」は「/」と設定され、あらゆるリンクパスにマッチするため、常に設定の最下位になるようにします。
そこで、上記の例では、「mobile-menu__dropdown」クラス名を追加し、「Move Up」ボタンを使って「Content」の上に移動し、優先的に表示するようにしました。これによって「リンク位置」の分類を無効にすることができます。つまり、各リンクのXPathが保存されず、リンク位置が決定されないことを意味します。これにより、メモリの節約とクロールの高速化を図ることができます。
ユーザーインターフェース
Configuration > User Interface
(設定 > ユーザーインターフェース)
ユーザーインターフェースメニューの下には、いくつかの設定項目があります。これらは次のとおりです。
- Reset Columns For All Tables: テーブルの列が削除または移動された場合、このオプションで列を初期設定に戻すことができます。
- Reset Tabs: タブが削除または移動された場合、このオプションを使用すると、タブを初期設定に戻すことができます。
- Theme > Light / Dark: 初期設定ではSEOスパイダーはライトグレイのテーマを使用しています。しかし、ダークテーマ(別名’ダークモード’、’バットマンモード’など)に切り替えることができます。このテーマは、特に低光量で作業する人の眼精疲労を軽減するのに役立ちます。
Google Analyticsとの連携
Configuration > API Access > Google Universal Analytics / Google Analytics 4
(設定>APIアクセス>Googleユニバーサルアナリティクス/Googleアナリティクス4)
Google Universal Analytics APIやGA4 APIに接続し、クロール中に直接データを取り込むことができます。SEOスパイダーは、ユーザーやセッションの指標、ランディングページのゴールコンバージョンやeコマース(取引や収益)のデータを取り込むことができるので、技術やコンテンツの監査を行う際に、パフォーマンスの高いページを確認することができます。
設定方法は、SEOスパイダーを起動し、「Configuration > API Access(設定>APIアクセス)」から「Google Universal Analytics(グーグルユニバーサルアナリティクス)」または「Google Analytics 4(グーグルアナリティクス4)」を選択します。
次に、データを取得するために「Screaming Frog SEOスパイダー」アプリにアカウントへのアクセス許可を与えて、Googleアカウント(照会したいAnalyticsアカウントへのアクセス権を持つ)に接続します。
Google APIはOAuth 2.0プロトコルを用いて認証と認可を行います。SEOスパイダーはあなたが認証したGoogleアカウントをリスト内に記憶しているので、アプリケーションの起動時に毎回素早く「connect(接続)」することができます。
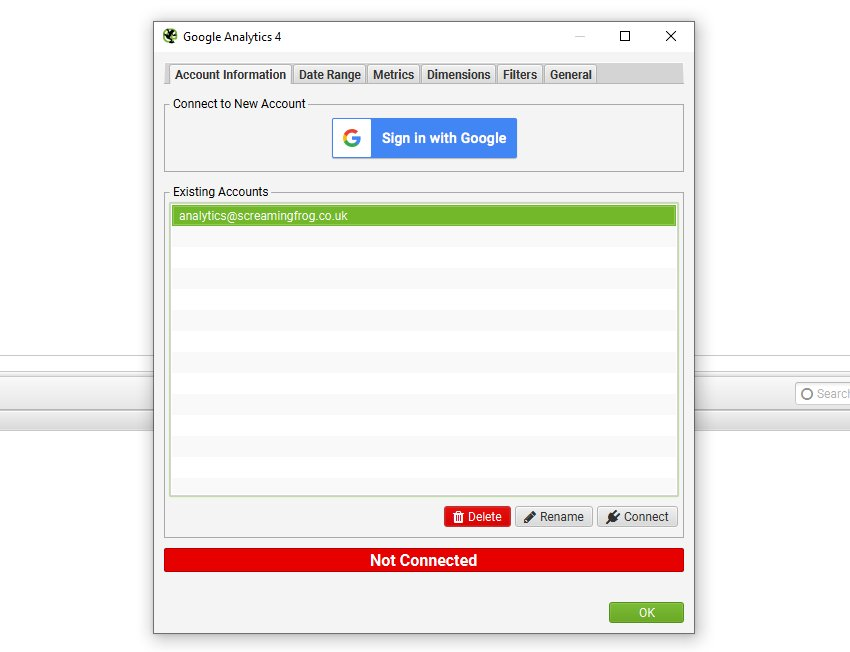
ユニバーサルアナリティクスで接続すると、関連するGoogleアナリティクスのアカウント、プロパティ、ビュー、セグメント、日付範囲を選択することができます。
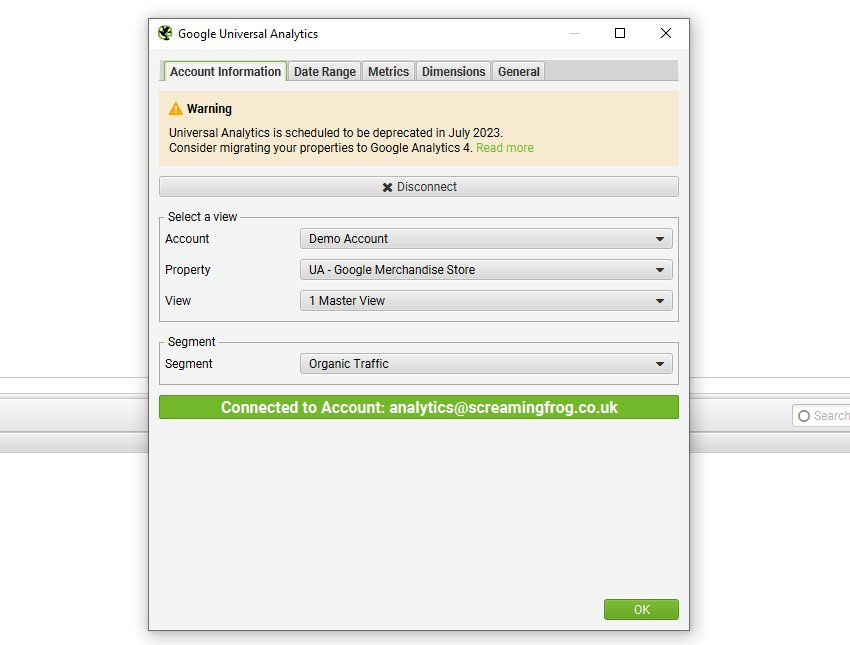
GA4では、アナリティクスアカウント、プロパティ、データストリームを選択することができます。

次に、ユニバーサルアナリティクスに取り込みたい指標を選択するだけです。

またはGA4です。

初期設定では、SEOスパイダーはユニバーサルアナリティクスで以下の11の指標を収集します。
- セッション
- 新規セッション
- 新規ユーザー
- ユーザー
- 直帰率
- セッションごとのページビュー
- 平均セッション時間
- ページ価値
- ゴールコンバージョン率
- 目標達成率 すべて
- 目標値 すべて
UAの場合、APIから一度に最大30個の指標を選択することができます。
GA4では、SEOスパイダーは初期設定で以下の7つの指標を収集します。
- セッション
- エンゲージドセッション
- エンゲージメント率
- ビュー
- コンバージョン
- イベント回数
- 収益合計
GA4では、API経由で利用可能な最大65の指標を選択することができます。
Googleが提供するユニバーサルアナリティクスとGA4で利用できる指標と各指標の定義については、こちらをご覧ください。
また、個々の指標のディメンションを、フルページURL(UAでは「ページパス」)またはランディングページのいずれかに対して設定することができ、これらは全く異なります(そして、シナリオと目的に応じてどちらも有用です)。

GA4では、「filters(フィルター)」タブもあり、追加のディメンションを選択することができます。例えば、「organic search(オーガニック検索)」のようなディメンション値でファーストユーザーやセッションチャンネルのグループ化を選択し、特定のチャンネルに絞り込むことができます。

Google AnalyticsのURLとクロールのURLが一致しない場合があるため、トレイリングスラッシュと非トレイリングスラッシュのURLの自動マッチングや大文字と小文字の区別(URLの大文字と小文字)などでカバーしています。GoogleはAPIでプロトコル(HTTPまたはHTTPS)を渡さないので、これらも自動的にマッチングされます。
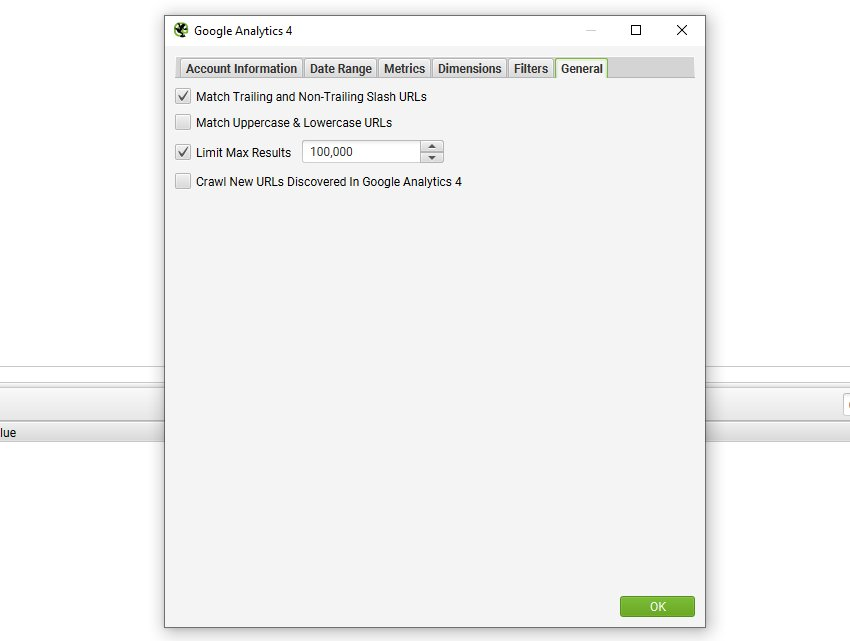
上記のいずれかを選択した場合、Google Analyticsのデータはセッション数でソートされるため、セッション数の多いURLに対してマッチングが行われることにご注意ください。これらのURLについては、データは集計されません。
以下のオプションが利用可能です。
Google Analyticsのデータが取得され、「Internal(内部)」「Analytics(分析)」タブ内のそれぞれのカラムに表示されます。
右上に「API」プログレスバーがあり、これが100%に達すると、URLに対してリアルタイムで分析データが表示されるようになります。照会するURLや指標が多いほど、この処理に時間がかかることがありますが、通常は非常に短時間で完了します。
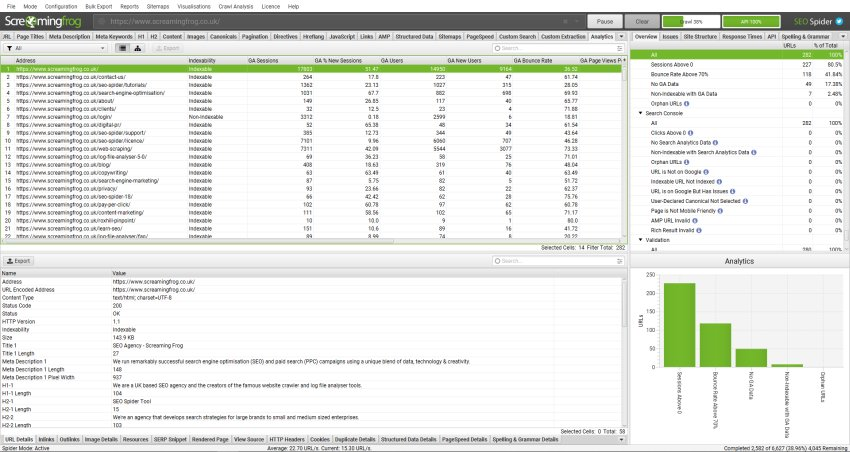
現在、「アナリティクス(分析)」タブには5つのフィルターがあり、Google Analyticsのデータをフィルタリングすることができます。
- Sessions Above 0: これは、該当するURLのセッション数が1以上であることを単純に意味します。
- Bounce Rate Above 70%: これは、URLの直帰率が70%以上であることを意味します。シナリオによっては、これが正常な場合もあります。
- No GA Data: これは、クエリされたメトリクスとディメンションについて、Google APIがクロール内のURLのデータを返さなかったことを意味します。つまり、URLは訪問セッションを受け取らなかったか、あるいは、クロール内のURLは何らかの理由でGA内のURLと異なっている可能性があります。
- Non-Indexable with GA Data: これは、URLはインデックスされないが、GAからのデータが残っていることを意味します。
- Orphan URLs: これは、URLがGA経由でのみ発見され、クロール中に内部リンク経由で発見されなかったことを意味します。
SEOスパイダー -でGoogle Analyticsのデータにアクセスする際の様々な問題については、以下のFAQをお読みください。
Googleアカウントへのアクセス権を付与する際にエラーが発生するのはなぜですか?
Google Analyticsとの接続に失敗するのはなぜですか?
なぜSEOスパイダーのGA-APIデータは、GAインターフェイスで報告されるものと一致しないのですか?
Google Analyticsのアカウントを接続しても、GA4のプロパティが表示されないのはなぜですか?
Google API は、認証と認可に OAuth 2.0 プロトコルを使用しており、Google Analytics やその他の API を通じて提供されるデータは、あなたのマシン上でローカルにのみアクセス可能であることにご注意ください。Googleはそのデータを見ることができず、また保存もしません。詳しくは、FAQをご覧ください。
Google Analytics 4 APIを使用する場合、コアトークンの標準的なプロパティクォータが適用されます。
Google Search Consoleとの連携
Configuration > API Access > Google Search Console
(設定 > APIアクセス > Google Search Console)
Google Search AnalyticsやURL InspectionのAPIに接続し、クロール中に直接データを取り込むことが可能です。
SEOスパイダーは初期設定でSearch Analytics APIからインプレッション、クリック、CTR、ポジションなどの指標を取得するため、技術監査やコンテンツ監査を行う際に上位のページを確認することができます。
オプションで、検索アナリティクスのデータと並行して「Enable URL Inspection(URL検査を有効にする)」を選択すると、1ドメインにつき1日最大2,000URLのGoogleインデックスステータスデータを提供します。これには、「URLがGoogleに登録されているか」、「URLがGoogleに登録されていないか」、そして「カバレッジ」が含まれます。
設定方法は、「Configuration > API Access > Google Search Console(設定 > APIアクセス > Google Search Console)」から行います。Google Search Consoleへの接続は、すでにステップバイステップのGoogle Analytics統合ガイドで詳述したのと同じ方法で動作します。
データを取得するために「Screaming Frog SEOスパイダー」アプリにアカウントへのアクセス許可を与えて、Googleアカウント(問い合わせたいSearch Consoleアカウントにアクセスできるアカウント)に接続します。Google APIは、認証と認可にOAuth 2.0プロトコルを使用します。SEOスパイダーは、あなたが認証したGoogleアカウントをリスト内に記憶するので、毎回アプリケーションを起動する際に素早く「connect(接続)」することができます。
接続が完了すると、関連するWebサイトのプロパティを選択することができます。
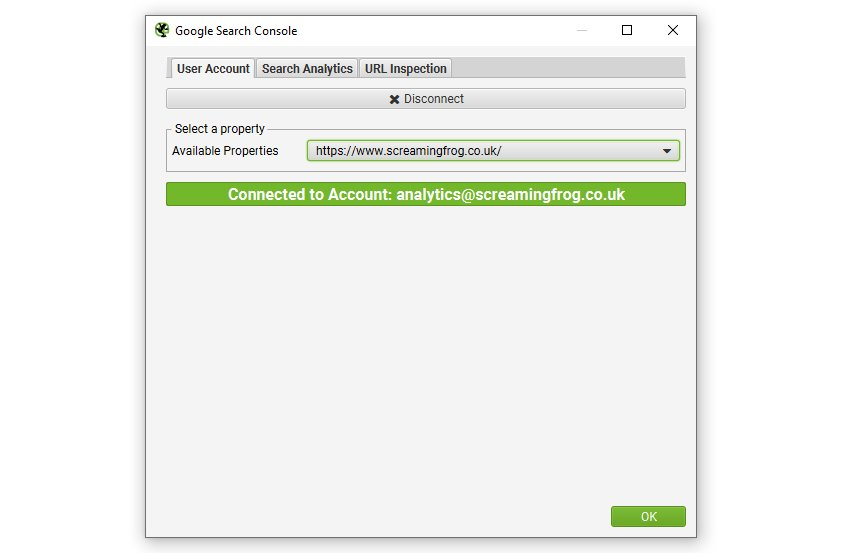
初期設定では、SEOスパイダーは過去30日分の以下の指標を収集します。
- クリック数
- 表示回数
- CTR
- 順位
各メトリクスの定義については、Googleの記事をご覧ください。
設定の「Search Analytics(検索アナリティクス)」タブをクリックすると、日付範囲、ディメンション、その他様々な設定を調整できます。
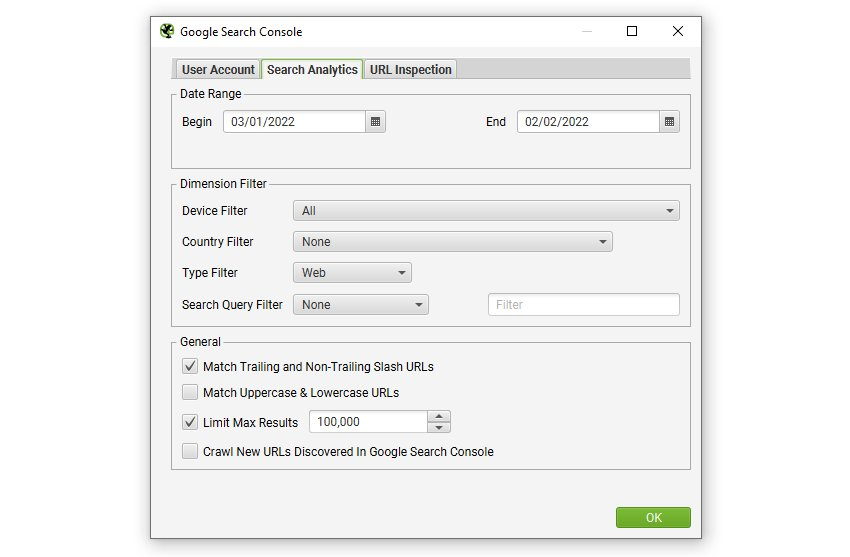
Google Search Consoleから発見された新しいURLをクロールして、離小島になりそうなページを発見したい場合は、以下の設定を忘れずに有効にしてください。

オプションで、「URL Inspection(URLインスペクション)」タブに移動し、「URLインスペクションを有効にする」と、クロールに含まれる最大2,000のURLのインデックス状態に関するデータを収集することができます。
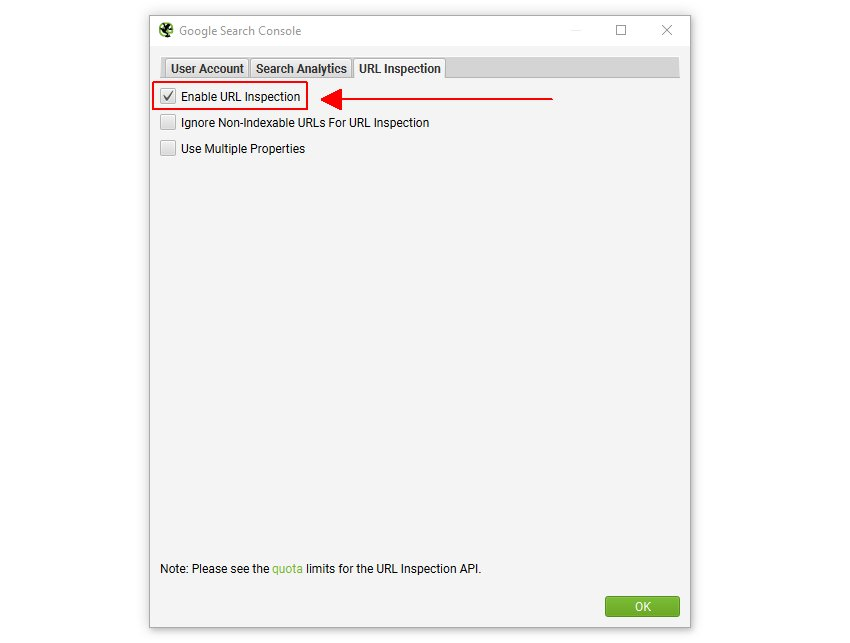
SEOスパイダーは初期設定で幅優先クロール、つまりクロールの開始ページから深さ優先でクロールします。最初に発見された2,000のHTML URLがクエリ対象となります。クロールを特定のセクションに集中させ、含むと除外の設定、またはリストモードを使用して、必要なキーURLとテンプレートのデータを取得します。
以下の設定オプションが利用可能です。
URL Inspection API には、以下のデータが含まれます。
インデックスされたURLの結果については、Googleの記事をご覧ください。
「Search Console」タブには11種類のフィルターがあり、両方のAPIからGoogle Search Consoleのデータをフィルタリングすることができます。
- Clicks Above 0: これは単純に、該当するURLのクリック数が1以上であることを意味します。
- No Search Analytics Data: これは、Search Analytics APIが、クロール内のURLのデータを返さなかったことを意味します。つまり、そのURLはインプレッションを受け取らなかったか、あるいは何らかの理由でクロール内のURLとGSC内のURLが異なるだけなのです。
- Non-Indexable with Search Analytics Data: 非インデックス型と分類されているが、Google検索アナリティクスデータを持っているURL
- Orphan URLs: クロール中に内部リンクではなく、Google Search Analytics経由で発見されたURL。このフィルターを使用するには、Google Search Consoleの設定ウィンドウ(設定 > APIアクセス > Google Search Console)の「General(一般)」タブで「Crawl New URLs Discovered In Google Search Console(Google Search Consoleで発見された新しいURLをクロール)」を有効にし、「crawl analysis(クロール分析)」後のデータを入力する必要があります。離小島ページの発見方法については、こちらのガイドをご覧ください。
- URL Is Not on Google: このURLはGoogleにインデックスされておらず、検索結果には表示されません。このフィルターには、インデックスされる可能性のあるURLだけでなく、インデックスされないURL(「noindex」になっているものなど)も含めることができます。APIに従ってGoogleに登録されていないものに対するキャッチオールフィルタです。
- Indexable URL Not Indexed: クロールで発見されたインデックス可能なURLのうち、Googleにインデックスされず、検索結果に表示されないURL。これには、Googleに知られていないURLや、発見されたもののインデックスされていないURLなどが含まれることがあります。
- URL is on Google, But Has Issues: URLはインデックスされ、Googleの検索結果に表示されますが、モバイルユーザビリティ、AMP、リッチリザルトに問題があり、最適な方法で表示されない可能性があります。
- User-Declared Canonical Not Selected: Googleは、ユーザーがHTMLで宣言したものとは異なるURLをインデックスすることを選択しました。Canonicalはヒントであり、Googleがそのヒントに従うこともあればヒントとして扱わない場合もあります。
- Page Is Not Mobile Friendly: モバイル端末で問題が発生するページです。
- AMP URL Is Invalid: AMPにエラーがあり、インデックスに登録されません。
- Rich Result Invalid: URLに1つ以上のリッチリザルト拡張機能のエラーがあり、リッチリザルトがGoogle検索結果に表示されないようになっています。発見された特定のエラーをエクスポートするには、「Bulk Export > URL Inspection > Rich Results(一括エクスポート > URL検査 > リッチリザルト)」エクスポートを使用します。
詳しくは、「URL検査APIを自動化する方法」のチュートリアルをご覧ください。
PageSpeed Insightsの統合
Configuration > API Access > PageSpeed Insights
(設定 > APIアクセス > PageSpeed Insights)
Google PageSpeed Insights APIに接続し、クロール中に直接データを取り込むことができます。
PageSpeed Insightsは Lighthouseを使用しているため、SEOスパイダーはLighthouseの速度指標の表示、速度機会や診断の規模での分析、リアルユーザーモニタリング(RUM)からのコアウェブバイタルを含むChrome User Experience Report(CrUX)からの実データ収集が可能になりました。
設定方法は、SEOスパイダーを起動し、「Configuration > API Access > PageSpeed Insights(設定>APIアクセス>PageSpeed Insights)」と進み、無料のPageSpeed Insights APIキーを入力し、指標を選択して接続、クロールを行います。
PageSpeed InsightsのAPIキーを設定する
無料のPageSpeed Insights APIキーを設定するには、Googleアカウントにログインし、PageSpeed Insights getting startedページにアクセスしてください。
ページが表示されたら、1段落下にスクロールして、「キーを取得する」ボタンをクリックします。

その後、プロジェクト名を送信し、利用規約に同意して「next(次へ)」をクリックすることで、キーを作成する手順を実行します。
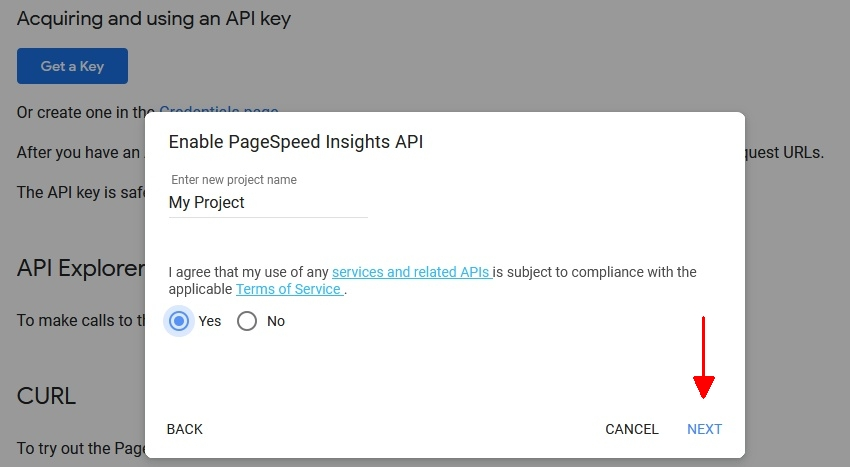
そして、PSI用のキーを有効にし、コピーできるAPIキーを提供します。

キーをコピーして、「Done(完了)」をクリックします。
そして、これを「Configuration > API Access > PageSpeed Insights(設定>APIアクセス>PageSpeed Insights)」のSEOスパイダーの「Secret Key:」欄に貼り付けて「connect(接続)」ボタンを押すだけでよい。このキーは、APIに呼び出しを行うときに使用されます。
https://www.googleapis.com/pagespeedonline/v5/runPagespeed

これで接続完了です。
SEOスパイダーはシークレットキーを記憶しているので、毎回アプリケーションを起動する際に素早く「connect(接続)」することができます。
APIキーが「failed to connect(接続に失敗しました)」と表示されている場合、有効化するのに数分かかることがあります。また、FAQにあるように、APIライブラリでPSI APIが有効になっていることを確認することもできます。有効になっていない場合は、有効にすると接続できるようになるはずです。
接続が完了すると、「metrics(メトリクス)」タブでクエリするメトリクスとデバイスを選択することができます。
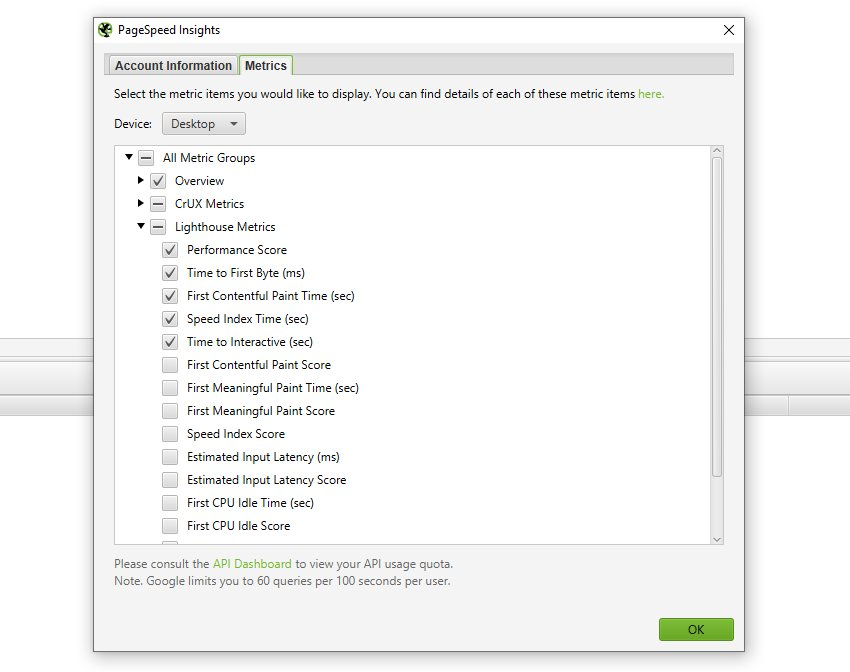
PageSpeed Insights API統合により、以下の速度指標、機会、診断データを収集するよう設定することができます。
概要-メトリクス
- サイズ別の節約額
- 合計時間短縮
- 総リクエスト数
- 総ページサイズ
- HTMLサイズ
- HTMLカウント
- 画像サイズ
- 画像カウント
- CSSサイズ
- CSSカウント
- JavaScriptのサイズ
- JavaScriptのカウント
- 文字サイズ
- フォント数
- メディアサイズ
- メディアカウント
- その他のサイズ
- その他のカウント
- サードパーティーサイズ
- サードパーティーのカウント
CrUX メトリクス(PageSpeed Insights の「フィールドデータ」)
- CrUXパフォーマンス
- CrUXファーストコンテントフルペイント時間(秒)
- CrUX初のコンテントフルペイント部門
- CrUX 第一入力ディレイ時間(秒)
- CrUXファーストインプットディレイカテゴリー
- CrUX最大コンテンツ塗布時間(秒)
- CrUX最大のコンテントフルペイントカテゴリー
- CrUX 累積レイアウトシフト
- CrUX 累積レイアウトシフトカテゴリー
- CrUXインタラクションから次のペイントまで(ms)
- CrUXインタラクションから次の塗装カテゴリーへ
- 最初のバイトまでのCrUX時間(ms)
- CrUX Time to First Byte Category
- CrUX Originのパフォーマンス
- CrUX Origin 最初のコンテンツペイント時間(秒)
- CrUX Origin初のコンテントフルペイントカテゴリー
- CrUX Origin 最初の入力ディレイ時間(秒)
- CrUX Origin 第一入力ディレイカテゴリ
- CrUX Origin 最大のコンテンツペイント時間 (秒)
- CrUX Origin 最大の含有量を持つ塗料カテゴリー
- CrUX Origin 累積レイアウトシフト
- CrUX Origin 累積レイアウトシフトカテゴリー
- CrUX Originインタラクションから次のペイントまで(ms)
- クラックス・オリジン・インタラクション、次の塗装カテゴリーへ
- CrUX Origin 最初のバイトまでの時間 (ms)
- CrUX Origin 最初のバイトまでの時間 カテゴリ
ライトハウスメトリクス(PageSpeed Insightsの「Lab Data」)
- パフォーマンススコア
- 最初のバイトまでの時間(ms)
- 最初のコンテンツ塗布時間(秒)
- 第1回コンテントフル・ペイント・スコア
- スピードインデックス時間(秒)
- スピードインデックススコア
- インタラクティブになるまでの時間(秒)
- インタラクティブスコアまでの時間
- 初回平均塗装時間(秒)
- 初めての意味のあるペイントスコア
- 推定入力待ち時間(ms)
- 入力待ち時間の推定値
- ファーストCPUアイドル(秒)
- ファーストCPUアイドルスコア
- 最大電位 最初の入力ディレイ (ms)
- 最大潜在的な第一入力遅延のスコア
- 総ブロッキング時間 (ms)
- トータルブロッキングタイムスコア
- 累積レイアウトシフト
- レイアウトシフトスコア累計
機会損失
- レンダーブロックの解消 省資源(ms)
- オフスクリーン画像遅延時間 (ms)
- オフスクリーンイメージの保存を延期する
- 画像の効率的なエンコード 省エネ(ms)
- 画像保存の効率的なエンコード
- 画像の適切なサイズ設定 省資源 (ms)
- 画像保存の適切なサイズ
- Minify CSSの節約量(ms)
- CSSの節約を最小化
- Minify JavaScriptの節約量(ms)
- 最小限のJavaScriptの節約
- CSSの未使用量を削減する(ms)
- CSSの未使用分を削減する
- 未使用のJavaScriptを削減する 省資源 (ms)
- 未使用のJavaScriptの保存を削減する
- 次世代フォーマットでの画像配信 省略量(ms)
- 次世代フォーマットで画像を提供する 省資源化
- テキスト圧縮を有効にする 保存量(ms)
- テキスト圧縮保存を有効にする
- 必要なOriginの節約にプリコネクト
- サーバー応答時間(TTFB) (ms)
- サーバー応答時間(TTFB)区分(ms)
- 複数リダイレクトの節約量 (ms)
- プリロード・キー・リクエストの節約量 (ms)
- アニメーション画像にビデオ形式を使用する 省エネルギー (ms)
- アニメーション画像の保存には動画形式を使用する
- 画像最適化の総削減量(ms)
- レガシーJavaScriptをモダンブラウザのセービングに提供しないようにする
診断結果
- DOM要素数
- JavaScript実行時間(秒)
- JavaScript実行時間カテゴリ
- 効率的なキャッシュポリシーの節約
- メインスレッド作業の最小化(秒)
- メインスレッドのワークカテゴリの最小化
- Webfontの読み込み中にテキストが表示されたままになる
- 画像要素に明示的な幅と高さを指定しない
- 大きなレイアウトシフトを避ける
各指標、機会、診断の定義については、Lighthouseによる説明をご覧ください。
以下の方法で絞り込む
上記の各機会や診断の定義や説明については、Lighthouseのパフォーマンス監査ガイドをお読みください。
節約の可能性がある速度機会、ソースページ、リソースURLは、「Reports > PageSpeed(レポート > PageSpeed)」メニューから一括でエクスポートすることができます。

PageSpeed InsightsのAPI制限について
APIは1日25,000クエリ、1ユーザーあたり100秒間に60クエリに制限されています。SEOスパイダーは、この制限内に収まるようにリクエストの速度を自動的にコントロールします。
APIダッシュボードの’quotas’セクションで、API使用量のクォータを確認してください。
PageSpeed InsightsのAPIエラー
PSI Status 列は、ある URL に対する API リクエストが成功したか、エラーが発生したかを示す。「error(エラー)」は通常、ウェブインターフェースを反映しており、同じエラーとメッセージが表示されます。

よくあるエラーメッセージは次の2つです。
- “500: リクエストを処理できません: このエラーは一般にウェブインターフェースで再現可能で、私たちのテストによると、PSI API がリクエストを処理できないことが時折あり、おそらく全体的な負荷容量が原因であることが示唆されています。この問題が発生した場合、ウェブインターフェイスで再び利用可能になるまで10分間クロールを一時停止し、右クリックして URL を「再スパイダー」することを推奨します。これにより、選択された URL の PSI データが再要求され、他の URL のクロールと API データの要求が継続されます。
- “500:Lighthouseがエラーを返しました: errored_document_request.Lighthouseは要求されたページを確実にロードすることができませんでした。”- このエラーは通常ウェブインターフェースで再現可能で、SEOスパイダーやAPIの問題ではなく、PSIが実施したLighthouse監査に直接関係するものです。残念ながら、これらのURLを「再スパイダー」してAPIデータを再リクエストしても、一般的には何の役にも立ちません。経験したエラーについてGoogleのメーリングリストに直接フィードバックするか、Stack Overflow経由で質問することができます。
詳しくは、PageSpeed Insights API Errorsに関するFAQをご覧ください。
マジェスティック
Configuration > API Access > Moz(設定 > APIア+ `tt665クセス > Majestic)
Majesticを使用するには、APIからデータを取得するためのサブスクリプションが必要です。その後、「Configuration > API Access > Majestic(設定 > APIアクセス > Majestic)」に移動し、「generate an Open Apps access token」リンクをクリックする必要があります。

その後、Majesticに移動し、Screaming Frog SEOスパイダーへのアクセスを「許可」する必要があります。
その後、Majesticから固有のアクセストークンが付与されます。

このトークンをコピーして、MajesticのウィンドウのAPIキーボックスに入力し、「connect(接続)」をクリックします。

その後、URL、サブドメイン、ドメインのいずれかのレベルで、データソース(最新または履歴)と指標を選択することができます。
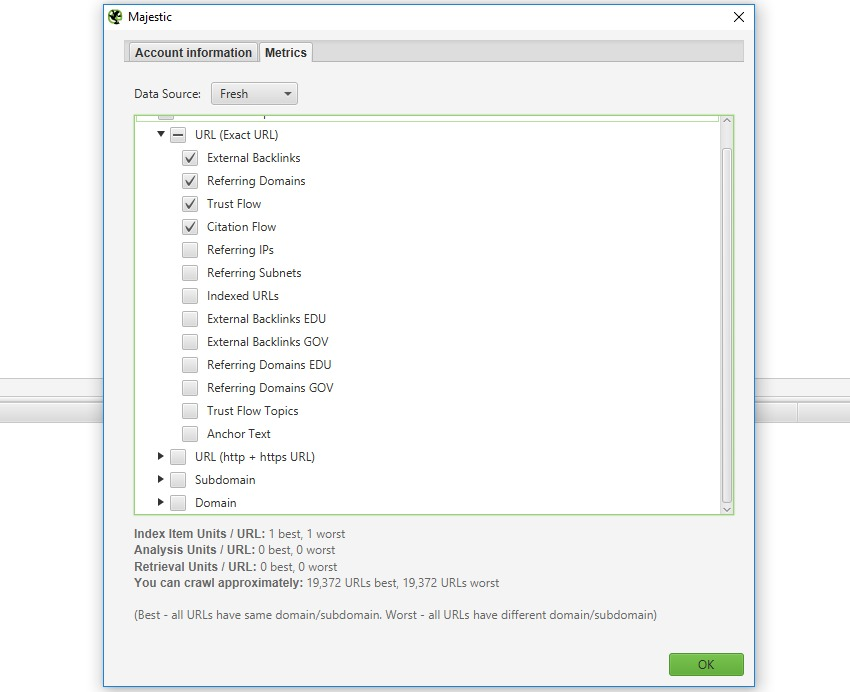
その後、「start(開始)」をクリックしてクロールを実行すると、データは自動的にAPI経由で取得され、「link metrics(リンク指標)」と「internal(内部)」タブで確認することができます。

Ahrefs
Configuration > API Access > Ahrefs(設定 > APIアクセス > Ahrefs)
Ahrefsを利用するには、APIからデータを取得するためのサブスクリプション契約が必要です。
その後、「Configuration > API Access > Ahrefs(設定 > APIアクセス > Ahrefs)」に移動し、「generate an API access token(APIアクセストークンを生成する)」リンクをクリックする必要があります。

その後、Ahrefsに移動し、Screaming Frog SEOスパイダーへのアクセスを「allow(許可)」する必要があります。

その後、Ahrefsから固有のアクセストークンが与えられます(ただし、Screaming Frogのドメインでホストされています)。

「We Missed Your Token(トークンで失敗しました)」というメッセージが表示された場合は、こちらのFAQの指示に従ってください。次に、このトークンをコピーしてAhrefsウィンドウのAPIキーボックスに入力し、「connet(接続)」をクリックしてください。
そして、URL、サブドメイン、ドメインのいずれかのレベルで取得したい指標を選択することができます。

その後、「start(開始)」をクリックしてクロールを実行すると、データは自動的にAPI経由で取得され、「link metrics(リンク指標)」と「internal(内部)」タブで確認することができます。
MOZ
Configuration > API Access > Moz(設定 > APIアクセス > Moz)
Mozscape API からデータを取得するには、Moz アカウントが必要です。
Moz は無料の限定 API と、より多くのメトリクスを高速に取得できる有料の API を提供しています。これは標準的な Moz PRO アカウントとは別のサブスクリプション契約が必要であることに注意してください。
API にアクセスするには、無料アカウントまたは有料サブスクリプションのいずれかを使用して、Moz アカウントにログインしてAPI IDと秘密鍵を表示する必要があります。
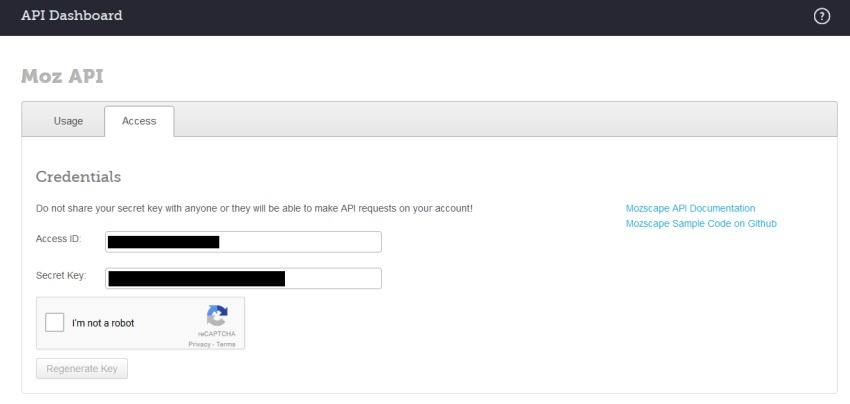
Moz のウィンドウの「Configuration > API Access > Moz(設定 > API アクセス > Moz)」にあるそれぞれの API キーボックスにアクセス ID とシークレットキーの両方をコピーして入力し、アカウントの種類(「free(無料)」または「paid(有料)」)を選択して、「connect(接続)」をクリックします。

次に、無料または有料プランに基づいて、利用可能なメトリクスを選択することができます。URLレベル、サブドメインレベル、ドメインレベルのいずれかを選択するだけで、測定値を取得できます。

その後、「start(開始)」をクリックしてクロールを実行すると、データは自動的にAPI経由で取得され、「link metrics(リンク指標)」と「internal(内部)」タブで確認することができます。
各種認証
Configuration > Authentication(設定 > 認証)
SEOスパイダーは、Basic認証とDigest認証を含む標準認証と、Webフォームベースの認証の2つの認証方式をサポートしています。
ログインのやり方は、ビデオガイドをご覧ください。
ベーシック認証とダイジェスト認証
Basic認証とDigest認証は設定不要で、ログインが必要なページをクロールした際に自動的に検出されます。Webサイトを訪問し、ブラウザがユーザー名とパスワードを要求するポップアップを表示した場合、それがBasic認証またはDigest認証となります。ログイン画面がページ自体に含まれている場合は、次のセクションで説明するWebフォーム認証になります。
多くの場合、開発中のサイトも同様にrobots.txtを介してブロックされるので、これがそうでないことを確認するか、「robots.txtを無視する設定」を使用します。その後、ステージングサイトのURLを挿入し、クロールすると、Webブラウザで行うのと同じように、ユーザー名とパスワードを要求するポップアップボックスが表示されます。

認証情報を入力すると、通常通りクロールが行われます。
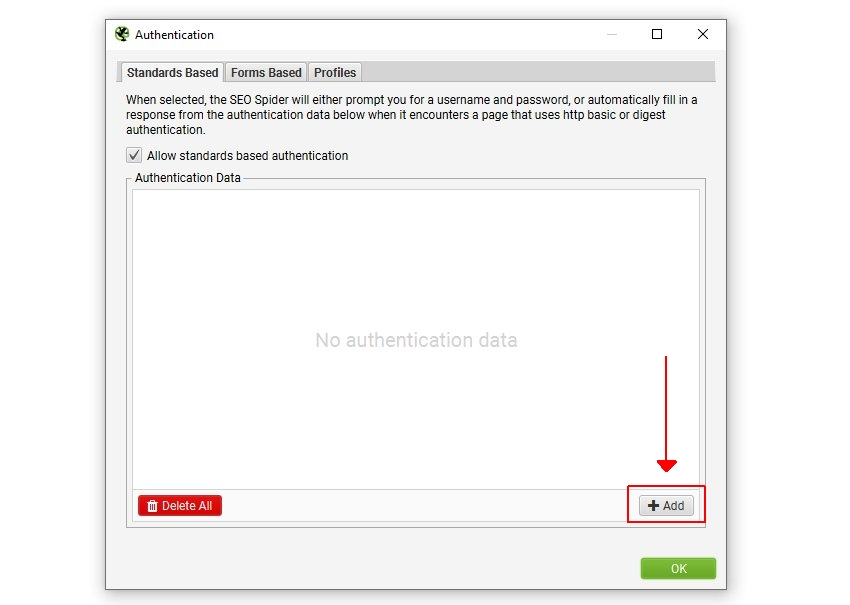
また、「Config > Authentication(設定 > 認証)」でログイン情報を事前に入力し、「標準ベース」タブで「add(追加)」をクリックすることもできます。
次に、URL、ユーザー名、パスワードを入力します。
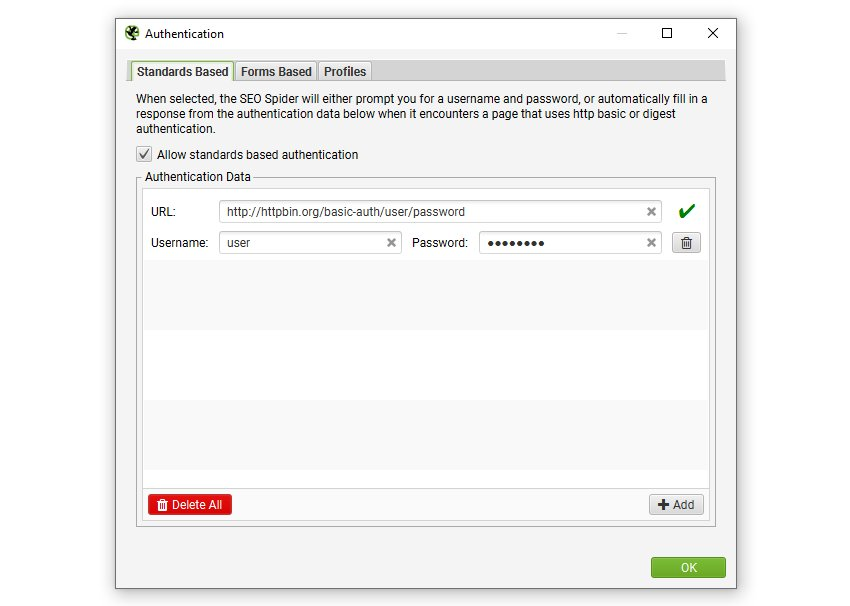
認証コンフィグに入力すると、削除されるまで記憶されます。
この機能にはライセンスキーは必要ありません。以下のページで、ブラウザやSEOスパイダーで認証の仕組みを確認してみてください。
▼基本認証
ユーザー名:ユーザー
パスワード:パスワード
▼ダイジェスト認証
ユーザー名:ユーザー
パスワード:パスワード
Webフォーム認証
その他、閲覧やクロールを行うために認証用のCookieでログインする必要があるWebフォームやエリアがあります。 SEOスパイダーでは、SEOスパイダー内蔵のChromiumブラウザ内でこれらのWebフォームにログインし、クロールすることができます。この機能を使用するにはライセンスが必要です。
ログインするには、「Configuration > Authentication(設定 > 認証)」に移動し、「Forms Based(フォームベース)」タブに切り替え、「add(追加)」ボタンをクリックし、クロールしたいサイトのURLを入力すると、ブラウザがポップアップし、ログインできるようになります。
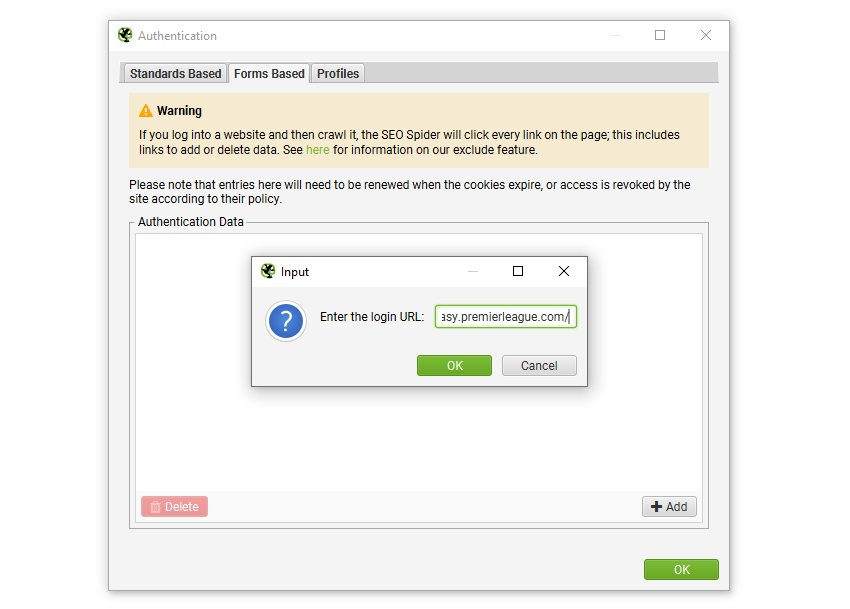
この機能を使用する前に、ユーザーガイドのWebフォームのパスワード保護されたサイトのクロールに関するガイドをお読みください。また、一部のWebサイトでは、ログイン時にJavaScriptのレンダリングを有効にしないとクロールできない場合があります。
注意 – これは非常に強力な機能ですので、責任を持って使用してください。SEOスパイダーはページ上のすべてのリンクをクリックします。ログインしている場合は、ログアウト、記事の作成、プラグインのインストール、データの削除などのリンクが含まれる場合があります。
認証プロファイル
認証プロファイルタブでは、スケジューリングや コマンドラインで使用する認証設定をエクスポートすることができます。
つまり、SEOスパイダーが自動クロールを行うための標準やウェブフォームベースの認証にログインすることが可能なのです。
ユーザーインターフェースで標準ベース認証またはWebフォーム認証を行った場合、「Profiles(プロファイル)」タブにアクセスし、.seospiderauthconfigファイルをエクスポートすることができます。
この設定は、スケジューリング時に「start options(スタートオプション)」タブで指定するか、CLIオプションで説明したコマンドライン用の「auth-config」引数で指定します。

注意 – Webサイトによってはログイントークンが失効したり、2FAが導入されている場合があるため、自動化されたWebフォーム認証が常に機能することを保証するものではありません。
トラブルシューティング
フォームベース認証は、設定されたユーザーエージェントを使用します。
ログインできない場合は、Chromeや他のブラウザで試してみてください。
メモリ割り当て
Configuration > System > Memory Allocation(設定 > システム > メモリ割り当て)
SEOスパイダーはJavaを使用しており、起動時にメモリの確保が必要です。SEOスパイダーの初期設定では、32ビットマシンで1GB、64ビットマシンで2GBのメモリが使用できます。
メモリ割り当てを増やすと、SEOスパイダーはより多くのURLをクロールできるようになり、特にRAMストレージモードでは、データベースへの保存も可能になります。
OSや他のアプリケーションが動作できるように、物理的なマシンの総メモリ量より2gb以上少ないメモリ割り当てに設定することをお勧めします。
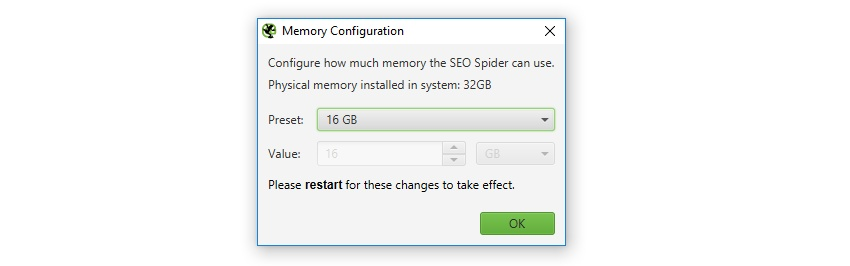
大規模なWebサイトのクロール、メモリ割り当て、利用可能なストレージオプションについて詳しく知りたい方は、大規模なWebサイトのクロールに関するガイドをご覧ください。
ストレージモード
Configuration > System > Storage Mode(設定 > システム > ストレージモード)
SEOスパイダーは設定可能なハイブリッドエンジンを使用しており、ユーザーはクロールデータをRAMに保存するか、データベースに保存するかを選択することができます。

SEOスパイダーの初期設定では、データの保存と処理に、ハードディスクではなくRAMを使用します。これはスピードや柔軟性といった素晴らしい利点がありますが、デメリットもあります。特に、大規模なクロールが必要な場合です。
SEOスパイダーは、SSDをお使いの場合、「Database Storage’ mode (under ‘Configuration > System > Storage(データベースストレージ」モード(「設定」→「システム」→「ストレージ」))を選択することで、クロールデータをディスクに保存するように設定することもできます。
基本的には、どちらのストレージモードでも実質的に同じクロール体験を提供することができ、リアルタイムでのレポート作成、フィルタリング、クロールの調整が可能です。しかし、いくつかの重要な違いがあり、理想的なストレージはクロールのシナリオとマシンの仕様に依存することにります。
メモリストレージ
メモリ保存モードでは、ほぼすべてのセットアップで超高速かつ柔軟なクロールが可能です。
しかし、マシンのRAM容量はハードディスク容量よりも少ないため、SEOスパイダーは一般的に500,000URL以下のWebサイトをメモリストレージ・モードでクロールするのに適していることを意味します。
適切なセットアップを行えば、これ以上のクロールが可能で、クロールするWebサイトのメモリ消費量にもよります。大まかな目安として、8GBのRAMを搭載した64ビットマシンで、一般的に数十万件のURLをクロールすることができます。
メモリ保存モードは、小規模なWebサイトに適したオプションであると同時に、SSDを搭載していないマシンや、ディスク容量があまりない場合にも推奨されます。
データベースストレージ
SSDをお持ちのユーザーや、大規模なクロールを行う場合の初期設定ストレージとして推奨しています。
データベースストレージモードでは、設定されたメモリに対してより多くのURLをクロールすることができ、SSD(ソリッドステートドライブ)を搭載したセットアップではRAMストレージに近いクロール速度が得られます。
データベース保存モードのメリットを存分に発揮します。
- より大きな規模でのクローリング
- 大きなクロールを開くと早い効果。
- 電源が切れたり、誤ってクリアしたり、クロールを閉じたりしてもデータが失われることはありません。クロールは自動保存され、「File > Crawls(ファイル > クロール)」で再び開くことができます
- クロール比較と変更検出機能は、このモードでのみ使用可能
- 初期設定のクロール上限は500万URLですが、これは厳しい制限ではなく、SEOスパイダーは(適切なセットアップをすれば)もっと多くのクロールが可能です。例えば、500gbのSSDと16gbのRAMを搭載したマシンでは、およそ1000万URLまでクロールできるはずです。
推奨はしませんが、高速なハードディスクドライブ(HDD)ではなく、ソリッドステートディスク(SSD)を使用している場合、このモードでもより多くのURLをクロールすることができます。ただし、ハードディスクの書き込み・読み込み速度がクロールのボトルネックになるため、クロール速度もインターフェース自体も大幅に遅くなります。
ネットワークドライブの使用はサポートされていません。これは、非常に遅くなるほか接続が不安定になります。DropboxやOneDriveなど、リモートで同期するローカルフォルダーを使用することは、これらのプロセスがファイルをロックするため、サポートされていません。Vaultドライブもサポートされていません。
クロール中にマシン上で作業を行う場合、マシンのパフォーマンスにも影響を与えるため、負荷に対応するためにクロール速度を落とす必要があるかもしれません。SSDは非常に高速なので、一般的にこの問題は発生しません。このため、小規模なクロールでも大規模なクロールでも、「database storage(データベースストレージ)」を初期設定として使用することができます。
ストレージモードについてのビデオガイドをご覧ください。
トラブルシューティング
JDK-8205404により、ExFAT/MS-DOS(FAT)ファイルシステムはmacOSではサポートされていません。
プロキシ
Configuration > System > Proxy(設定 > システム > プロキシ)
プロキシ機能は、SEOスパイダーがプロキシサーバーを使用するように設定するためのオプションです。
プロキシのアドレスとポートを設定ウィンドウで設定する必要があります。プロキシサーバーを無効にするには、「Use Proxy Server(プロキシサーバーを使用する)」オプションのチェックを外してください。
- プロキシサーバーは1台のみ設定可能です。
- 変更を有効にするには、再起動する必要があります。
- 例外を設けることはできません。すべてのHTTP/HTTPSトラフィックがプロキシを経由するか、あるいはまったく経由しないかのどちらかです。
- プロキシによっては、フォームベースの認証により、クロール前にログイン情報の入力を要求する場合があります。
言語
Configuration > System > Language(設定>システム>言語)
GUIは、英語、スペイン語、ドイツ語、フランス語、イタリア語で利用可能です。起動時にマシンで使用されている言語を検出し、初期設定でその言語を使用するようになります。
言語は、「Configuration > System > Language(設定 > システム > 言語)」からツール内で設定することも可能です。

今後、さらに多くの言語に対応する可能性がありますので、対応してほしい言語があれば、サポートを通じてお知らせください。
モード
Mode > Spider / List / SERP(モード > スパイダー/リスト/SERP)
スパイダーモード
これはSEOスパイダーの初期設定のモードです。このモードでは、SEOスパイダーはWebサイトをクロールし、リンクを集め、URLを様々なタブとフィルターに分類します。好きなURLを入力し、「start(開始)」をクリックするだけです。
リストモード
このモードでは、事前に定義されたURLのリストをチェックすることができます。
このリストは、単純なコピー&ペースト、.txt, .xls, .xlsx, .csv, .xml ファイルなど、さまざまなソースから取得することが可能です。ファイルは、http:// または https:// のプレフィックス付き URL を調査し、その他のテキストはすべて無視されます。
例えば、Adwordsのダウンロードファイルを直接アップロードすると、すべてのURLが自動的に検出されます。

サイトの移行を行い、URLをテストしたい場合は、SEOスパイダーが最終的な目的地のURLを見つけることができるように、「always follow redirects(常にリダイレクトを辿る)」設定を使用することを強くお勧めします。リダイレクトチェーンレポートで確認するのがベストですが、詳しくは「リダイレクトの監査方法」ガイドをご覧ください。
リストモードでは、クロール深度の設定が0に変更され、アップロードされたURLのみがチェックされるようになります。これらのURLからのリンクをチェックしたい場合は、「Configuration > Spider(設定 > スパイダー)」の「Limits(制限)」タブでクロール深度を1以上に調整します。リストモードでは、初期設定でrobots.txtを無視するように設定されており、リストがアップロードされている場合、リスト内のすべてのURLをクロールすることを意図していると考えられます。
リストモードのデータをアップロードした順番でエクスポートしたい場合は、ユーザーインターフェースの上部にある「upload(アップロード)」と「start(開始)」ボタンの隣に表示される「export(エクスポート)」ボタンを使用します。

エクスポートされるデータは、同じ順番で、重複や修正されたものも含め、アップロード元のURLと全く同じものがすべて含まれます。
リストモードでより高度なクロールを行う方法を知りたい方は、リストモードの使い方ガイドをご覧ください。
SERPモード
このモードでは、ページタイトルとメタディスクリプションを直接SEOスパイダーにアップロードして、ピクセル幅(と文字数!)を計算することができます。このモードではクロールは行われませんので、Webサイト上でライブにする必要はありません。
つまり、SEOスパイダーからページのタイトルと説明をエクスポートし、(ツール自体ではなく、お好みで)エクセルで一括編集した後、再びツールにアップロードして、GoogleのSERPにどのように表示されるかを理解することができるのです。
レポート」の下に、ページのタイトルと説明を再アップロードするために必要な形式の「SERPサマリー」レポートが新たに追加されました。「URL」「タイトル」「説明文」の3つのヘッダが必要なだけです。
▼例

.txt、.csv、Excelファイルでアップロードすることができます。
比較する
このモードでは、2つのクロールを比較し、時間の経過とともにタブやフィルターにどのようにデータが変化したかを確認することができます。チュートリアルの「クロールを比較する方法」を参照してください。

比較機能は、データベースストレージモードでライセンスがある場合のみ利用可能です。まだ移行していない場合は、「Config > System > Storage Mode(設定 > システム > ストレージモード)」で「Database Storage(データベースストレージ)」を選択するだけで、簡単に移行することができます。
クロールの比較には、次の2つのオプションがあります。
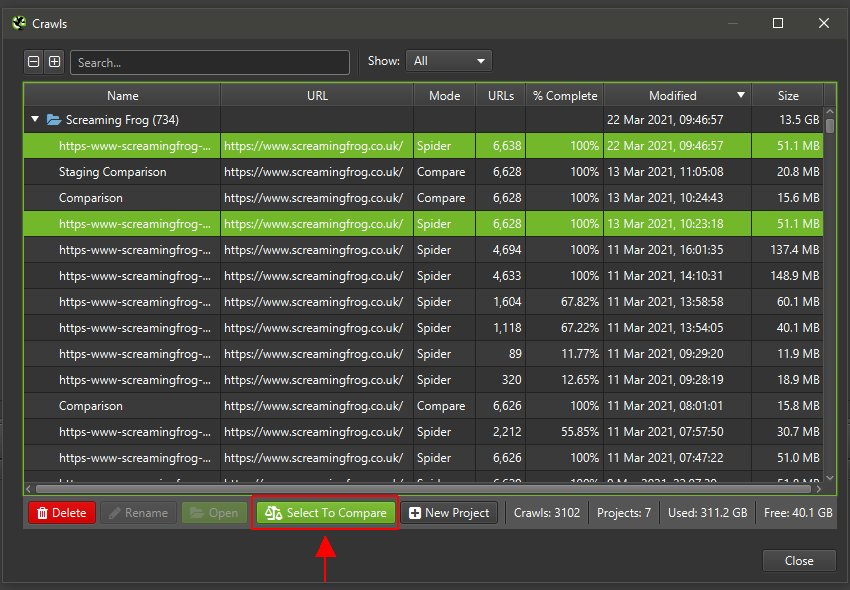
1) 「Mode > Compare(モード > 比較)」で「compare(比較)」モードに切り替え、上部メニューから「Select Crawl(クロールを選択)」をクリックして、比較したいクロールを2つ選びます。

2) 「spider(スパイダー)」または「list(リスト)」モードで「File > Crawls(ファイル > クロール)」と進み、2つのクロールをハイライトして「Select To Compare(比較対象として選択)」すると、「compare(比較)」モードに切り替わります。
その後、「歯車」アイコンをクリックするか、「Config > Compare(設定 > 比較)」をクリックして、比較設定を調整することができます。これにより、変化検出のために分析する要素を追加で選択することができます。
次に「compare(比較)」をクリックすると、クロール比較分析が実行され、右側の概要タブに現在と過去のクロールデータが入力され、変更を加えて表示されます。
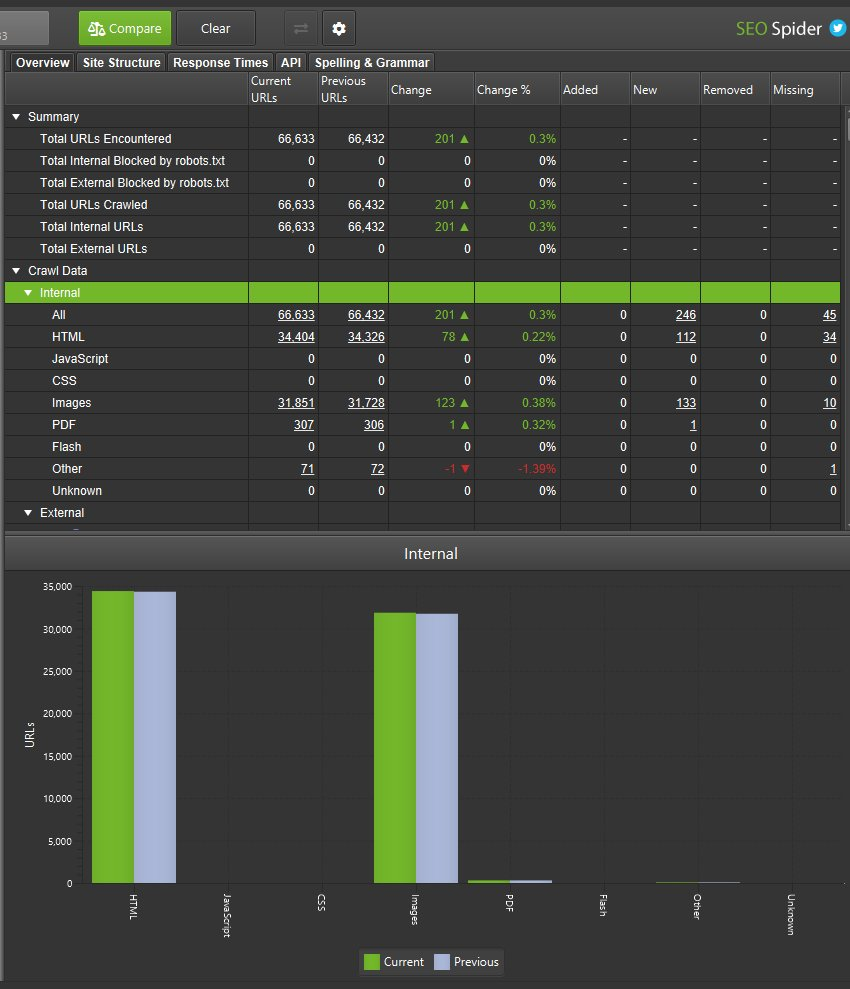
列の数字をクリックすると、どのURLに変更があったかを確認できます。また、マスターウィンドウのビューでフィルターを使用して、現在と過去のクロール、または追加、新規、削除、見つからないURLの切り替えが可能です。
4つのカラムとフィルターがあり、タブやフィルターに移動するURLをセグメント化することができます。
基本的に、「add(追加)」と「removed(削除)」は現在のクロールと以前のクロールの両方に存在するURLで、「new(新規)」と「missing(欠落)」はどちらかのクロールにのみ存在するURLです。
クロールの比較が完了すると、小さな比較ファイルが「File > Crawls(ファイル>クロール)」に自動的に保存され、解析を再度実行しなくても開いて見ることができるようになります。
このファイルは、比較された2つのクロールを利用します。したがって、比較を表示するためには、両方とも保存されている必要があります。比較の片方または両方のクロールを削除すると、比較にアクセスできなくなります。
詳しくは、チュートリアルの「クロールの比較方法」をご覧ください。