

Screaming Frog SEO SpiderはSEO対策をするうえで欠かせない分析ツールです。
ただし、英語表記のため「調べても英語だから分からない」「自分好みの抽出方法が思いつかない」といった現象に陥ることもあります。
知っておくと便利な小技集を掲載するので、「これだ!!」というコマンドや設定に巡り合うかもしれません。



\Twitterやブログで紹介されると喜びます/

■ プロフィール:はっち (hacchi_web)
- SEO会社のセカンドオピニオンとして従事
- 1,000以上のWebサイトをSEO分析
- スマートにSEOしたいが、時にはフィジカルSEOで対応
- 基本は温厚、仁義を通さない相手だと気性が荒い
- 趣味:SEO、アウトドア、温泉
クロールデバイスをモバイル(SP)に変更したい
Screaming Frog SEO Spiderのクロール初期設定は、パソコン(PC)デバイスです。
Webサイトの修正や作業中はPC画面を見ることが多いですが、BtoB業界でない限り利用ユーザーの多くはモバイル(SP)でしょう。
2021年のインターネット利用率(個人)は82.9%となっており(図表3-8-1-2)、端末別のインターネット利用率(個人)は、「スマートフォン」(68.5%)が「パソコン」(48.1%)を20.4ポイント上回っている。
総務省
ましてや、Googleのクロール基準もモバイル(SP)を優先的にすると開示しています。
Google のインデックス登録とランキングでは、スマートフォン エージェントでクロールしたモバイル版のサイト コンテンツを優先的に使用します。これをモバイルファーストインデックスと呼びます。
モバイルサイトとモバイルファースト インデックスに関するおすすめの方法
つまり、作業している画面(PC)とGoogleが把握する画面(SP)にズレが起きてしまい、Googleが意図していない理解をしてしまう可能性を秘めています。
そこで、Screaming Frog SEO SpiderもGoogleが優先としているモバイル(SP)向けのクローラーに変更する必要があります。
「Configuration」→「User-Agents」→「Preset User-Agents」→「Googlebot(smartphone)」に変更
毎回、手順1を行うのは無駄な作業なので、次回立ち上げ以降は全てモバイル(SP)向けのクローラーとして設定します。
「File」 → 「configuration」 → 「Save Current Configuraion as default」で設定保存
一度設定すれば、毎回クローラー処理を変更する必要もないので手間が減ります。さらに、ずっとモバイル(SP)向けのクローラーとして分析してくれるので、Googleに伝達する内容としても齟齬がなくなります。
画像やPDFファイルを除外して調査したい
Screaming Frog Seo Spiderは、Webサイト内の全てのファイルをクロール・解析してくれます。
ECサイトやポータルサイトといったDBサイト、あるいは、大規模なWebサイトの場合は、ファイル量が多すぎるあまりにScreaming Frog SEO Spiderの処理に時間を要する場合があります。

見たいのはソコじゃないんだ!画像とかPDFファイルを除外したいんだけど、どうにかならない?
そんな時は、クロール対象から任意のファイルを除外しましょう!
「Configuration」→「exclude」に移動
任意のファイルを、決められたルールで設定すればクロール対象から除外される
ここでは、画像やPDFファイルを一括してクロール除外したい場合の記述を紹介します。
.*zip.*
.*pdf.*
.*jpg.*
.*JPG.*
.*jpeg.*
.*JPEG.*
.*png.*
.*PNG.*
.*gig.*
.*GIF.*
.*css.*
.*js.*その他、細かい対象ファイルやページはルールに従って除外すればOKです。
対象ディレクトリを除外してクロールしたい
画像やPDFではなく、/XXX/のディレクトリを除外して分析する場合にはどうする?
画像やPDFファイルの除外のように、対象ディレクトリを除外したい場合も設定可能です。
「Configuration」→「exclude」に移動
任意のディレクトリを、決められたルールで設定すればクロール対象から除外される
「hoge」ディレクトリを除外したい場合の記述は下記の通り。
https://test.com/hoge.*「.*」は、「それ以降全て」という意味なので、「exculde(除外)設定 → hoge以降」となります。
理解すれば簡単ですね♪
対象ディレクトリのみクロールしたい
対象ディレクトリだけに絞ってクロール・分析したい場合も、設定可能なの?
除外ではなく、対象ディレクトリに限定してクロール・分析することも可能です。
コーポレートサイトにぶら下がってる、サブディレクトリ運用型のオウンドメディアを調べたい時には有効ですね!
「Configuration」→「include」に移動
任意のディレクトリを、決められたルールで設定すればクロール対象に限定される
「hoge」ディレクトリに限定したい場合の記述は下記の通り。
https://test.com/hoge.*「.*」は、「それ以降全て」という意味なので、「inculde(含有)設定 → hoge以降」となります。
除外と同様に、理解すれば簡単ではないでしょうか!
対象ディレクトリ(階層)まで調査したい
特定のディレクトリ階層まで検索したい場合の抽出方法は、下記の手順で設定すればOK。
「Configuration」→「exclude」に移動
何階層目までか?を決めた上で、規定のルールに従って入力
特徴は、「含める」ではなく「除外設定」にすること。
下記設定では、第3階層まで。
https://test.com/.*/.*/当サイトであれば、画像のような抽出結果です。
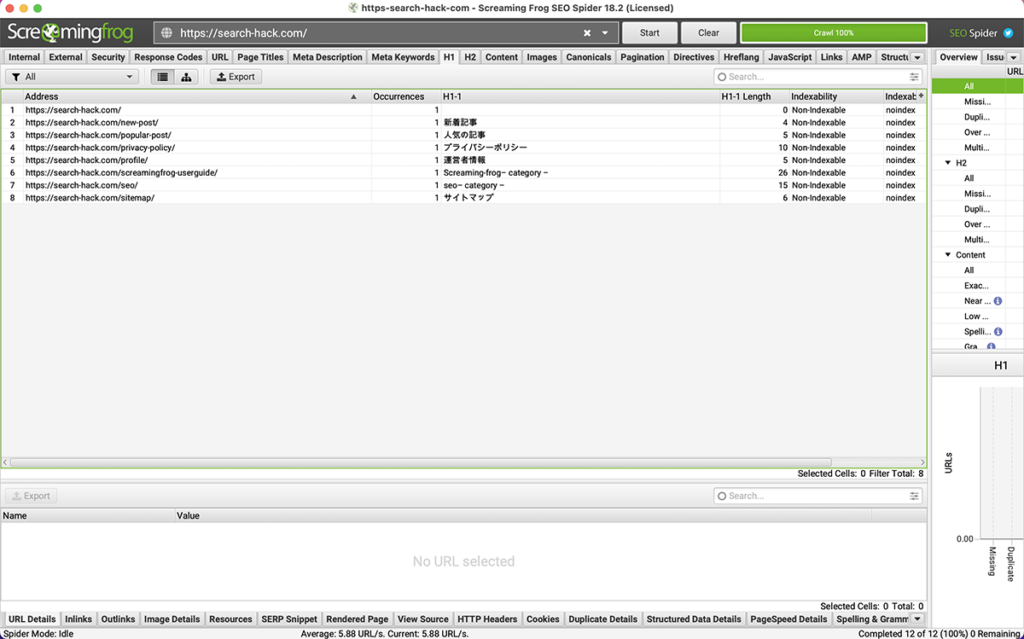
定められた範囲内での調査であれば、非常に重宝しますね!
任意のテキストがどのページに含まれているか
Screaming Frog SEO Spiderは、Webページのソースコードを高速で読み込むため、タグ系だけじゃなくテキストも抽出可能です。
Webサイト内のどこかに「みかん食べたい」というテキストがあるページを抜き出したい!
そんな時には、重宝する検索方法です。
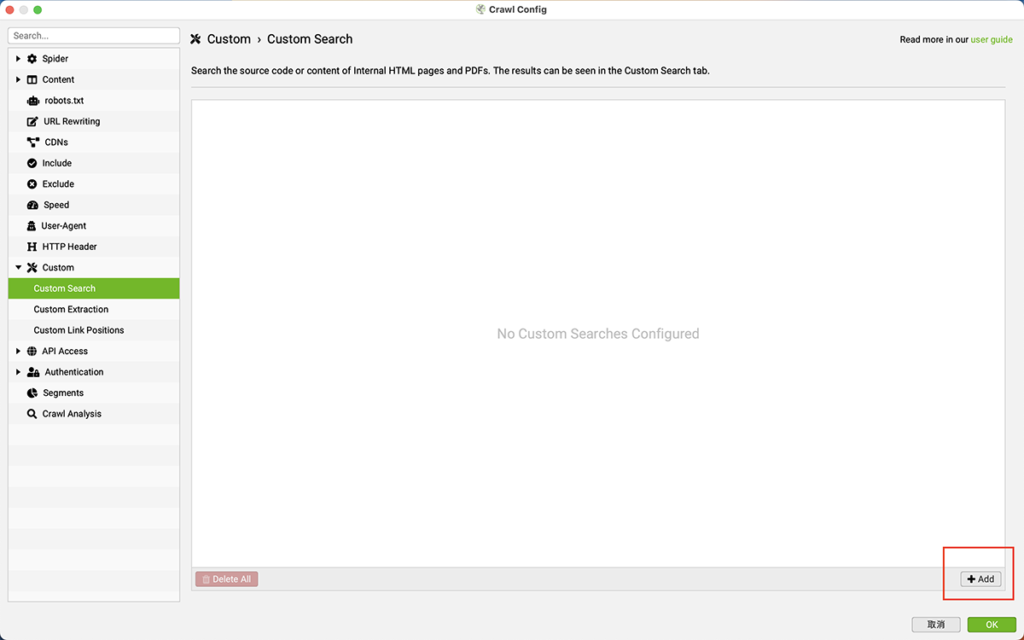
「Configuration」 > 「Custom」 > 「Custom Search」に移動し、「Add」をクリック
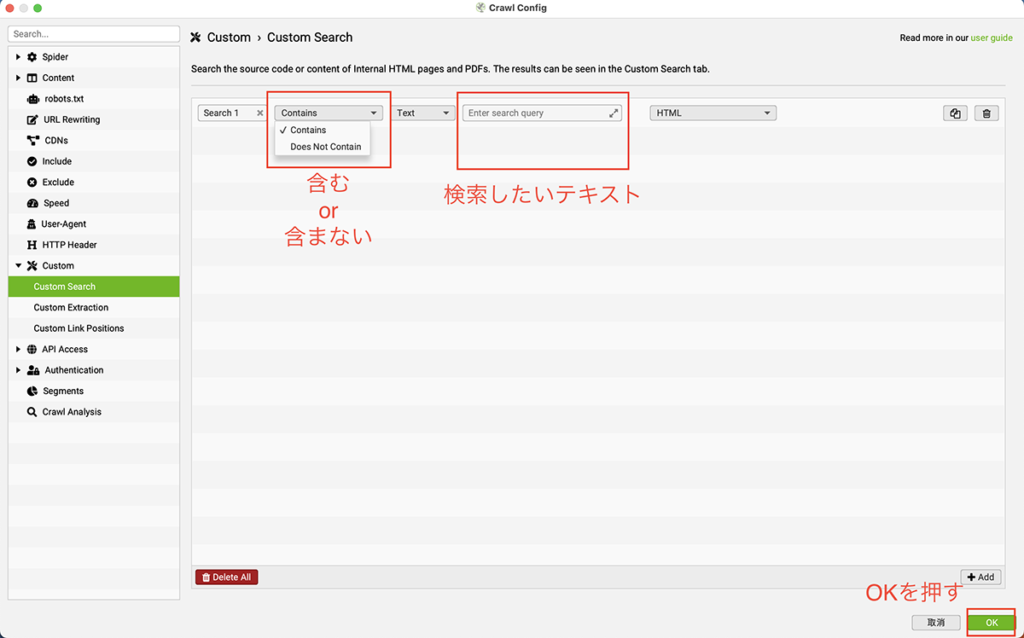
「含む」または「含まない」の選択も含めて設定
これだけで、任意のテキストが含まれているページを一括で取得できます。
ココで注意点があって、どこに属するテキストなのか?によって下記のように変更する必要があります。
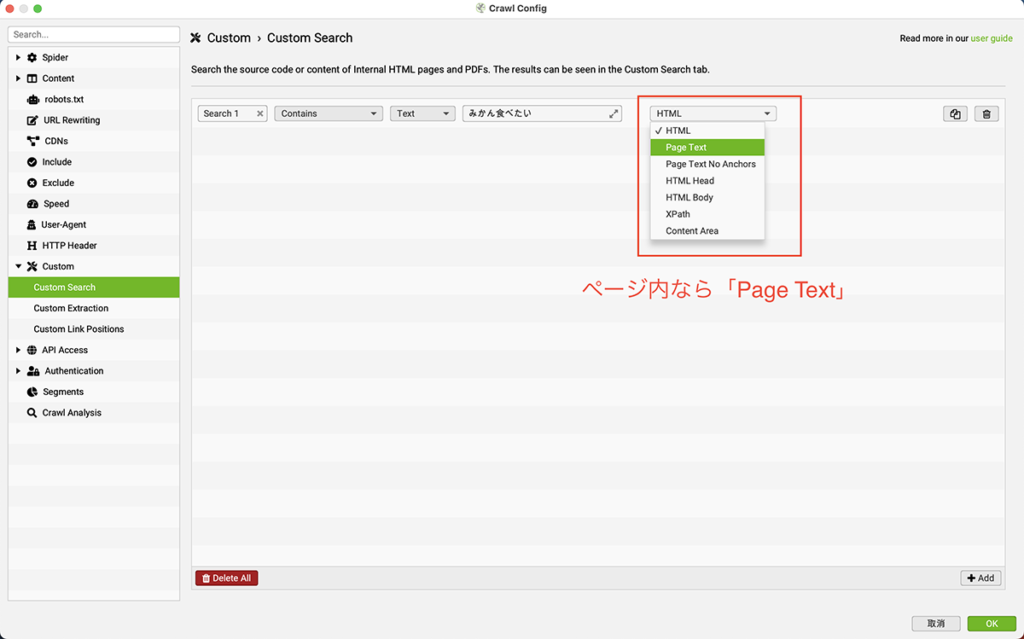
正しく設定したうえで再クロールすると、選んだテキストが抽出されるはずです。
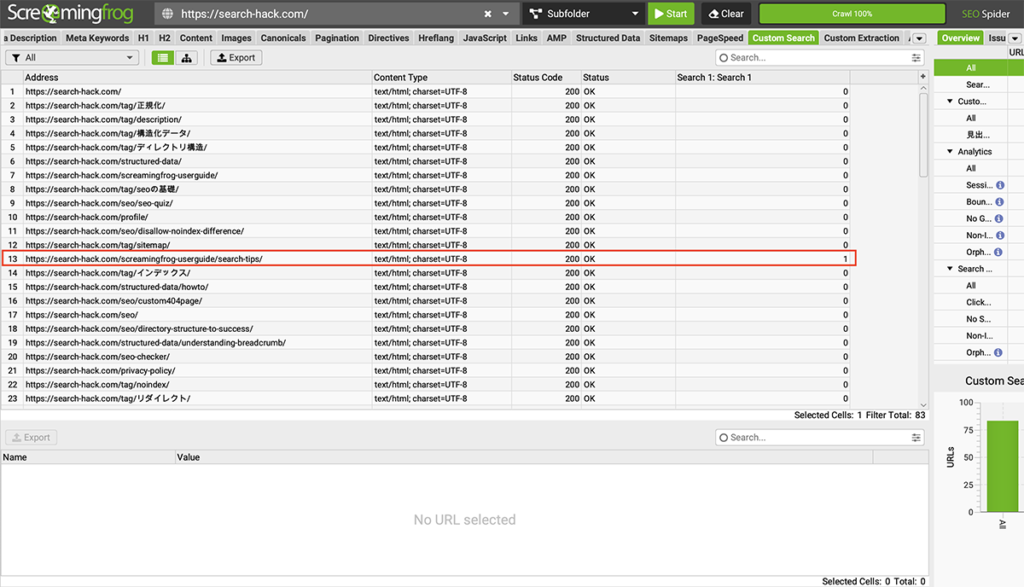
この場合、「 https://search-hack.com/screamingfrog-userguide/search-tips/ 」に1箇所だけあるということですね。
※つまり、当ページにだけ存在。
ソースコード内の指定した範囲内の文字列やタグを抽出したい
テキスト抽出だけでなく、ソースコード内に含まれた文字列を一気に抽出する方法もあります。
例えば、下記のコードのように<div class=”hoge”>と</div>の間に挟まれている複数のテキストを抽出することが可能です。
<div class="hoge">XXXXXX</div>
<div class="hoge">WWWWW</div>
<div class="hoge">ZZZZZ</div>
↓↓
XXXXXX
WWWWW
ZZZZZ複雑なWebサイトを構築していて、同じような仕様をしているけど一部だけ違うというパターンに活用できます。
「Configuration」 > 「Custom」 > 「Custom Extraction」に移動し、「Add」をクリック
「Regex」を選択し、「囲い込み始めの文字列 + .*? + 囲い込み終わりの文字列」を入力。
(例)<div class=”hoge”>(.*?)</div>
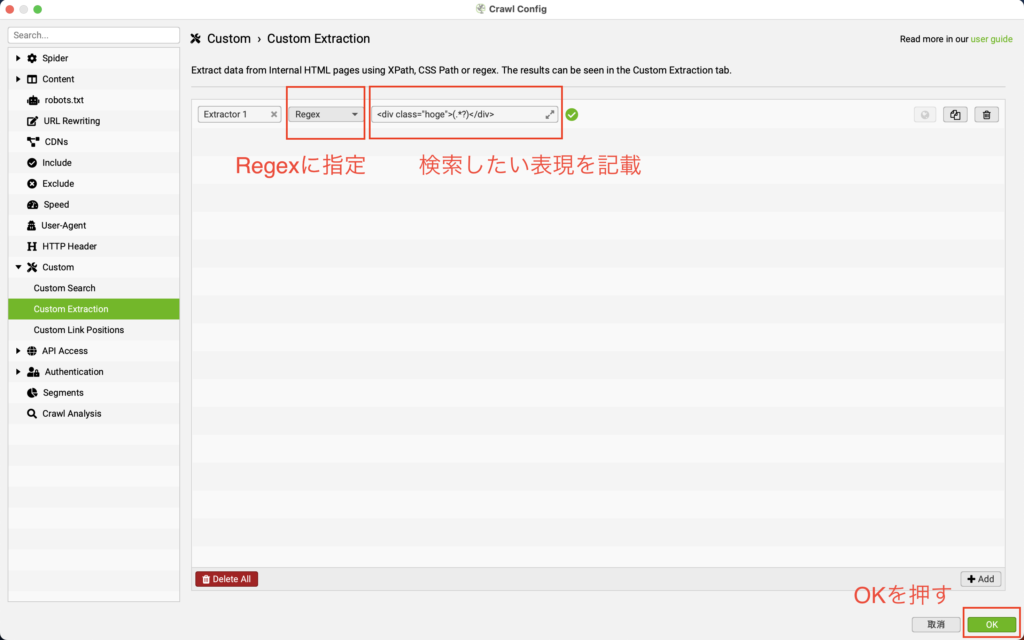
今回画像で示している「<div class=”hoge”>(.*?)</div>」なんていう表記は、当サイトでも使っていないので、再クロールしても表示はされません。
<title>(.*?)</title>例えば、上記のように指定すると当然タイトルタグで囲われた内容が表示されます。
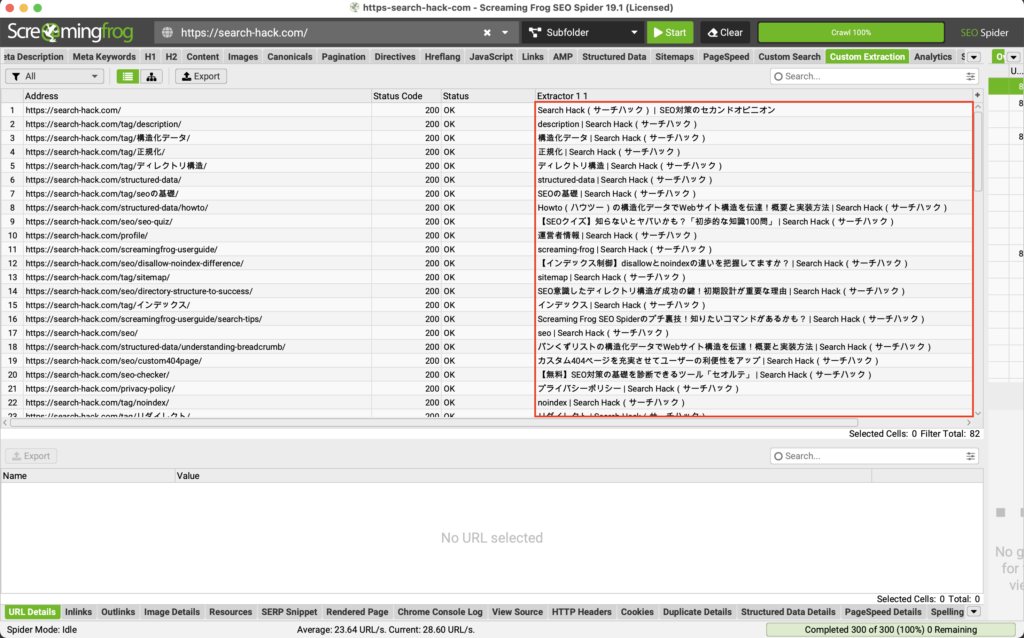
titleタグの中身をココで指定する人はいないと思いますが、例として捉えてください。