

2023年2月現在において、日本初となる『Screaming Frog SEO Spider』の日本語訳です。
Internal(内部)
Internalタブは、external、hreflang、structured dataタブを除く他のほとんどのタブで抽出されたすべてのデータを結合します。つまり、すべてのデータを包括的に表示し、さらに分析するために一緒にエクスポートすることができます。
「Internal(内部)」に分類されたURLは、クロールの開始ページと同じサブドメインにあります。URLは、「すべてのサブドメインをクロールする」設定、リストモード、またはCDN機能を使用することで、インターナルとすることができます。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address:URLのアドレス
- Content :URLのコンテンツタイプ
- Status Code : HTTPレスポンスコード
- Status : HTTPヘッダーレスポンス
- Indexability : URLがインデックス可能か、インデックス可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など
- Title 1 : ページに発見された(最初の)ページタイトル。
- Title 1 Length : ページタイトルの文字数です。
- Title 1 Pixel Width : ピクセル幅の記事で説明した、ページタイトルのピクセル幅です。
- Meta Description 1 : ページ上の(最初の)メタディスクリプションです。
- Meta Description Length 1 : メタディスクリプションの文字数の長さです。
- Meta Description Pixel Width: メタディスクリプションのピクセル幅です。
- Meta Keyword 1 : メタ・キーワード。
- Meta Keywords Length : メタキーワードの文字数です。
- h1 – 1 : ページ上の最初のh1(見出し)です。
- h1 – Len-1 : h1の文字数.
- h2 – 1: ページ上の最初のh2(見出し)です。
- h2 – Len-1 : Len-1 : h2の文字数です。
- Meta Robots 1 : URLにあるMeta robotsディレクティブ。
- X-Robots-Tag 1 : URLのX-Robots-tag HTTPヘッダーディレクティブを指定します。
- Meta Refresh 1 : メタリフレッシュのデータです。
- Canonical Link Element : 正規リンク要素データ。
- rel=”next” 1 : SEOスパイダーは、ページ分割された一連のURLの関係を示すために設計されたこれらのHTMLリンク要素を収集します。
- rel=”prev” 1 : SEOスパイダーは、ページ分割された一連のURLの関係を示すために設計されたこれらのHTMLリンク要素を収集します。
- HTTP rel=”next” 1 : SEOスパイダーは、ページ分割された一連のURLの関係を示すために設計されたこれらのHTTPリンクエレメントを収集します。
- HTTP rel=”prev” 1 : SEOスパイダーは、ページ分割された一連のURLの関係を示すために設計されたこれらのHTTPリンクエレメントを収集します。
- Size : Content-Length HTTP ヘッダーから取得した、リソースのサイズです。このフィールドが提供されない場合、サイズは 0 として報告されます。HTMLページの場合、これは(圧縮されていない)HTMLのサイズに更新されます。エクスポートの際、サイズはバイトで表示されるので、1,024で割ってキロバイトに変換してください。
- Word Count : HTMLマークアップを除く、bodyタグ内のすべての「単語」です。カウントは、「設定>コンテンツ>エリア」で調整可能なコンテンツエリアに基づいて行われます。デフォルトでは、ナビとフッターの要素は除外されています。HTML要素、クラス、IDを含めたり除外したりすることで、精緻なワードカウントを計算することができます。パーサーは無効な HTML に対して特定の修正を行うため、この計算を手動で実行した場合の数値とは異なる場合があります。また、レンダリングの設定も、どのようなHTMLを考慮するかに影響します。当社の単語の定義は、テキストをスペースで分割したものです。コンテンツの可視性(hidden に設定された div 内のテキストなど)は考慮されません。
- Text Ratio : ページ上のHTML bodyタグに含まれる非HTML文字(テキスト)の数を、HTMLページが構成する総文字数で割り、パーセントで表示したものです。テキスト比率。
- Crawl Depth : 開始ページからのページの深さ(開始ページから「クリック」された数)。リダイレクトは、ページの深さの計算において、現在1レベルとしてカウントされていることに注意してください。クロールの深さ。
- Link Score : 0-100の間の指標で、GoogleのPageRankと同様に、内部リンクに基づいてページの相対的な価値を計算します。このカラムを表示させるには、「クロール解析」が必要です。
- Inlinks : そのURLへの内部ハイパーリンクの数。「Internal inlinks」とは、クロール対象の同じサブドメインから所定の URL を指すアンカー要素内のリンクのことです。
- Unique Inlinks : そのURLへの「ユニークな」内部リンクの数。「Internal inlinks」とは、クロール対象の同じサブドメインから指定されたURLを指すアンカー要素内のリンクのことです。例えば、「ページA」が「ページB」に3回リンクしている場合、「ページB」に対するインリンクは3回、ユニークインリンクは1回とカウントされます。
- Unique JS Inlinks : JavaScript実行後にレンダリングされたHTMLにのみ存在する、URLへの「ユニークな」内部インリンクの数です。内部インリンク」とは、クロール対象の同じサブドメインから指定されたURLを指すアンカー要素内のリンクのことです。たとえば、「ページA」が「ページB」に3回リンクしている場合、「ページB」へのインリンクが3回、ユニークなインリンクが1回とカウントされます。
- % of Total : URLへのユニークな内部インリンク(200レスポンスHTMLページ)のパーセンテージです。内部インリンク」とは、クロール対象の同じサブドメインから指定されたURIを指すアンカー要素内のリンクのことです。
- Outlinks : そのURLからの内部アウトリンクの数。「Internal outlinks」とは、与えられたURLから、クロールされている同じサブドメイン上の他のURLへのアンカー要素のリンクのことです。
- Unique Outlinks(固有の内部発リンク) : そのURLからの「ユニークな(固有の)」内部発リンクの数です。「Internal outlinks」とは、あるURLからアンカー要素で、クロールされている同じドメインの他のURLへのリンクのことです。例えば、「ページA」から同じドメイン上の「ページB」に3回内部リンクしている場合、「ページB」への内部発リンクが3回、固有の内部発リンクは1回とカウントされます。
- Unique JS Outlinks : JavaScript実行後にレンダリングされたHTMLにのみ存在する、そのURLからのユニークな内部アウトリンクの数です。内部アウトリンク」とは、与えられたURLから、クロールされている同じサブドメイン上の他のURLへのアンカー要素内のリンクのことです。たとえば、「ページA」から同じサブドメイン上の「ページB」に3回リンクしている場合、「ページB」へのアウトリンクが3回、ユニークなアウトリンクが1回とカウントされます。
- External Outlinks(外部発リンク) : そのURLからの外部アウトリンクの数。「External outlinks」とは、指定されたURLから別のドメインへのアンカー要素のリンクのことです。
- Unique External Outlinks(固有の外部発リンク) : そのURLからの「ユニークな(固有の)」外部発リンクの数です。「External outlinks」とは、あるURLから別のドメインへのアンカー要素でのリンクのことです。たとえば、「ページA」から別のドメインの「ページB」に3回リンクしている場合、「ページB」への外部発リンクは3回、固有の外部発リンクは1回とカウントされます。
- Unique External JS Outlinks : JavaScript実行後にレンダリングされたHTMLにのみ存在する、URLからのユニークな外部アウトリンクの数です。外部アウトリンク」とは、与えられたURLから別のサブドメインへのアンカー要素内のリンクのことです。たとえば、「ページA」が別のサブドメインの「ページB」に3回リンクしている場合、これは3つの外部アウトリンクとカウントされ、「ページB」に対するユニークな外部アウトリンクは1つとなります。
- Closest Similarity Match : 最も近い類似性の一致。重複に近いURLの最も高い類似性のパーセンテージを示します。SEOスパイダーは、類似度90%で一致するニアディプリケートを特定しますが、これを調整して、より低い類似度の閾値を持つコンテンツを見つけることができます。例えば、あるページに対して2つのニアディプリケートページがあり、それぞれの類似度が99%と90%だった場合、99%がここに表示されます。この列を表示するには、「Config > Content > Duplicates’ で (一致率の有効)」 設定を選択し、’Crawl Analysis’ を実行する必要があります。選択した類似度閾値以上のコンテンツを持つURLのみがデータを含み、その他は空白のままです。したがって、「Config > Content > Duplicates(設定 > コンテンツ > 重複)」 と 「Near Duplicate Similarity Threshold」 の設定で調整しない限り、デフォルトではこの列には類似度90%以上のURLのデータのみが含まれることになります。
- No. Near Duplicates : クロールで発見された重複するURLのうち、「Near Duplicate Similarity Threshold」(デフォルトでは90%の一致)を満たすか超えるものの数。この設定は、「設定 > コンテンツ > 重複」で調整することができます。この列を表示するには、’Config > Content > Duplicates’ で ‘Enable Near Duplicates’ 設定を選択し、’Crawl Analysis’ を実行する必要があります。
- Spelling Errors : URLで発見されたスペルエラーの合計数です。この列を表示するには、「設定 > コンテンツ > スペル&グラマー」で「スペルチェックを有効にする」が選択されている必要があります。
- Grammar Errors : URLで発見された文法エラーの合計数です。この列を表示するには、「設定 > コンテンツ > スペル&グラマー」で「文法チェックを有効にする」を選択する必要があります。
- Language : スペルチェックと文法チェックに使用される言語。これはHTMLの言語属性に基づいていますが、’設定 > コンテンツ > スペルと文法’で言語を設定することもできます。
- Hash : MD5アルゴリズムを使用したページのハッシュ値。これは、完全に重複しているコンテンツのみを対象とした重複コンテンツ・チェックです。2つのハッシュ値が一致する場合、ページの内容は完全に同じです。1文字の違いであれば、ハッシュ値が一意になり、重複コンテンツとして検出されません。つまり、重複コンテンツに近いかどうかをチェックするものではありません。正確な重複は、「URL > 重複」で確認することができます。
- Response Time : URLをダウンロードするのにかかる応答時間(秒)です。より詳細な情報は、FAQをご覧ください。
- Last-Modified : 最終更新日。サーバーのHTTPレスポンスにあるLast-Modifiedヘッダーから読み取ります。サーバーがこれを提供しない場合、この値は空になります。
- Redirect URI: 「address」のURLがリダイレクトされる場合、この欄にはリダイレクト先URLが表示されます。上記のステータスコードには、301、302などのリダイレクトの種類が表示されます。
- Redirect Type : 以下のいずれか。HTTP Redirect: HTTPヘッダー、HSTSポリシーによって引き起こされる。以前のHSTSヘッダーによりSEOスパイダーがローカルで回したもの、JavaScript Redirect:JavaScriptの実行により発生(JavaScriptレンダリング使用時のみ発生)、MetaRefresh Redirect:HTML内のmeta refreshタグがトリガーとなる。
- HTTP Version: クロールが行われたHTTPバージョンが表示され、デフォルトではHTTP/1.1となります。SEO Spiderは現在、サーバーで有効になっている場合、JavaScriptレンダリングモードでHTTP/2を使ってのみクロールを行います。
- URL Encoded Address : SEOスパイダーが実際にリクエストしたURLです。ASCII以外の文字はすべてパーセントエンコードされています。詳細はRFC3986をご覧ください。
- タイトル2、メタディスクリプション2、h1-2、h2-2など : SEOスパイダーはソースコードで遭遇する最初の2つの要素からデータを収集します。したがって、h1-2はページ上の2番目のh1見出しからのデータです。
フィルター
このタブには、以下のフィルター検索があります。
- HTML : HTMLページ
- JavaScript : すべてのJavaScriptファイル
- CSS : 発見されたすべてのスタイルシート
- Images: 任意の画像
- PDF : 任意のポータブルドキュメントファイル。
- Flash : あらゆる.swfファイル。
- Other : ドキュメントなど、その他のファイルタイプ。
- Unknown : コンテンツの種類が不明なすべてのURL。コンテンツタイプが指定されていないか、不正確であるか、またはURLをクロールできないためです。robots.txtによってブロックされたURLも、ファイルタイプが不明なため、ここに表示されます。
External(外部)
外部タブには、外部URLに関するデータが含まれます。「External(外部)」として分類されたURLは、クロールの開始ページとは異なるドメインにあります。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address : 外部URLのアドレス
- Content : URLのコンテンツタイプ。
- Status Code : HTTPレスポンスコード。
- Status : HTTPヘッダーレスポンス。
- Crawl Depth : ホームページまたは開始ページからの深さ(開始ページから「クリック」された数)。
- Inlinks : 外部URLを指すリンクが見つかった数。
フィルター
このタブには、以下のフィルター検索があります。
- HTML : HTMLページ
- JavaScript : すべてのJavaScriptファイル
- CSS : 発見されたすべてのスタイルシート
- Images: 任意の画像
- PDF : 任意のポータブルドキュメントファイル
- Flash : あらゆる.swfファイル
- Other : ドキュメントなど、その他のファイルタイプ
- Unknown : コンテンツの種類が不明なすべてのURL。コンテンツが提供されていないか、クロールできないURLのためです。robots.txtによってブロックされたURLも、ファイルタイプが不明なため、ここに表示されます。
Security(セキュリティ)
セキュリティタブは、クロールの内部URLのセキュリティに関するデータを表示します。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス): クロールされたURL
- Content : URLのコンテンツタイプ
- Status Code : HTTPレスポンスコード
- Status : HTTPヘッダーレスポンス
- Indexability : URLがインデックス可能か、インデックス可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など。
- Canonical Link Element 1/2 etc : URL上のCanonical Link Elementデータ。Spiderは複数ある場合、すべてのインスタンスを見つけます。
- Meta Robots 1/2 etc : URL上で見つかったメタ・ロボット。スパイダーは複数のインスタンスがある場合、すべてのインスタンスを検索します。
- X-Robots-Tag 1/2 etc : X-Robots-tagのデータです。Spiderは複数のインスタンスがある場合、すべてのインスタンスを検索します。
フィルター
このタブには、以下のフィルター検索があります。
- HTTP URL : このフィルタは、安全でない(HTTP)URLを表示します。今日、ウェブ上では、すべてのウェブサイトがHTTPSで安全であるべきです。セキュリティ上重要なだけでなく、今やユーザーからも期待されています。Chromeや他のブラウザは、HTTPであったり、混合コンテンツ問題(安全でないリソースを読み込む)があるURLに対して「安全ではありません」というメッセージを表示します。これらのURLがどのように発見されたかを見るには、ウィンドウ下部のタブでその「リンク先」を表示します。また、「一括エクスポート > セキュリティ > HTTP URLのリンク」を使用して、HTTP URLにリンクしているすべてのページをエクスポートすることもできます。
- HTTPS URL : HTTPのセキュアバージョンです。すべての内部URLはHTTPSであるべきで、したがってこのフィルターの下に表示されるはずです。
- Mixed Content : 安全な HTTPS 接続で読み込まれた HTML ページに、安全でない HTTP 接続で読み込まれた画像、JavaScript、CSS などのリソースがある場合、そのページが表示されます。混合コンテンツは HTTPS を弱体化させ、盗聴や他の安全なページへの侵害を容易にします。ブラウザは、HTTPリソースの読み込みを自動的にブロックする場合もあれば、HTTPSにアップグレードしようとする場合もあります。セキュリティ上の問題や、ブラウザでの読み込みの問題を回避するために、すべてのHTTPリソースをHTTPSに変更する必要があります。HTTPリソースは、各URLの「アウトリンク」タブで確認できます。また、「一括エクスポート」>「セキュリティ」>「ミックスコンテンツ」で、HTTPリソースがあるページと一緒にエクスポートすることも可能です。
- Form URL Insecure : HTML ページにフォームがあり、そのアクション属性の URL が安全でない (HTTP) ものです。これは、フォームに入力されたデータが転送中に閲覧される可能性があるため、安全でないことを意味します。ウェブサイト上のフォームに含まれるURLはすべて暗号化されているため、HTTPSである必要があります。HTTPフォームのURLは、上部ウィンドウでURLをクリックし、下部ウィンドウの「URLの詳細」タブをクリックすると、フォームのURLが表示されます。これらのURLは、「一括エクスポート > セキュリティ > フォームURLの安全性」を使って、フォームが置かれているページと一緒にエクスポートすることができます。
- Form on HTTP URL : これは、フォームがHTTPページ上にあることを意味します。ユーザー名やパスワードなど、フォームに入力されたデータはすべて安全ではありません。Chrome は、HTTP ページにパスワード入力フィールドがあるフォームを検出すると、「安全ではありません」というメッセージを表示できます。このフォームは、上部ウィンドウでURLをクリックし、下部ウィンドウの「URLの詳細」タブをクリックすると、HTTP URL上のフォームの詳細が表示され、確認することができます。
- Unsafe Cross-Origin Links : target=”_blank “属性(新しいタブで開く)を使って外部ウェブサイトにリンクしているページで、同時にrel=”noopener”(またはrel=”noreferrer”)を使っていないものが表示されます。target=”_blank “属性だけでは、セキュリティとパフォーマンスの両方の問題にさらされることになります。理想的には、target=”_blank” 属性を含むリンクには rel=”noopener” を使用して、それらを回避することでしょう。target=”_blank “属性を含む外部リンクは、「アウトリンク」タブと「ターゲット」列で確認することができます。これらのリンクは、「一括エクスポート > セキュリティ > 安全でないクロスオリジンリンク」を使って、リンク元のページと一緒にエクスポートすることができます。
- Protocol-Relative Resource Links : このフィルターは、プロトコル相対リンクを使って画像、JavaScript、CSSなどのリソースを読み込んでいるページをすべて表示します。プロトコル相対リンクとは、スキームを指定しないURLへの単なるリンクです(例://screamingfrog.co.uk)。これは、開発者がプロトコルを指定する手間を省き、ブラウザがリソースへの現在の接続状況に基づいてプロトコルを決定するのに役立ちます。しかし、このテクニックは現在ではHTTPSのアンチパターンとなっており、サイトによっては “man in the middle “の侵害やパフォーマンスの問題にさらされる可能性があります。プロトコル相対リンクは、’outlinks’ タブをクリックし、’Path Type’ カラムの ‘Protocol Relative’ を表示することで、各 URL のリソースリンクを確認することができます。これらのリソースリンクは、「Bulk Export > Security > Protocol-Relative Resource Links」によって、それらを読み込むページと一緒にエクスポートすることができます。
- Missing HSTS Header : HSTSレスポンスヘッダが欠落しているURL。HTTP Strict-Transport-Securityレスポンスヘッダ(HSTS)は、ブラウザに対して、HTTPではなくHTTPSでのみアクセスするように指示します。HTTPSに移行する前にHTTPへの接続を許可した場合、訪問者は最初はHTTPで通信します。HSTSヘッダーは、ブラウザに対して、HTTPでは決して読み込まず、すべてのリクエストを自動的にHTTPSに変換するように指示します。SEOスパイダーはHSTSヘッダーの指示に従いますが、HTTPのURLにリンクがあった場合はステータスコード307と「HSTSポリシー」のステータスで報告します。SEOs Guide To Crawling HSTSをお読みください。
- Missing Content-Security-Policy Header : Content-Security-PolicyレスポンスヘッダがないすべてのURL。このヘッダーにより、ウェブサイトはページに対して読み込まれるリソースを制御することができます。このポリシーは、サーバーから受信したコンテンツに対するブラウザの信頼を悪用するクロスサイトスクリプティング(XSS)攻撃からの防御に役立ちます。SEOスパイダーはヘッダーの存在を確認するだけで、ヘッダーの中にあるポリシーがウェブサイトにうまく設定されているかどうかを判断することはありません。これは手動で行う必要があります。
- Missing X-Content-Type-Options Header : ‘X-Content-Type-Options’レスポンスヘッダーの値が’nosniff’でないすべてのURLです。MIME タイプがない場合、ブラウザはユーザーに対して正しく解釈するために、コンテンツのタイプを推測するために「sniff」することがあります。しかし、これは攻撃者に悪用される可能性があり、攻撃者は侵害した画像を介してJavaScriptなどの悪意のあるコードを読み込もうとすることができます。このようなセキュリティ上の問題を最小限に抑えるには、X-Content-Type-Optionsレスポンスヘッダーを指定し、「nosniff」に設定する必要があります。これにより、ブラウザはContent-Typeヘッダーのみに依存し、正確に一致しないものはブロックするように指示されます。これは、Content-Typeの設定が正確である必要があることも意味します。
- Missing X-Frame-Options Header : X-Frame-Optionsレスポンスヘッダの値が「DENY」または「SAMEORIGIN」でないすべてのURLです。これは、フレーム、iframe、埋め込み、またはオブジェクト内にページを表示しないよう、ブラウザに指示するものです。これにより、攻撃者がコントロールする別のウェブページにお客様のコンテンツが表示される「クリックジャック」攻撃を回避することができます。
- Missing Secure Referrer-Policy Header : Referrer-Policyヘッダーに’no-referrer-when-downgrade’、 ‘strict-origin-when-cross-origin’ 、 ‘no-referrer’ または ‘strict-origin’ ポリシーがないすべてのURIです。HTTPS を使用する場合、HTTPS 以外のリクエストで URL が漏れないようにすることが重要です。これは、ネットワーク上の誰もが閲覧できるため、ユーザーを「中間者」攻撃にさらす可能性があります。
- Bad Content Type : 実際のコンテンツタイプがヘッダーで設定されたコンテンツタイプと一致しないURLが表示されます。また、使用されている無効なMIMEタイプも特定されます。X-Content-Type-Options: nosniff レスポンスヘッダーがサーバーによって設定されている場合、ブラウザがページを正しく処理するためにコンテンツタイプヘッダーに依存しているため、これは特に重要なことです。このため、たとえばMIMEタイプがtext/html以外で提供された場合、HTMLウェブページがレンダリングされずにダウンロードされることがあります。したがって、すべてのレスポンスはcontent-typeヘッダーに正確なMIMEタイプが設定されている必要があります。このフィルタは、’application/javascript‘ を使うべき JavaScript を ‘text/javascript‘ とするような、時代遅れの MIME タイプを含んでしまうことに注意してください。
HTTPリンク、正規化、ページネーション、および混合コンテンツ(画像、JS、CSS)などの安全でない要素を含むHTTPSページを発見するには、「レポート」トップレベルメニューの「安全でないコンテンツ」レポートを使用することをお勧めします。
Response Codes(レスポンスコード)
レスポンスコード] タブには、クロール中の内部および外部 URL からの HTTP ステータスとステータスコードが表示されます。フィルタは、共通のレスポンスコードのバケットによってURLをグループ化します。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス): クロールされたURL
- Content : URLのコンテンツタイプ
- Status Code : HTTPレスポンスコード
- Status : HTTPヘッダーレスポンス
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など
- Inlinks : そのURLへの内部インリンクの数です。内部インリンク」とは、クロールされている同じサブドメインから指定されたURLを指すリンクのこと
- Response Time : URLをダウンロードするのにかかった応答時間(秒)です。より詳細な情報は、FAQをご覧ください
- Redirect URL : アドレスのURLがリダイレクトされる場合、この欄にはリダイレクトURLのターゲットが表示されます。上のステータスコードには、301、302などのリダイレクトの種類が表示される
- Redirect Type : HTTPリダイレクト:HTTPヘッダーによって引き起こされる、HSTSポリシー:以前のHSTSヘッダーによってSEOスパイダーによってローカルに回される、JavaScriptリダイレクト:JavaScriptの実行によって引き起こされる(これはJavaScriptレンダリングを使用しているときにのみ発生します)またはメタリフレッシュリダレクト:ページのHTML内のメタリフレッシュタグによって引き起こされる、のいずれかを指定
フィルター
このタブには、以下のフィルター検索があります。
- Blocked by Robots.txt:サイトのrobots.txtでブロックされているすべてのURLです。これは、クロールできないことを意味し、ページのコンテンツを検索エンジンにクロールしてインデックスさせたい場合には、非常に重要な問題です。
- Blocked Resource : サイトのrobots.txtによってブロックされたすべてのリソース(画像、JavaScript、CSSなど)です。このフィルターは、JavaScriptレンダリングが有効な場合にのみ入力されます(ブロックされたリソースは、デフォルトの「テキストのみ」のクロールモードでは「Blocked by Robots.txt」の下に表示されます)。これは、検索エンジンがページを正確にレンダリングするために重要なリソースにアクセスできない可能性があるため、問題になることがあります。
- No Response(応答なし) : SEO スパイダーの HTTP リクエストに対して、URL が応答を送信しない場合。典型的な例としては、不正なURL、接続タイムアウト、接続拒否、接続エラーなどがあります。不正なURLは更新する必要があり、その他の接続の問題はSEO Spiderの設定を調整することで解決できることが多いです。
- Success (2XX): 要求されたURLは、正常に受信、理解、承認、処理されました。クロールで遭遇するすべてのURLがステータスコード「200」で「OK」であることが理想的で、コンテンツのクロールとインデックス作成に最適です。
- Redirection (3XX) : リダイレクトが発生しました。301や302のようなサーバーサイドのリダイレクトも含まれます。理想的には、すべての内部リンクは正規に解決されたURLへのものであり、リダイレクトするURLへのリンクは避けるべきです。これにより、ユーザーによるリダイレクトのホップ待ち時間を短縮できます。
- Redirection (JavaScript) : JavaScript のリダイレクトが発生しました。理想的には、すべての内部リンクは正規の解決 URL になり、リダイレクトする URL へのリンクは避けなければなりません。これにより、ユーザーによるリダイレクトホップの待ち時間が短縮されます。
- Redirection (Meta Refresh) : メタリフレッシュが発生しました。理想的には、すべての内部リンクは正規に解決されたURLへのもので、リダイレクトするURLへのリンクは避けてください。これにより、ユーザーによるリダイレクトホップの待ち時間が短縮されます。
- Redirect Chain(リダイレクトチェーン): 内部URLから別のURLにリダイレクトされ、そのURLもまたリダイレクトされること。これは、連続して複数回発生する可能性があり、各リダイレクトは「ホップ」と呼ばれます。リダイレクトチェーンの全容は、「レポート > リダイレクト > リダイレクトチェーン」で表示およびエクスポートすることができます。
- Redirect Loop(リダイレクトループ) : 内部URLから別のURLへリダイレクトされ、そのURLもまたリダイレクトされること。これは、連続して複数回発生する可能性があり、各リダイレクトは「ホップ」と呼ばれます。このフィルターは、ある URL がリダイレクトチェーン内の前の URL にリダイレクトされる場合にのみ、入力されます。ループのあるリダイレクトチェーンは、「Reports > Redirects > Redirect Chains(レポート > リダイレクト > リダイレクトチェーン)」で 「Loop」カラムを 「True」 に設定して表示、エクスポートすることができます。
- Client Error (4xx) : リクエストに問題が発生したことを示します。これには、400 bad request、403 Forbidden、404 Page Not Found、410 Removed、429 Too Many Requestsなどの応答が含まれることがあります。Webサイト上のすべてのリンクは、200 ‘OK’ URLに解決されるのが理想的です。404のようなエラーは、正しい位置に更新し、削除し、必要に応じてリダイレクトする必要があります。
- Server Error (5XX) : サーバーが、明らかに有効な要求を満たすことができませんでした。これは、500 Internal Sever Errorsや503 Server Unavailable などの一般的な応答を含むことがあります。すべてのURLは200 ‘OK’ステータスで応答する必要があり、これは負荷がかかっているサーバーや調査が必要な設定ミスを示している可能性があります。
HTTPステータスコードについては、「SEOを学ぶ」のガイドをご覧ください。また、SEOスパイダー使用時のレスポンスのトラブルシューティングについては、「クロール時のHTTPステータスコード」のチュートリアルをご覧ください。
URL
URLタブには、クロールで発見されたURLに関連するデータが表示されます。フィルターには、URLに対して発見された共通の問題が表示されます。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address : クロールされたURL
- Content : URLのコンテンツタイプ
- Status Code : HTTPレスポンスコード
- Status : HTTPヘッダーレスポンス
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など
- Hash : ページのハッシュ値。これは、コンテンツの重複をチェックするためのものです。2つのハッシュ値が一致した場合、ページの内容は完全に同じ
- Length : URLの文字数
- Canonical 1 : 正規のリンク要素データ
- URL Encoded Address : SEOスパイダーが実際にリクエストしたURLです。非ASCII文字はすべてパーセントエンコードされています。詳細はRFC 3986を参照してください
フィルター
このタブには、以下のフィルター検索があります。
- Non ASCII Characters(ASCII以外の文字) : URLには、ASCII文字セットに含まれない文字が含まれています。標準では、URLはASCII文字セットを使用してのみ送信することができ、一部のユーザーはこの範囲外の文字の微妙な違いを理解することが困難であることが概説されています。URLへのリンクをセーフキャラクタ(%の後に2桁の16進数が続く)でエンコードし、URLを有効なASCII形式に変換する必要があります。今日、ブラウザと検索エンジンは、URLを正確に変換することがほぼ可能です。
- Underscores(アンダースコア) : URLにアンダースコアが含まれていますが、検索エンジンからは単語の区切り文字として認識されない場合があります。ハイフンを単語の区切り文字として使用することをお勧めします。
- Uppercase(大文字) : URLに大文字の文字が含まれています。URLは大文字と小文字を区別しますので、ベストプラクティスとして、一般的にURLは小文字にする必要があります。
- Multiple Slashes(複数のスラッシュ) : URLのパスに複数のスラッシュがあります(例:screamfrog.co.uk/seo//など)。これは一般的に間違いです。ベストプラクティスとして、URLはパスのセクション間に1つのスラッシュのみを使用し、混同や重複するURLの可能性を回避してください。
- Repetitive Path(繰り返されるパス) : URLの文字列の中に繰り返されるパスがあります(例:screamfrog.co.uk/seo/seo/、screamfrog.co.uk/services/seo/technical/seo/など)。場合によっては、正当で論理的であることもありますが、URL構造の不備や改善の可能性を指摘することもよくあります。また、不正確な相対リンクの問題を特定し、無限URLを引き起こすこともあります。
- Contains A Space(スペースが含まれている) : URLにスペースが含まれています。これらは安全でないとみなされ、URLを共有する際にリンク切れを引き起こす可能性があります。単語の区切りには、スペースではなくハイフンを使用する必要があります。
- Internal Search(内部検索) : このURLは、ウェブサイトの内部検索機能の一部である可能性があります。Googleや他の検索エンジンは、内部検索ページをクロールされないようにブロックすることを推奨しています。ブロックされた内部検索URLがGoogleにインデックスされないようにするには、内部リンクを経由して発見できないようにする必要があります。したがって、これらのURLへの内部リンクを削除するか、nofollowリンク属性を含めることを検討してください。
- Parameters(パラメータ) :URLに’?’や”などのパラメータが含まれている。Googleなどの検索エンジンがクロールする際には問題になりませんが、ユーザーにとって煩雑になるURLのパラメータ数は制限することが推奨され、付加価値の低いURLのサインとなる可能性があります。
- Broken Bookmark(壊れたブックマーク) : HTML内のID属性を使ってユーザーをウェブページの特定の部分にリンクさせ、URLにフラグメント(#)とID名を付加する壊れたブックマーク(「名前付きアンカー」「ジャンプリンク」「スキップリンク」とも呼ばれます)を持つURL。リンクがクリックされると、ページはブックマークがある場所までスクロールします。このリンクはユーザーにとって優れたものですが、設定に間違いが生じやすく、ページが更新されたりIDが変更・削除されたりすると、時間の経過とともに「壊れた」状態になることがよくあります。ブックマークが壊れていると、ユーザーは正しいページに移動することはできますが、意図したセクションに移動することはできません。GoogleはこれらのURLを同じページと見なしますが(#からのものは無視するため)、ページランキングの検索結果で「ジャンプ先」のリンクに名前付きアンカーを使用することができます。inlinks’タブを使用して壊れたブックマークにリンクしているページを確認し、これが関連するセクションのページで使用されている正しいID属性を持っていることを確認してください。この問題を発見するためには、「設定 > スパイダー > 詳細設定」の「クロールフラグメント識別子」を有効にする必要があります。壊れたブックマークを見つける方法については、こちらのガイドをご覧ください。
- Over 115 characters(115文字以上) : URLの長さが115文字以上である。これは必ずしも問題ではありませんが、調査によると、ユーザーはより短く簡潔なURL文字列を好むことが分かっています。
URL構造については、「SEOを学ぶ」のガイドをご覧ください。
Page titles(ページタイトル)
ページタイトルタブには、クロールされた内部URLのページタイトル要素に関連するデータが含まれています。フィルターには、ページタイトルに発見された共通の問題が表示されます。
ページタイトルは、しばしば「タイトルタグ」、「メタタイトル」、あるいは「SEOタイトル」とも呼ばれ、ウェブページの先頭にあるHTML要素で、ユーザーや検索エンジンに対してページの目的を説明するものです。ページの最強のページ内ランキングシグナルの1つと広く考えられています。
ページタイトル要素は文書の先頭に配置し、HTMLでは次のようになります。
<title>This Is A Page Title</title>カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address : クロールされたURL
- Occurrences : ページ上で見つかったページタイトルの数(SEOスパイダーが見つける最大値は2です)
- Title 1/2 : ページタイトル要素の内容
- Title 1/2 length : ページタイトルの文字数
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、そのURLが別のURLに正規化されている場合や、「noindex」になっている場合など
フィルター
このタブには、以下のフィルター検索があります。
- Missing(欠落) : ページタイトル要素が欠落しているページ、コンテンツが空白であるページ、または空白があるページです。ページタイトルは、ユーザーと検索エンジンの両方が読み、ページの目的を理解するために使用されます。そのため、ページには簡潔で説明的、かつユニークなページタイトルを付けることが非常に重要です。
- Duplicate(重複) : ページタイトルが重複しているページ。各ページに明確でユニークなページタイトルを付けることは非常に重要です。すべてのページに同じページタイトルがあると、ユーザーや検索エンジンがあるページと別のページを理解することが難しくなります。
- Over 60 characters(60文字以上) : ページタイトルの長さが60文字以上のページ。この制限を超える文字は、Googleの検索結果で切り捨てられる可能性があり、スコアの重み付けが低くなります。
- Below 30 characters(30文字以下) : ページタイトルの長さが30文字以下のページ。これは必ずしも問題ではありませんが、より多くのキーワードを狙ったり、USPを伝えたりする余地があります。
- Over X Pixels(Xピクセル以上) : Googleのスニペットの長さは、実際には文字の長さではなく、ピクセルの制限に基づきます。SEOスパイダーはSERPsの最新のピクセル切り捨てポイントに合わせようとしますが、これは概算であり、Googleは頻繁に調整しています。このフィルターは、ページタイトルの長さがXピクセルを超えているページを表示します。
- Below X Pixels (Xピクセル以下) : ページタイトルの長さがXピクセル以下であるページ。これは必ずしも悪いことではなく、より多くのキーワードを狙ったり、USPを伝えたりする余地があるのです。
- Same as h1(h1と同じ): ページ上のh1と完全に一致するすべてのページタイトル。これは必ずしも問題ではありませんが、代替キーワード、同義語、または関連するキーフレーズをターゲットにする潜在的な機会を示している可能性があります。
- Multiple(複数) : 複数のページタイトルを持つすべてのページ。1つのページには、1つのページタイトル要素しかないはずです。複数のページタイトルは、CMSのプラグインやモジュールが複数競合している場合に発生することがあります。
ページタイトルの書き方については、「SEOを学ぶ」をご覧ください。
Meta description(メタディスクリプション)
meta descriptionタブには、クロール内の内部URLのmeta descriptionに関連するデータが含まれます。フィルタは、meta description について発見された一般的な問題を表示します。
メタディスクリプションとは、ウェブページの先頭にあるHTML属性で、ユーザーに対してページの概要を説明するものです。説明文の語句は、Googleによるランキングには使用されませんが、検索結果でユーザーに表示されるため、クリック率に大きく影響します。
メタディスクリプションは、文書の先頭に配置し、HTMLでは次のようになります。
<meta name="description" content="This is a meta description"/>カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- Occurrences(出現数) : ページで見つかったメタディスクリプションの数(私たちが見つける最大値は2です)
- Meta Description 1/2 : メタディスクリプション
- Meta Description 1/2 length : メタディスクリプションの文字の長さ
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、そのURLが他のURLに正規化されている場合など
フィルター
クロール完了後、このタブには、以下のカラムが表示されます。
- Missing(欠落) : メタディスクリプションが欠落しているページ、コンテンツが空白になっているページ、空白があるページです。これは、製品やサービスの利点を伝え、重要なURLのクリック率に影響を与える機会を逸しています。
- Duplicate(重複) : メタディスクリプションが重複しているすべてのページ。各ページの利点と目的を伝える、明確でユニークなメタディスクリプションを持つことが本当に重要です。重複していたり、関連性がない場合、検索エンジンに無視されます。
- Over 155 characters(155文字以上) : メタディスクリプションの文字数が155文字以上のページ。この制限を超える文字数は、Googleの検索結果で切り捨てられる可能性があります。
- Below 70 characters(70文字以下) : メタディスクリプションの長さが70文字以下であるすべてのページ。これは厳密には問題ではなく、チャンスです。ベネフィット、USP、コールトゥアクションを伝えるための余白があります。
- Over X Pixels(Xピクセル以上) : Googleのスニペットの長さは、実際には文字の長さではなく、ピクセルの制限に基づきます。SEOスパイダーはSERPsの最新のピクセル切り捨てポイントに合わせようとしますが、これは近似値であり、Googleは頻繁に調整しています。このフィルターは、X ピクセルを超える説明文を持ち、Google の検索結果で切り捨てられる可能性があるページを表示します。
- Below X Pixels(X ピクセル以下) : メタディスクリプションの長さが X ピクセル以下であるページ。これは厳密には問題ではなく、チャンスです。ベネフィット、USP、コールトゥアクションを伝えるための余地を増やせます。
- Multiple(複数) : メタディスクリプションが複数あるすべてのページ。1 つのページに対する meta description は 1 つだけであるべきです。複数の meta description は、CMS の複数のプラグインやモジュールが競合している場合に発生することが多いようです。
メタディスクリプションの書き方については、「SEOを学ぶ」をご覧ください。
Meta keywords(メタ・キーワード)
meta keywordsタブには、meta keywordsに関連するデータが含まれています。フィルターには、メタキーワードで発見された共通の問題が表示されます。
メタキーワードは検索エンジンから広く無視されており、欧米の主要な検索エンジンでは検索順位を決定付けるシグナルとして使用されていません。特にGoogleは、検索結果のランキングにおけるページのスコアリングにおいて、全く考慮しません。したがって、代替検索エンジンをターゲットにしている場合を除き、完全に無視することをお勧めします。
YandexやBaiduなどの他の検索エンジンは、まだランキングでそれらを使用するかもしれませんが、最適化の時間を取る前に、この状態への調査を実行することをお勧めします。
meta keywordsタグは、文書の先頭に配置し、HTMLでは次のようになります。
<meta name="keywords" content="seo, seo agency, seo services"/>カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- Occurrences(出現数) : ページで見つかったメタキーワードの数(私たちが見つけた最大値は2です)
- Meta Keyword 1/2 : メタキーワードです
- Meta Keyword 1/2 length : メタキーワードの文字数
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など
フィルター
このタブには、以下のフィルター検索があります。
- Missing(欠落) : メタキーワードが欠落しているページ。Google、Bing、Yahooをターゲットにしている場合は、ランキングに使用されないので、これは問題ではありません。BaiduやYandexをターゲットにしている場合は、関連するターゲットキーワードを含めることを検討するとよいでしょう。
- Duplicate(重複): メタキーワードが重複しているページ。BaiduやYandexをターゲットにしている場合、ページの目的に関連したユニークなキーワードを推奨します。
- Multiple(複数) : 複数のメタキーワードを持つページ。ページには1つのタグしかないはずです。
h1
h1タブは、ページの<h1>見出しに関連するデータを表示します。フィルターには、<h1>に対して発見された共通の問題が表示されます。
HTMLの見出しは、<h1>~<h6>タグで定義されます。<h1>はページの最初の大見出しとして最も重要であり、<h6>は最も重要でないと考えられています。
見出しは大きさと重要性で並べるべきで、ユーザーと検索エンジンがページやセクションの内容を理解するのに役立ちます。<h1>は、ページのメインタイトルと目的を記述する必要があり、ページ上の強力なランキングシグナルの1つと広く考えられています。
<h1>要素は文書の本文中に配置し、HTMLでは次のようになります。
<h1>This Is An h1</h1>デフォルトでは、SEO Spiderはページで発見された最初の2つの<h1>のみを抽出しレポートします。すべてのh1を抽出したい場合は、カスタム抽出を使用することをお勧めします。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- Occurrences(出現数) : ページ上で見つかった<h1>の数。上記で説明したように、最大で2つ見つかります。
- h1-1/2 : <h1>の内容
- h1-length-1/2 : <h1>の文字の長さ
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など
フィルター
このタブには、以下のフィルター検索があります。
- Missing(欠落) : <h1>が欠落しているページ、コンテンツが空白になっているページ、空白があるページ。 <h1>は、ユーザーと検索エンジンの両方が読み、ページの目的を理解するために使用されます。そのため、ページには簡潔で説明的、かつユニークな見出しをつけることが重要です。
- Duplicate(重複) : <h1>が重複しているページ。ページには、個性的でユニーク、かつ有用なものを用意することが大切です。すべてのページに同じ<h1>があると、ユーザーや検索エンジンがあるページと別のページを理解するのが難しくなります。
- Over 70 characters(70文字以上) : <h1>の長さが70文字以上であるページ。見出しには文字数制限がないため、厳密には問題ではありません。しかし、ユーザーや検索エンジンのために、簡潔で説明的な見出しにする必要があります。
- Multiple(複数) : 複数の<h1>を持つすべてのページ。HTML5の標準では1ページに複数の<h1>が認められているため、厳密には問題ではありませんが、この現代的なアプローチにはユーザビリティの点でいくつかの問題があります。文書構造を伝えるには、見出しのランク(h1〜h6)を使うことが推奨されています。古典的なHTML4規格では、1ページに1つの<h1>しかあってはならないと定義されており、これはユーザーとSEOのために今でも一般的に推奨されています。
見出しタグについては、「SEOを学ぶ」のガイドをご覧ください。
h2
h2タブは、ページの<h2>見出しに関連するデータを表示します。フィルターには、<h2>に対して発見された共通の問題が表示されます。
<h1>~<h6>タグは、HTMLの見出しを定義するために使用されます。<h2>はページの2番目に重要な見出しとみなされ、一般に2番目に大きな見出しとしてサイズとスタイルが設定されます。
<h2>見出しは、文書内のセクションやトピックを説明するためによく使われます。これらはユーザーのための標識として機能し、検索エンジンがページを理解するのを助けることができます。
<h2>要素は文書の本文中に配置し、HTMLでは次のようになります。
<h2>This Is An h2</h2>デフォルトでは、SEO Spiderはページで発見された最初の2つのh2のみを抽出しレポートします。すべてのh2を抽出したい場合は、カスタム抽出を使用することをお勧めします。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- Occurrences(出現数) : ページ上で見つかった<h2>の数。上記で説明したように、最大で2つ見つかります。
- h2-1/2 : <h2>の内容
- h2-length-1/2 : <h2>の文字の長さ
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など
フィルター
このタブには、以下のフィルター検索があります。
- Missing(欠落): <h2>が欠落しているページ、コンテンツが空白になっているページ、空白があるページ。 <h2>はユーザーと検索エンジンの両方が読み、ページとセクションを理解するために使用されます。ほとんどのページが論理的で説明的な<h2>を持つことが理想的です。
- Duplicate(重複) : <h2>が重複しているページ。ページには、個性的でユニーク、かつ有用なものを用意することが大切です。すべてのページに同じ<h2>があると、ユーザーや検索エンジンがあるページと別のページを理解するのが難しくなります。
- Over 70 characters(70文字以上) : <h2>の長さが70文字以上のページ。見出しには文字数制限がないため、厳密には問題ではありません。しかし、ユーザーや検索エンジンのために、簡潔で説明的な見出しにする必要があります。
- Multiple(複数) : <h2>が複数あるページ。HTMLの標準では、論理的な階層構造の見出しに複数の<h2>が使用されている場合、これは問題ではありません。しかし、このフィルターを使用すると、それらが適切に使用されているかどうかをすばやくスキャンして確認することができます。
見出しタグについては、「SEOを学ぶ」のガイドをご覧ください。
Content(コンテンツ)
「コンテンツ」タブは、クロールで発見された内部HTML URLのコンテンツに関連するデータを表示します。
これには、単語数、読みやすさ、重複するコンテンツやそれに近いもの、スペルや文法の間違いなどが含まれます。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス): URLのアドレスです
- Word Count(単語数) : HTMLマークアップを除く、bodyタグ内のすべての「単語」です。カウントは、「設定>コンテンツ>エリア」で調整可能なコンテンツエリアに基づいて行われます。デフォルトでは、ナビとフッターの要素は除外されています。HTML要素、クラス、IDを含めたり除外したりすることで、精緻なワードカウントを計算することができます。パーサーは無効な HTML に対して特定の修正を行うため、この計算を手動で実行した場合の数値とは異なる場合があります。また、レンダリングの設定も、どのようなHTMLを考慮するかに影響します。当社の単語の定義は、テキストをスペースで分割したものです。コンテンツの可視性(hidden に設定された div 内のテキストなど)は考慮されません。
- Average Words Per Sentence(平均単語数/1文) : コンテンツエリアの単語数の合計を発見された文の総数で割ったもの。これはFleschの読みやすさ解析の一部として計算されます。
- Flesch Reading Ease Score : Flesch読みやすさテストは、テキストの読みやすさを測定するものです。これは広く使われている読みやすさの公式で、文の平均的な長さと、単語ごとの平均音節数を用いて、0~100の間で点数を出します。0は非常に読みにくく、大学を卒業した人が最も理解しやすい文章、100は非常に読みやすく、11歳の学生でも理解できる文章を指します。
- Readability(読みやすさ) : Flesch Reading Ease Scoreと文書化されたスコア群に基づく総合的な読みやすさの評価分類です。
- Closest Similarity Match(最も近い類似性コンテンツ) : 重複に近いURLの最も高い類似性のパーセンテージを示します。SEOスパイダーは、類似度90%で一致するニアディプリケートを特定しますが、これを調整して、より低い類似度の閾値を持つコンテンツを見つけることができます。例えば、あるページに対して2つのニアディプリケートページがあり、それぞれの類似度が99%と90%だった場合、99%がここに表示されます。この列を表示するには、「Config > Content > Duplicates(設定 > コンテンツ > 重複)」 で 「Enable Near Duplicates(一致率の有効)」 設定を選択し、「Crawl Analysis」を実行する必要があります。選択した類似度閾値以上のコンテンツを持つURLのみがデータを含み、その他は空白のままです。したがって、「Config > Content > Duplicates(設定 > コンテンツ > 重複)」と 「Near Duplicate Similarity Threshold(類似一致率)」の設定で調整しない限り、デフォルトではこの列には類似度90%以上のURLのデータのみが含まれることになります。
- No. Near Duplicates : クロールで発見された重複するURLのうち、「Near Duplicate Similarity Threshold(類似一致率)」(デフォルトでは90%の一致)を満たすか超えるものの数。この設定は、「設定 > コンテンツ > 重複」で調整することができます。この列を表示するには、「Config > Content > Duplicates(設定 > コンテンツ > 重複)」で 「Enable Near Duplicates(一致率の有効)」設定を選択し、「Crawl Analysis」を実行する必要があります。
- Total Language Errors(言語エラーの合計) : URLで発見されたスペルや文法のエラーの合計数です。この列を表示するには、「Config > Content > Spelling & Grammar(設定 > コンテンツ > 言語&文法)」で「Enable Spell Check(スペルチェックを有効にする)」または「Enable Grammar Check(言語チェックを有効にする)」のいずれかを選択する必要があります。
- Spelling Errors(言語エラー) : URLで発見された言語エラーの合計数です。この列を表示するには、「Config > Content > Spelling & Grammar(設定 > コンテンツ > 言語&文法)」で「Enable Spell Check(スペルチェックを有効にする)」が選択されている必要があります。
- Grammar Errors(文法エラー) : URLで発見された文法エラーの合計数です。この列を表示するには、「Config > Content > Spelling & Grammar(設定 > コンテンツ > 言語&文法)」で「Enable Grammar Check(文法チェックを有効にする)」を選択する必要があります。
- Language(言語) : スペルチェックと文法チェックに使用される言語。これはHTMLの言語属性に基づいていますが、「Config > Content > Spelling & Grammar(設定 > コンテンツ > 言語&文法)」で言語を設定することもできます。
- Hash : MD5アルゴリズムを使用したページのハッシュ値。これは、完全に重複しているコンテンツのみを対象とした重複コンテンツ・チェックです。2つのハッシュ値が一致する場合、ページの内容は完全に同じです。1文字の違いであれば、ハッシュ値が一意になり、重複コンテンツとして検出されません。つまり、重複コンテンツに近いかどうかをチェックするものではありません。完全な重複は、「Content > Exact Duplicates(コンテンツ > 完全な重複)」で確認することができます。
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など
フィルター
このタブには、以下のフィルター検索があります。
- Exact Duplicates(完全な重複) : このフィルターは、MD5アルゴリズムを使って各ページの「ハッシュ」値を計算し、「ハッシュ」列で見ることができる同一性のあるページを表示します。このチェックはページの完全なHTMLに対して行われます。ハッシュ値が一致する、まったく同じページがすべて表示されます。完全に重複するページは、PageRankシグナルの分割やランキングの予測不可能性につながる可能性があります。あるURLの正規版は、内部的にリンクされている1つだけであるべきです。他のバージョンはリンクされるべきではなく、正規のバージョンに301リダイレクトされるべきです。
- Near Duplicates(近い重複率): このフィルタは、ミンハッシュアルゴリズムを使用して設定された類似性の閾値に基づいて、類似したページを表示します。この閾値は「Config > Content > Duplicates(設定 > コンテンツ > 重複)」で調整でき、初期設定では90%に設定されています。「Closeest Similarity Match(最も近い類似の一致)」カラムは、他のページとの類似度が最も高いものを表示します。「No. Near Duplicates(近し一致率の数)」列には、類似度閾値に基づいてそのページと類似しているページの数が表示されます。このアルゴリズムは、完全な重複のようなHTML全体ではなく、ページ上のテキストに対して実行されます。この分析に使用するコンテンツは、「Config > Content > Area(設定 > コンテンツ > エリア)」で設定することができます。ページの類似度は100%でも、完全な重複ではなく「ほぼ同じ」であることがあります。これは、完全な重複を近しい一致として除外することで、2回フラグが立つことを避けるためです。また、類似度スコアは四捨五入されるため、99.5%以上は100%として表示されます。この列を表示するには、「Config > Content > Duplicates(設定 > コンテンツ > 重複)」を通じて「Enable Near Duplicates(一致率の有効)」 設定を選択し、「クロール分析」を実行する必要があります。
- Low Content Pages(低品質ページ) : デフォルトでは、ワードカウントが200ワード以下のHTMLページがすべて表示されます。このワードカウントは、「Config > Content > Area(設定 > コンテンツ > エリア)」で設定できる、解析に使用するコンテンツ・エリアの設定に基づいています。実際にはページの最小ワード数はありませんが、検索エンジンはページの目的を理解するために説明的なテキストを必要とします。このフィルターは、ウェブサイトやページの目的に応じた説明的なコンテンツを追加することで改善される可能性があるページを特定するための、おおまかな目安としてのみ使用する必要があります。eコマースなどのウェブサイトでは、当然ながら文字数が少なくなりますが、商品の詳細が効率的に伝えられるのであれば、許容範囲となります。低コンテンツページのフィルタリングに使用される単語数は、「Config > Spider > Preferences > Low Content Word Count(設定 > Spider > 環境設定 > 低コンテンツ単語数)」でお好みに合わせて調整することができます。
- Spelling Errors(言語エラー) : このフィルターには、スペルエラーのあるHTMLページが含まれます。このフィルタとそれぞれのカラムに値を入れるには、「Config > Content > Spelling & Grammar(設定 > コンテンツ > 言語&文法)」で「Enable Grammar Check(言語チェックを有効にする)」を選択する必要があります。
- Grammar Errors(文法エラー) : このフィルターには、文法エラーのあるHTMLページがすべて含まれます。このカラムを表示させるには、「Config > Content > Spelling & Grammar(設定 > コンテンツ > 言語&文法)」で「Enable Grammar Check(文法チェックを有効にする)」を選択する必要があります。
- Readability Difficult(読みにくい) : ページ上のコピーは読みにくく、Fleschの読みやすさのスコア式によると、大卒の人が最も理解しやすい。長い文章や複雑な単語を使ったコピーは、一般的に読みにくく、理解しにくいものです。ターゲットとする読者層に合わせて、コピーの読みやすさを向上させることを検討してください。短い文章で、複雑な単語があまり使われていないコピーは、読みやすく、理解しやすいことが多いです。
- Readability Very Difficult(非常に読みにくい) : ページ上のコピーは、Fleschの読みやすさのスコア式によると、非常に読みにくく、大卒の人が最も理解しやすいとされています。長い文章や複雑な単語を使用したコピーは、一般的に読みにくく、理解しにくいものです。ターゲットとする読者層に合わせて、コピーの読みやすさを向上させることを検討してください。短い文章で、複雑な単語があまり使われていないコピーは、読みやすく、理解しやすいことが多いです。
重複コンテンツについては、「SEOを学ぶ」のガイドと、「重複コンテンツの確認方法」のチュートリアルをご覧ください。
Images(画像)
imagesタブは、クロールで発見された画像に関連するデータを表示します。これには、<img src=>タグまたは <a href=>タグのいずれかで検出された、内部および外部の画像が含まれます。フィルタは、画像とそのaltテキストについて発見された一般的な問題を表示します。
画像のalt属性(しばしば間違って「altタグ」と呼ばれる)は、画像をクリックし、下のウィンドウタブにポップアップ表示される「画像の詳細」タブで確認することができます。
Alt属性は、画像の目的について適切で説明的な代替テキストを指定し、以下の例のようにHTMLのソースに表示されるようにします。
<img src="screamingfrog-logo.jpg" alt="Screaming Frog" />。装飾的な画像(意味を持たない画像)は、スクリーン・リーダーなどの支援技術で無視できるように、NULL(空白)のaltテキスト(alt=””)を提供する必要があります。
<img src="decorative-frog-space.jpg" alt=""/>カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- Content(コンテンツ) : 画像のコンテンツタイプ(jpeg、gif、pngなど)
- Size(大きさ) : 画像の大きさをキロバイトで表したもの。ファイルサイズは、エクスポートではバイト単位なので、1,024で割ってキロバイトに変換してください
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など
フィルター
このタブには、以下のフィルター検索があります。
- Over 100kb(100kb以上) : 100kbを超える大きな画像。ページスピードはユーザーとSEOにとって非常に重要であり、しばしば画像などの大きなリソースは、ウェブページの速度を低下させる最も一般的な問題の1つです。このフィルタは、ファイルサイズがかなり大きく、読み込みに時間がかかりそうな画像を特定するための一般的な経験則として機能するだけです。これらの画像は、PSI APIとLighthouseを使用して速度を監査するPageSpeedタブで特定された機会とともに、最適化のために考慮する必要があります。これは、サイズが最適化されていない画像、画面外にロードされる画像、最適化されていない画像などを特定するのに役立ちます。
- Missing Alt Text(Altテキストがない) : alt属性があるにもかかわらず、altテキストがない画像。画像のアドレス(URL)をクリックし、下のウィンドウペインにある「画像の詳細」タブをクリックすると、どのページに画像があり、どのページに画像のaltテキストがないかを確認することができます。画像には、その目的について説明する代替テキストが必要です。これにより、目の不自由な方や検索エンジンが、その画像とウェブページとの関連性を理解しやすくなります。装飾的な画像には、スクリーン・リーダーなどの支援技術で無視できるように、空白の(空の)altテキストを提供する必要があります(alt=””)。
- Missing Alt Attribute(Alt属性が存在していない) : alt属性がすべて欠落している画像です。画像のアドレス(URL)をクリックし、下のウィンドウペインにある「画像の詳細」タブをクリックすると、その画像が掲載されているページで、alt属性が欠落しているページが表示されます。すべての画像には、説明テキストを含むalt属性が必要です。装飾画像の場合は空白にしてください。
- Alt Text Over 100 Characters(100文字以上のaltテキスト) : 1つのインスタンスのaltテキストが100文字以上である画像。これは厳密には問題ではありませんが、画像のaltテキストは簡潔で説明的であるべきです。たくさんのキーワードや段落のテキストをページに詰め込むために使用すべきではありません。
- Background Images(背景画像): ウェブサイト全体で発見されたCSS背景画像と動的に読み込まれる画像で、重要でない装飾的な目的で使用されるべきものです。背景画像は通常、Googleのインデックスに登録されず、ブラウザは背景画像のalt属性やテキストを支援技術に提供しません。
画像の最適化については、「How To View Alt Text & Finding Missing Alt Text」のガイドをお読みください。また、「PageSpeed Insights Integrationの統合」もご検討ください。「画像の適切なサイズ」、「画面外の画像の遅延」、「画像の効率的なエンコード」、「次世代フォーマットでの画像配信 画像要素の幅と高さが明確でない」についての機会および診断が可能です。
Canoniocal
canonicalsタブには、クロール中に発見されたcanonical link elementとHTTP canonicalsが表示されます。フィルタは、canonicalについて発見された一般的な問題を表示します。
rel=”canonical “要素は、あるページが複数のURLで提供されている場合に、優先するバージョンを1つだけ指定するのに役立ちます。これは、インデックスとリンクのプロパティを1つのURLに統合してランキングに使用することで、重複コンテンツを防ぐための検索エンジンへのヒントとなります。
canonical link 要素は、文書の先頭に配置する必要があり、HTML では次のようになります。
<link rel="canonical" href="https://www.example.com/">また、rel=”canonical” HTTPヘッダを使用すると、次のようになります。
Link: <http://www.example.com>; rel="canonical"カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- Occurrences(出現数) : 見つかった正規表現の数 (link 要素と HTTP の両方を通じて)
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など。
- Canonical Link Element 1/2 etc : URLのCanonicalリンク要素データ。SEOスパイダーは、複数ある場合、すべてのインスタンスを見つけます。
- HTTP Canonical 1/2 etc : HTTPで発行されるCanonical。SEOスパイダーは、複数のインスタンスがある場合、すべてのインスタンスを検索します。
- Meta Robots 1/2 etc : URL上で見つかったメタ・ロボット。SEOスパイダーは、複数ある場合、すべてのインスタンスを見つけます。
- X-Robots-Tag 1/2 etc : X-Robots-tagのデータです。SEOスパイダーは複数ある場合、すべてのインスタンスを見つけます。
- rel=”next” and rel=”prev” : SEOスパイダーは、ページ分割された一連のURLの関係を示すために設計されたこれらのHTMLリンク要素を収集します。
フィルター
このタブには、以下のフィルター検索があります。
- Contains Canonical(Canonical を含む) : ページに正規の URL が設定されています (link 要素、HTTP ヘッダー、またはその両方を経由して)。これは、ページの URL が正規の URL と同じである自己参照型の正規 URL か、正規の URL がページの URL と異なる ‘canonicalised’ 型である可能性があります。
- Self Referencing(自己参照) : URLは、クロールされたページURLと同じURLの正規化されたものを持ちます(したがって、自己参照となります)。理想的には、正規化されたバージョンのURLだけが内部的にリンクされ、すべてのURLは自己参照する正規化されたものを持つことで、起こりうる重複コンテンツの問題(URLのトラッキングパラメータ、他のウェブサイトが解決したURLに誤ってリンクするなど、ウェブ上で自然に起こりうる問題)を回避することができます。
- Canonicalised(正規化されたURL) : ページはそれ自身とは異なる正規のURLを持っています。このURLは別の場所に「正規化」されています。これは、検索エンジンがそのページをインデックスしないように指示されていることを意味し、インデックスとリンクのプロパティは、ターゲットの正規URLに統合されるべきです。これらのURLは慎重に検討する必要があります。完全な世界では、正規化されたバージョンのみがリンクされるため、ウェブサイトはどのURLも正規化する必要はありませんが、制御不能なさまざまな状況や重複コンテンツの防止のために、正規化が必要になることがよくあります。
- Missing(欠落) : 正規のURLがリンク要素としても、HTTPヘッダー経由でも存在しないこと。ページが正規のURLを示していない場合、Googleは最適なバージョンまたはURLと思われるものを特定します。これは、ランキングの予測不可能性につながる可能性があるため、一般的にすべてのURLは、正規のバージョンを指定する必要があります。
- Multiple(重複) : URLに複数の正規表現が設定されています(複数のlink要素、HTTPヘッダー、またはその両方が組み合わされています)。1つの実装(link要素またはHTTPヘッダー)で設定される正規のURLは1つだけであるべきなので、これは予測不可能な事態を招く可能性があります。
- Multiple Conflicting(複数設定) : 1つのURLに対して複数のcanonicalが設定されているページで、異なるURLが(複数のlink要素、HTTPヘッダーのいずれか、または両方によって)指定されているもの。1つの実装(link要素またはHTTPヘッダー)で設定される正規のURLは1つだけであるべきなので、これは予測不可能な事態につながる可能性があります。
- Non-Indexable Canonical(インデックスされないcanonical): canonical URLは、インデックスが作成されないページです。robots.txtでブロックされている、応答がない、リダイレクト(3XX)、クライアントエラー(4XX)、サーバーエラー(5XX)、または「noindex」になっている正規化されたページがこれにあたります。正規化されたURLは、常にインデックス可能で、「200」レスポンスのページである必要があります。したがって、インデックスされないページへのCanonicalは、インデックスされるように解決するバージョンに修正する必要があります。
- canonical is Relative(相対パスのcanoncial): rel=”canonical “リンクタグが絶対的ではなく、相対的に設定されているページ。このタグは、多くのHTMLタグと同様に、相対URLと絶対URLの両方を受け入れますが、相対パスでは微妙な間違いを犯しやすく、インデックスに関連する問題を引き起こす可能性があります。
- Unlinked(リンクがない) : rel=”canonical “を介してのみ発見可能で、ウェブサイト上のハイパーリンクを介してリンクされていないURLです。これは、内部リンクやcanonicalに含まれるURLに問題があることを示すサインかもしれません。
canonicalsについては、Learn SEOガイドを、Canoncialsについては、How to Audit Canoncialsをご覧ください。
Pagination(ページネーション)
ページネーションタブには、クロールで発見された rel=”next” と rel=”prev” という HTML リンク要素に関する情報が含まれており、ページネーションされた一連のコンポーネント URL の関係を示すために使用されます。フィルターには、ページネーションで発見された共通の問題が表示されます。
Googleは2019年3月21日に、インデックス作成においてrel=”next “とrel=”prev “を長らく使用していないと発表しましたが、Bingなど他の検索エンジン(Yahooにも搭載)では、発見やサイト構造を理解するためのヒントとして今も使用されています。
パジネーション属性は、文書の先頭に記述し、HTMLでは次のようになります。
<link rel="prev" href="https://www.example.com/seo/"/>
<link rel="next" href="https://www.example.com/seo/page/2/"/>カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- Occurrences(出現数): 見つかった正規表現の数 (link 要素と HTTP の両方を通じて)
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など
- rel=”next” : SEOスパイダーは、ページ分割された一連のURLの関係を示すために設計されたこれらのHTMLリンク要素を収集
- rel=”prev” : SEOスパイダーは、ページ分割された一連のURLの関係を示すために設計されたこれらのHTMLリンク要素を収集
- Canonical Link Element 1/2 etc : URI上のCanonical link elementデータ。SEOスパイダーは、複数ある場合、すべてのインスタンスを発見
- HTTP Canonical 1/2 etc : HTTPで発行されるCanonical。SEOスパイダーは、複数のインスタンスがある場合、すべてのインスタンスを検索
- Meta Robots 1/2 etc : URI上で見つかったメタ・ロボット。SEOスパイダーは、複数ある場合、すべてのインスタンスを検索
- X-Robots-Tag 1/2 etc : X-Robots-tagのデータです。SEOスパイダーは複数ある場合、すべてのインスタンスを発見
フィルター
このタブには、以下のフィルター検索があります。
- Contains Pagination(ページネーションが含まれている) : URLにrel=”next “またはrel=”prev “属性があり、ページネーションされたシリーズの一部であることを示しています。
- First Page(最初のページ) : このURLにはrel=”next “属性しかなく、ページネーションされたシリーズの最初のページであることを示しています。このようなURLをスクロールして、シリーズの親ページに正確に実装されていることを確認するのは簡単で便利です。
- Paginated 2+ Pages(2ページ目以降) : URLにrel=”prev “が付いており、最初のページではなく、一連のページでページ分割されたページであることを示しています。この場合も、これらのURLをスクロールして、ページ分割されたページだけがこのフィルターで表示されるようにするのが有効です。
- Pagination URL Not In Anchor Tag(ページネーションURLにアンカータグが存在ない) : ページに含まれる rel=”next” および rel=”prev” 属性のいずれか、または両方に含まれる URL が、ページ自体の HTML アンカー要素にハイパーリンクとして含まれていません。ページネーションされたページは、ユーザーがクリックして次のページに移動できるように、通常のリンクでリンクする必要があります。また、Googleがページからページへとクロールし、PageRankがシリーズ内のページ間を移動できるようにする必要があります。GoogleのWebmaster TrendsのアナリストであるJohn Mueller氏は、Google Webmaster Central Hangoutで、ページネーションに適切なHTMLリンクを推奨しています。
- Non-200 Pagination URL(200でないページネーションURL) : rel=”next “およびrel=”prev “属性に含まれるURLは、200 ‘OK’のステータスコードで応答しません。robots.txtでブロックされているURL、無応答、3XX(リダイレクト)、4XX(クライアントエラー)、5XX(サーバーエラー)などがこれにあたります。ページ送りのURLは、クローラブルでインデックス可能でなければならないため、200以外のURLはエラーとして扱われ、検索エンジンに無視されます。200以外のページネーションURLは、「Reports > Pagination > Non-200 Pagination URLs(レポート > ページネーション > 200以外のページネーションURL)」エクスポートで一括してエクスポートすることができます。
- Unlinked Pagination URL(リンクされていないページネーションURL): rel=”next “およびrel=”prev “属性に含まれるURLは、ウェブサイト全体でリンクされていません。ページネーション属性は、従来のアンカー要素のようにPageRankを渡さないことがあるため、内部リンクや、ページネーション属性に含まれるURLに問題があることを示している可能性があります。リンクされていないページネーションURLは、「Reports > Pagination > Unlinked Pagination URLs(レポート > ページネーション > リンクされていないページネーションURL)」エクスポートで一括してエクスポートすることができます。
- Non-Indexable(インデックスされない) : ページ分割されたURLはインデックス化されません。一般的には、’view-all’ ページが設定されていたり、ページネーション URL に特別なパラメータがあり、単一の URL に正規化する必要がある場合を除いて、これらはすべてインデックス可能であるべきです。最も一般的な間違いの一つは、2ページ以上のページ分割されたページをシリーズの最初のページに正規化することです。Googleはこのような実装を推奨していますが、これは構成ページが実際には重複コンテンツを含んでいないためです。これは、Googleがページ分割されたURLをインデックスから完全に削除し、そのページからのアウトリンクをたどらなくすることを意味し、そのページ上の製品にとって問題となる可能性があります。このフィルターは、このような一般的なセットアップの問題を特定するのに役立ちます。
- Multiple Pagination URLs(複数のページネーションURL) : ページに複数の rel=”next” および rel=”prev” 属性があります(rel=”next” または rel=”prev” 属性は1つだけであるべきではないのに、です)。これは、検索エンジンに無視されることを意味する場合があります。
- Pagination Loop(ページネーション回遊) : これは、以前に遭遇したURLにループバックするrel=”next “とrel=”prev “属性を持っているURLを表示します。この場合も、表現されたページネーションシリーズが検索エンジンに単に無視されることを意味するかもしれません。
- Sequence Error(順番エラー) : rel=”next” と rel=”prev” HTML link elements の順序にエラーがある URL を表示します。このチェックにより、rel=”next” と rel=”prev” のHTMLリンク要素に含まれるURLが相互に関連し、シリーズ内の関係を確認することができるようになります。
ページネーションの詳細については、「rel=”next” と rel=”prev” のページネーション属性の監査方法」をご覧ください。
Directives(ディレクティブ)
directivesタブには、meta robotsタグとHTTPヘッダーのX-Robots-Tagに関連するデータが表示されます。これらのrobotsディレクティブは、Googleなどの検索エンジンでコンテンツやURLがどのように表示されるかを制御することができます。
meta robotsタグは、ドキュメントのheadに配置する必要があり、「noindex」metaタグの例は、HTMLでは次のようになります。
<meta name="robots" content="noindex"/>同じディレクティブは、X-Robots-Tagを使用してHTTPヘッダーで発行することができ、次のようになります。
X-Robots-Tag: noindexカラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- Meta Robots 1/2 etc : URLにあるMeta robotsディレクティブ。SEOスパイダーは、複数ある場合、すべてのインスタンスを検索します。
- X-Robots-Tag 1/2 etc : URLのX-Robots-tag HTTPヘッダーディレクティブです。SEOスパイダーは、複数のインスタンスがある場合、すべてのインスタンスを見つけます。
フィルター
このタブには、以下のフィルター検索があります。
- Index : これでページがインデックスされるようになります。これがなくても検索エンジンはURLをインデックスするので、不要です
- Noindex : これは検索エンジンがページをインデックスしないように指示します。ページはまだクロールされますが(ディレクティブを見るために)、その後インデックスから削除されます。「noindex」が指定されたURLは、慎重に検査する必要があります
- Follow : ページ上のすべてのリンクをクロールのためにフォローするよう指示します。検索エンジンはデフォルトでそれらをフォローするので、不要です
- Nofollow : 検索エンジンがクロールするために、ページ上のいかなるリンクもたどらないように指示する「ヒント」です。このディレクティブを含める必要がない場合、一般的に「noindex」と組み合わせて誤って使用されることがあります。meta nofollowタグのあるページをクロールするには、「Config > Spider(設定>スパイダー)」で「Follow Internal Nofollow」の設定を有効にする必要があります
- None : ディレクティブがないことを意味するものではありません。メタタグ「none」が使われていることを意味し、「noindex, nofollow」に相当します。これらのURLは、検索エンジンのインデックスから正しく除外されていることを確認するために、注意深くレビューする必要があります
- NoArchive : これは、検索結果にページのキャッシュリンクを表示しないようにGoogleに指示するものです
- NoSnippet : テキストスニペットやビデオプレビューが検索結果に表示されないようにGoogleに指示します
- Max-Snippet : この値は、このページのテキストスニペットの長さを、Googleで[数字]文字に制限することができます。特別な値として、-0はスニペットなし、-1は任意の長さのスニペットを許可します
- Max-Image-Preview : この値は、Googleでこのページに関連付けられたあらゆる画像のサイズを制限することができる。設定値は “none”、”standard”、”large “のいずれかとすることができます
- Max-Video-Preview : この値は、このページに関連するあらゆるビデオ・プレビューを、Googleで[数値]秒に制限することができます。また、0を指定すると静止画のみ、-1を指定すると任意の長さのプレビューを許可することができます。
- NoODP : これは古いメタタグで、GoogleがスニペットにOpen Directory Projectを使用しないよう指示するために使用されます。これは削除することができます
- NoYDIR : これは古いメタタグで、GoogleがスニペットにYahooディレクトリを使用しないよう指示するために使用します。これは削除することができます。
- NoImageIndex : これはGoogleに、画像検索結果で画像の参照ページとしてこのページを表示しないように指示します。これは、このページ上のすべての画像がインデックスされないようにする効果があります。
- NoTranslate : この値は、このページの翻訳を提供してほしくないことをGoogleに伝えます。
- Unavailable_After : Googleの検索結果にページが表示されなくなる正確な日時を指定することができます。
- Refresh : これは、一定時間後にユーザーを新しいURLにリダイレクトします。レスポンスコードタブでメタリフレッシュのデータを確認することをお勧めします。
このタブには、メタリフレッシュとカノニカルのカラムも表示されます。ただし、メタリフレッシュデータはレスポンスコードタブと関連するフィルターで、カノニカルはカノニカルタブで確認することをお勧めします。
hreflang
hreflangタブには、HTMLリンク要素、HTTPヘッダー、XMLサイトマップで配信される、SEOスパイダーがクロールしたhreflang注釈の詳細が含まれています。フィルタは、hreflangで発見された一般的な問題を表示します。
Hreflangは、言語や地域ごとに複数のバージョンのページがある場合に便利です。Googleにこれらの異なるバリエーションを伝え、言語や地域ごとに最も適切なバージョンのページを表示させることができるようになります。
Hreflang link要素は、文書のheadに配置し、HTMLでは次のようになります。
<link rel="alternate" hreflang="en-gb" href="https://www.example.com">
<link rel="alternate" hreflang="en-us" href="https://www.example.com/us/">このタブとそれぞれのフィルタに入力するには、「Store Hreflang」と 「Crawl Hreflang」オプションを有効にする必要があります (「設定 > Spider」の下)。通常のクロールでXML Sitemapsからhreflangアノテーションを抽出するには、「Crawl Linked XML Sitemaps」も選択されている必要があります。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- タイトル1/2 etc : ページのタイトル要素
- Occurrences(出現数) : ページ上で発見されたhreflangの数
- HTML hreflang 1/2 etc : ページ上の任意のHTMLリンク要素から、hreflang言語と地域コードを取得
- HTML hreflang 1/2 URL etc : ページ上の任意のHTMLリンク要素からのhreflang URL
- HTTP hreflang 1/2 etc : HTTPヘッダーのhreflang言語と地域コード
- HTTP hreflang 1/2 URL etc : HTTP ヘッダーの hreflang URL
- Sitemap hreflang 1/2 etc : XML Sitemapに含まれるhreflang言語と地域コードです。これはリストモードでXML Sitemapをクロールする時のみ入力されます
- Sitemap hreflang 1/2 URL etc : XML Sitemapからhreflang URLを取得します。リストモードでXML Sitemapをクロールするときのみ入力されることに注意してください
フィルター
このタブには、以下のフィルター検索があります。
- Contains Hreflang(Hreflangを含む) : これらは、リンク要素、HTTPヘッダー、XML Sitemapなど、あらゆる実装でrel=”alternate” hreflangアノテーションを持つすべてのURL
- Non-200 Hreflang URLs(200以外のHreflang URL): rel=”alternate” hreflangアノテーションに含まれるURLで、robots.txtでブロックされたURL、応答なし、3XX(リダイレクト)、4XX(クライアントエラー)、5XX(サーバーエラー)など200レスポンスコードを持たないURLのことです。Hreflang URLはクローラブルでインデックス可能でなければならないため、200以外のURLはエラーとして扱われ、検索エンジンから無視されます。200でないURLは、下のウィンドウの「URL情報」窓で「non-200」という確認ステータスで見ることができます。これらは「Reports > Hreflang > Non-200 Hreflang URLs(レポート > Hreflang > Non-200 Hreflang URLs)」エクスポートで一括してエクスポートすることができます。
- Unlinked Hreflang URLs(リンクされていないHreflang URL) : rel=”alternate “のHreflangリンクアノテーションによってのみ発見可能な1つ以上のHreflang URLを含むページです。hreflangのアノテーションは、従来のアンカータグのようにPageRankを渡さないため、内部リンクやhreflangのアノテーションに含まれるURLに問題があることを示すサインかもしれません。これらのページのどのhreflang URLがリンクされていないかを正確に調べるには、「Reports > Hreflang > Unlinked Hreflang URLs(レポート > Hreflang > リンクされていないHreflang URLs)」エクスポートを使用します。
- Missing Return Links(リターンリンクの欠損) : これらは、代替ページからのリターンリンク(Google Search Consoleでは「リターンタグ」)が欠落しているURLのことです。hreflangは相互的なものなので、すべての代替バージョンは関係を確認する必要があります。ページXがページYを代替ページとして指定するためにhreflangを使用してリンクする場合、ページYにはリターンリンクが必要です。リターンリンクがないということは、hreflangの注釈が無視されるか、正しく解釈されない可能性があるということです。リターンリンクがないURLは、下のウィンドウの「URL情報」ペインで「見つからない」確認ステータスで見ることができます。これらは、「Reports > Hreflang > Missing Return Links(レポート > Hreflang > リターンリンクの欠損)」エクスポートで一括してエクスポートすることができます。
- Inconsistent Language & Region Return Links(一貫性のない言語と地域のリターンリンク) : このフィルタは、一貫性のない言語と地域のリターンリンクを持つURLを含みます。これは、リターンリンクの言語や地域の値が、そのURLの参照する値とは異なる場合です。矛盾した言語のリターンURLは、下のウィンドウの「URL情報」ペインで「矛盾している」という確認ステータスで見ることができます。これらは、「Reports > Hreflang > Inconsistent Language Return Links’(レポート > Hreflang > 一貫性のない言語と地域のリターンリンク)」エクスポートで一括してエクスポートすることができます。
- Non Canonical Return Links : hreflangのリターンリンクが正規化されていないURL。HreflangはURLの正規バージョンのみを含むべきです。そのため、このフィルタは正規版でないURLへのリターンリンクを拾います。正規化されていないリターンURLは、下のウィンドウの「URL情報」ペインで「正規化されていない」という確認ステータスで見ることができます。これらは、「レポート > Hreflang > Non Canonical Return Links」エクスポートで一括してエクスポートすることができます。
- Non Canonical Return Links(Noindexリターンリンク) : ‘noindex’メタタグを持つリターンリンクです。セット内のすべてのページはインデックス可能であるべきで、したがって、’noindex’を持つ戻りURLは、hreflang関係が無視される可能性があります。noindexのリターンリンクのURLは、下のウィンドウの「URL情報」ペインで「noindex」確認ステータスで見ることができます。これらは、「Reports > Hreflang > Non Canonical Return Links(レポート > Hreflang > Noindexリターンリンク)」エクスポートで一括してエクスポートすることができます。
- Incorrect Language & Region Codes(不正な言語と地域コード) : これは、言語(ISO 639-1形式)およびオプションの地域コード(ISO 3166-1アルファ2形式)の値が有効であるかどうかを確認するだけのものです。サポートされていないhreflangの値は、下のウィンドウの「URL情報」窓に「無効」ステータスで表示されます。
- Multiple Entries(複数エントリー) : 言語または地域コードに複数のエントリがあるURL。たとえば、ページXが同じ「en」hreflang値のアノテーションを使用してページYとZにリンクしている場合です。また、このフィルターは、hreflangアノテーションがリンク要素やHTTPヘッダーとして検出された場合など、複数の実装をピックアップします。
- Missing Self Reference(自己参照アノテーションがない): URLに自己参照のrel=”alternate” hreflangアノテーションがないもの。以前は、自己参照のhreflangを持つことが必須でしたが、Googleはガイドラインを更新し、これは任意であることを表明しています。しかし、自己参照属性を含めることは良い習慣であり、多くの場合は簡単です。
- Not Using Canonical(正規URLを使用していない) : そのページで、それ自身のhreflangアノテーションの中で、正規のURLを使用していないURL。HreflangはURLの正規版のみを含むべきです。
- Missing X-Default(X-Defaultのhreflang属性がない) : X-Defaultのhreflang属性がないURLです。これはオプションであり、必ずしもエラーや問題ではありません。
- Missing(欠損) : hreflang属性が完全に欠落しているURL。もちろん、複数のバージョンのページでなければ、これらは有効である可能性があります。
hreflangの詳細については、「Hreflangの監査方法」のガイドをお読みください。
JavaScript(ジャバスクリプト)
JavaScriptタブには、クライアントサイドJavaScriptを使用したWebサイトの監査に関連する一般的な問題に関するデータとフィルタが含まれています。
このタブは、JavaScriptレンダリングモード、「Configuration > Spider > Rendering tab > JavaScript(設定 > Spider > レンダリングタブ > JavaScript)」でのみ表示されます。
JavaScriptレンダリングモードでは、SEO Spiderがブラウザと同様にウェブページをレンダリングし、JavaScriptのコンテンツやリンク、その他の依存関係の特定を支援します。JavaScriptレンダリングモードは、有料版でのみ利用可能です。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address (アドレス): URLのアドレス
- Status Code(ステータスコード) : HTTPレスポンスコード
- Status : HTTPヘッダーレスポンス
- HTML Word Count(HTML単語数) : これは、HTMLマークアップを除く、JavaScriptの前に存在する生のHTMLのbodyタグ内のすべての 「単語」です。対象範囲は、「Config > Content > Area(設定>コンテンツ>エリア)」で調整できるコンテンツエリアに基づいて行われます。初期設定では、ナビとフッターの要素は除外されています。HTML要素、クラス、IDを含めたり除外したりして、精緻なワードカウントを計算することができます。パーサーは無効な HTML に対して特定の修正を行うため、この計算を手動で実行した場合の数値とは異なる場合があります。また、レンダリングの設定も、どのようなHTMLを考慮するかに影響します。当社の単語の定義は、テキストをスペースで分割したものです。コンテンツの可視性(hiddenによって隠された div 内のテキストなど)は考慮されません。
- Rendered HTML Word Count(レンダリングされたHTMLの単語数) : これは、JavaScript実行後にレンダリングされたHTMLのbodyタグ内のすべての「単語」であり、HTMLマークアップを除きます。対象範囲は、「Config > Content > Area(設定 > コンテンツ > エリア)」で調整可能なコンテンツエリアに基づいて行われます。初期設定では、ナビとフッターの要素は除外されています。HTML要素、クラス、IDを含めたり除外したりして、精緻なワードカウントを計算することができます。パーサーは無効な HTML に対して特定の修正を行うため、この計算を手動で実行した場合の数値とは異なる場合があります。また、レンダリングの設定も、どのようなHTMLを考慮するかに影響します。当社の単語の定義は、テキストをスペースで分割したものです。コンテンツの可視性(hiddenによって隠された div 内のテキストなど)は考慮されません。
- Word Count Change(レンダリング後の単語差異) : これは、HTML Word CountとRendered HTML Word Countの違いです。基本的に、JavaScriptによってどれだけの単語が入力されるか(または削除されるか)です。
- JS Word Count %(JS後の単語率) : これは、JavaScriptによってレンダリングされたHTMLで変化するテキストの割合です。
- HTML Title : JavaScriptの前の生のHTMLでページ上に発見された(最初の)ページタイトルです。
- Rendered HTML Title(レンダリングされたHTMLのタイトル) : JavaScriptの実行後にレンダリングされたHTMLでページに発見された(最初の)ページタイトルです。
- HTML Meta Description : JavaScriptの前に生のHTMLでページ上に発見された(最初の)メタディスクリプションです。
- Rendered HTML Meta Description(レンダリングされたHTMLのメタディスクリプション) : JavaScript実行後にレンダリングされたHTMLでページ上に発見された(最初の)メタディスクリプションです。
- HTML H1 : JavaScriptの前の生のHTMLでページ上に発見された(最初の)h1。
- Rendered HTML H1(レンダリングされたHTMLのH1) : JavaScript実行後のレンダリングHTMLでページ上に発見された(最初の)h1。
- HTML Canonical : JavaScriptの前の生のHTMLでページ上に発見された正規のリンク要素です。
- Rendered HTML Canonical(レンダリングされたHTMLのcanonical) : JavaScript実行後にレンダリングされたHTMLのページで発見された正規のリンク要素。
- HTML Meta Robots : JavaScriptの前に生のHTMLでページ上に発見されたメタロボットです。
- Rendered HTML Meta Robots(レンダリングされたHTMLのMeta Robots) : JavaScript実行後にレンダリングされたHTMLのページで発見されたメタロボットです。
- Unique Inlinks(固有の内部リンク) : そのURLへの「ユニークな(固有の)」内部リンクの数。「Internal inlinks」とは、クロール対象の同じドメインから指定されたURLを指すアンカー要素内のリンクのことです。例えば、「ページA」が「ページB」に3回リンクしている場合、「ページB」に対する内部リンクは3回、固有の内部リンクは1回とカウントされます。
- Unique JS Inlinks(固有のJSによる内部リンク) : JavaScript実行後にレンダリングされたHTMLにのみ存在する、URLへの「ユニークな(固有の)」内部インリンクの数です。「Internal inlinks」とは、クロール対象の同じサブドメインから指定されたURLを指すアンカー要素内のリンクのことです。たとえば、「ページA」が「ページB」に3回リンクしている場合、「ページB」への内部リンクが3回、固有の内部リンクは1回とカウントされます。
- Unique Outlinks(固有の内部発リンク) : そのURLからの「ユニークな(固有の)」内部発リンクの数です。「Internal outlinks」とは、あるURLからアンカー要素で、クロールされている同じドメインの他のURLへのリンクのことです。例えば、「ページA」から同じドメイン上の「ページB」に3回内部リンクしている場合、「ページB」への内部発リンクが3回、固有の内部発リンクは1回とカウントされます。
- Unique JS Outlinks(固有のJS内部発リンク) : JavaScript実行後にレンダリングされたHTMLにのみ存在する、そのURLからの「ユニークな(固有の)」内部アウトリンクの数です。「Internal outlinks」とは、任意のURLから、クロールされている同じドメイン上の他のURLへのアンカー要素内のリンクのことです。たとえば、たとえば、「ページA」が「ページB」に3回リンクしている場合、「ページB」への内部リンクが3回、固有の内部リンクは1回とカウントされます。
- Unique External Outlinks(固有の外部発リンク) : そのURLからの「ユニークな(固有の)」外部発リンクの数です。「External outlinks」とは、あるURLから別のドメインへのアンカー要素でのリンクのことです。たとえば、「ページA」から別のドメインの「ページB」に3回リンクしている場合、「ページB」への外部発リンクは3回、固有の外部発リンクは1回とカウントされます。
- Unique External JS Outlinks(固有のJS外部発リンク) : JavaScript実行後にレンダリングされたHTMLにのみ存在する、URLからの「ユニークな(固有の)」外部発リンクの数です。「External outlinks」とは、与えられたURLから別のドメインへのアンカー要素内のリンクのことです。たとえば、「ページA」が別のドメインの「ページB」に3回リンクしている場合、これは3つの外部発リンクとカウントされ、「ページB」に対する固有の外部発リンクは1つとなります。
フィルター
このタブには、以下のフィルターがあります。
- Pages with Blocked Resources(ブロックされたリソースを含むページ) : robots.txtによってブロックされたリソース(画像、JavaScript、CSSなど)を含むページ。これは、検索エンジンがページを正確にレンダリングするために重要なリソースにアクセスできない可能性があるため、問題になることがあります。robots.txtを更新して、重要なリソースがすべてクロールされ、Webサイトのコンテンツのレンダリングに使用されるようにします。重要でないリソース(例:Googleマップの埋め込み)は無視することができます。
- Contains JavaScript Links(JavaScript のリンクが含まれている) : JavaScript を実行した後にレンダリングされた HTML にのみ表示されるハイパーリンクが含まれているページです。これらのハイパーリンクは、生のHTMLにはありません。Googleはページをレンダリングしてクライアントサイドのリンクだけを見ることができますが、重要なリンクはサーバーサイドの生のHTMLに含めることを検討してください。
- Contains JavaScript Content(JavaScriptのコンテンツを含む) : JavaScriptを実行した後にレンダリングされたHTMLにのみ表示される本文を含むページ。Googleはページをレンダリングしてクライアントサイドのコンテンツだけを見ることができますが、重要なコンテンツはサーバーサイドの生のHTMLに含めることを検討してください。
- Noindex Only in Original HTML(生HTML内のnoindexページ) : レンダリングされたHTMLではなく、生のHTMLにnoindexが設定されているページ。Googlebotはnoindexタグに遭遇すると、レンダリングとJavaScriptの実行をスキップします。GooglebotはJavaScriptの実行をスキップするため、JavaScriptを使ってレンダリングされたHTML内の「noindex」を削除してもうまくいかない。生のHTMLにnoindexがあるページは、インデックスされないと予想されるので、慎重に検討する。インデックスされるべきページであれば、「noindex」を削除する。
- Nofollow Only in Original HTML(生HTML内のnofollwページ) : レンダリングされたHTMLではなく、生のHTMLにnofollowが含まれているページです。これは、JavaScriptを実行する前の生のHTMLにあるハイパーリンクは、フォローされないということです。生のHTMLにnofollowが含まれているページは、フォローされないことが予想されるので、慎重に確認してください。リンクが追跡され、クロールされ、インデックスされる必要がある場合は、「nofollow」を削除してください。
- Canonical Only in Rendered HTML(JS後HTML内のcanonicalページ) : JavaScript実行後のレンダリングHTMLにのみCanonicalが含まれるページ。Google はレンダリングされた HTML でも canonical を処理できますが、JavaScript に依存することは推奨しておらず、生の HTML で早期に処理することを推奨しています。レンダリングに問題があったり、rel=”canonical” リンクタグが複数あったりすると、予期しない結果になることがあります。Googleが確実に確認できるように、生のHTML(またはHTTPヘッダー)にcanonicalリンクを含め、レンダリングされたHTMLのみのcanonicalに依存することは避けてください。
- Canonical Mismatch正規表現の不一致: 生のHTMLとJavaScript実行後のレンダリングHTMLに、異なる正規表現リンクが含まれているページ。Googleは、JavaScriptの処理後にレンダリングされたHTMLの正規リンクを処理できますが、rel=”canonical “リンクタグが競合していると、予想外の結果につながる可能性があります。検索エンジンへのシグナルの衝突を避けるために、生のHTMLとレンダリングされたHTMLに正しいcanonicalがあることを確認してください。
- Page Title Only in Rendered HTML(レンダリング後HTMLのページタイトル) : JavaScript実行後にレンダリングされたHTMLにのみページタイトルが表示されるページです。これは、検索エンジンがそのページを見るためには、レンダリングする必要があることを意味します。Googleはページをレンダリングしてクライアントサイドのコンテンツだけを見ることができますが、重要なコンテンツはサーバーサイドの生のHTMLに含めることを検討してください。
- Page Title Updated by JavaScript(JSによる変更後のページタイトル) : JavaScriptによって変更されたページタイトルを持つページ。これは、生のHTMLのページタイトルとレンダリングされたHTMLのページタイトルが異なることを意味します。Googleはページをレンダリングしてクライアントサイドのコンテンツだけを見ることができますが、重要なコンテンツはサーバーサイドの生のHTMLに含めることを検討してください。
- Meta Description Only in Rendered HTML(レンダリング後HTMLのメタディスクリプション) : JavaScript実行後にレンダリングされたHTMLにのみメタディスクリプションが含まれるページ。これは、検索エンジンがページをレンダリングしないと見られないことを意味します。Googleはページをレンダリングしてクライアントサイドのコンテンツだけを見ることができますが、重要なコンテンツをサーバーサイドの生のHTMLに含めることを検討してください。
- Meta Description Updated by JavaScript(JSによる変更後のメタディスクリプション) : JavaScriptによって変更されたメタディスクリプションを持つページ。これは、生の HTML の meta description とレンダリングされた HTML の meta description が異なることを意味します。Google はページをレンダリングしてクライアントサイドのコンテンツのみを見ることができますが、重要なコンテンツはサーバーサイドの生の HTML に含めることを検討してください。
- H1 Only in Rendered HTML(レンダリング後HTMLのH1) : JavaScript実行後にレンダリングされたHTMLにのみh1が含まれるページ。これは、検索エンジンがそのページを見るためにはレンダリングする必要があることを意味します。Googleはページをレンダリングしてクライアントサイドのコンテンツだけを見ることができますが、重要なコンテンツはサーバーサイドの生のHTMLに含めることを検討してください。
- H1 Updated by JavaScript(JSによる変更後のH1) : JavaScriptによって変更されたh1があるページ。これは、生のHTMLのh1とレンダリングされたHTMLのh1が異なることを意味します。Googleはページをレンダリングしてクライアントサイドのコンテンツだけを見ることができますが、重要なコンテンツはサーバーサイドの生のHTMLに含めることを検討してください。
- Uses Old AJAX Crawling Scheme URLs : 2015年10月時点で正式に非推奨となったOld AJAXクローリングスキーム(#! ハッシュフラグメントを含むURL)をまだ使用しているURLです。今日のウェブ上のJavaScriptのベストプラクティスに従うようにURLを更新してください。可能な限りサーバーサイドレンダリングまたはプリレンダリング、および回避策としてダイナミックレンダリングを検討します。
- Uses Old AJAX Crawling Scheme Meta Fragment Tag : URLには、2015年10月時点で正式に非推奨となったOld AJAXクローリングスキームをまだ使用していることを示すmeta fragment tagが含まれています。今日のウェブ上のJavaScriptのベストプラクティスに従うようにURLを更新してください。可能な限りサーバーサイドレンダリングまたはプリレンダリング、および回避策としてダイナミックレンダリングを検討します。サイトが誤って古いmeta fragmentタグをまだ持っている場合、これを削除すること。
Links(リンク集)
リンクタブには、クロール深度の高いページ、内部発リンクのないページ、内部リンクにnofollowを使用しているページなど、クロールで見つかったリンクに関連する共通の問題に関するデータとフィルターが含まれています。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : URLのアドレス
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など
- Crawl Depth(クロールの深さ) : 開始ページからのページの深さ(開始ページから「クリック」された数)。リダイレクトは、ページの深さの計算において、現在1レベルとしてカウントされていることに注意してください。
- Link Score(リンクスコア) : 0-100の間の指標で、GoogleのPageRankと同様に、内部リンクに基づいてページの相対的な価値を計算します。このカラムを表示させるには、「クロール解析」が必要です。
- Unique Inlinks(固有のリンク) : そのURLへの「ユニークな(固有の)」内部リンクの数。「Internal inlinks」とは、クロール対象の同じドメインから指定されたURLを指すアンカー要素内のリンクのことです。例えば、「ページA」が「ページB」に3回リンクしている場合、「ページB」に対する内部リンクは3回、固有の内部リンクは1回とカウントされます。
- Unique JS Inlinks(固有のJSによる内部リンク) : JavaScript実行後にレンダリングされたHTMLにのみ存在する、URLへの「ユニークな(固有の)」内部インリンクの数です。「Internal inlinks」とは、クロール対象の同じサブドメインから指定されたURLを指すアンカー要素内のリンクのことです。たとえば、「ページA」が「ページB」に3回リンクしている場合、「ページB」への内部リンクが3回、固有の内部リンクは1回とカウントされます。
- % of Total(内部リンク割合): URLへの「ユニークな(固有の)」内部リンク(200レスポンスHTMLページ)のパーセンテージです。「Internal inlinks」とは、クロール対象の同じサブドメインから指定されたURLを指すアンカー要素内のリンクのことです。
- Outlinks(内部発リンク): そのURLからの内部アウトリンクの数。「Internal outlinks」とは、与えられたURLから、クロールされている同じドメイン上の他のURLへのアンカー要素のリンクのことです。
- Unique Outlinks(固有の内部発リンク) : そのURLからの「ユニークな(固有の)」内部発リンクの数です。「Internal outlinks」とは、あるURLからアンカー要素で、クロールされている同じドメイン上の他のURLへのリンクのことです。例えば、「ページA」から同じドメイン上の「ページB」に3回リンクしている場合、「ページB」への内部発リンクが3回、固有の内部発リンクは1回とカウントされます。
- Unique JS Outlinks(固有のJS内部発リンク) : JavaScript実行後にレンダリングされたHTMLにのみ存在する、そのURLからの「ユニークな(固有の)」内部アウトリンクの数です。「Internal outlinks」とは、任意のURLから、クロールされている同じドメイン上の他のURLへのアンカー要素内のリンクのことです。たとえば、たとえば、「ページA」が「ページB」に3回リンクしている場合、「ページB」への内部リンクが3回、固有の内部リンクは1回とカウントされます。
- External Outlinks(外部発リンク) : そのURLからの外部アウトリンクの数。「External outlinks」とは、指定されたURLから別のドメインへのアンカー要素のリンクのことです。
- Unique External Outlinks(固有の外部発リンク) : そのURLからの「ユニークな(固有の)」外部発リンクの数です。「External outlinks」とは、あるURLから別のドメインへのアンカー要素でのリンクのことです。たとえば、「ページA」から別のドメインの「ページB」に3回リンクしている場合、「ページB」への外部発リンクは3回、固有の外部発リンクは1回とカウントされます。
- Unique External JS Outlinks(固有のJS外部発リンク) : JavaScript実行後にレンダリングされたHTMLにのみ存在する、URLからの「ユニークな(固有の)」外部発リンクの数です。「External outlinks」とは、与えられたURLから別のドメインへのアンカー要素内のリンクのことです。たとえば、「ページA」が別のドメインの「ページB」に3回リンクしている場合、これは3つの外部発リンクとカウントされ、「ページB」に対する固有の外部発リンクは1つとなります。
フィルター
このタブには、以下のフィルター検索があります。
- Pages With High Crawl Depth(クロール深度の高いページ) : 「Config > Spider > Preferences(設定 > スパイダー > 設定)」の「Crawl Depth(クロール深度)」設定に基づき、クロール開始ページからのクロール深度が高いページです。一般的に、ホームページなどの人気ページから直接リンクされているページは、より多くのPageRankを渡され、オーガニックパフォーマンスを向上させることができます。Webサイトの奥深くにあるページは、PageRankが低く設定されることが多く、その結果、パフォーマンスが低下する可能性があります。これは、より競争の激しいクエリをターゲットとする重要なページにとって重要であり、リンクを改善し、クロールの深さを浅くすることで利益を得られる可能性があります。重要でないページ、競合性の低いクエリをターゲットとするページ、大規模なウェブサイトのページは、多くの場合、問題なく自然に深い位置に表示されます。最も重要なことは、ユーザーにとってどのページが重要であるか、そしてそのページに到達するまでの道のりを考慮することです。
- Pages Without Internal Outlinks(内部発リンクのないページ) : 他の内部ページへの発リンクがないページ。これは、他のページへのリンクが存在しないことを意味します。しかし、これはJavaScriptを使用していることが原因であることも多く、リンクは生のHTMLには存在せず、JavaScriptが処理された後にレンダリングされたHTMLにのみ存在します。JavaScriptのレンダリングモード(Config > Spider > Rendering(設定 > Spider > レンダリング))を有効にして、レンダリングされたHTMLにクライアントサイドのみ存在するリンクがあるページをクロールしてください。他の内部ページへのhref属性付きアンカータグを使用したリンクがない場合、検索エンジンやSEOスパイダーが発見しインデックス化することが困難となります。
- Internal Nofollow Outlinks(内部nofollw発リンク) : 内部発リンクにrel=”nofollow “を使用しているページ。nofollowリンク属性の付いたリンクは、一般に検索エンジンに追跡されません。リンク先のページは、他のリンクやXML Sitemapsなど、他の手段で発見される可能性があることを覚えておいてください。Nofollowのアウトリンクは、「Outlinks」タブで「All Link Types」フィルターを「Hyperlinks」に設定し、「Follow」カラムを「False」にして見ることができます。「Bulk Export > Links > Internal Nofollow Outlinks(一括エクスポート > リンク > 内部のnofollow 発リンク集)」で一括エクスポートできます。
- Internal Outlinks With No Anchor Text(アンカーテキストのない内部リンク) : アンカーテキストのない内部リンク、またはaltテキストのないハイパーリンクが設定されているページ。アンカーテキストとは、ハイパーリンクで使用される目に見えるテキストと単語のことで、ユーザーと検索エンジンにターゲットページのコンテンツに関するコンテキストを提供します。アンカーテキストのない内部アウトリンクは、「Outlinks」タブで「All Link Types(すべてのリンクタイプ)」フィルターを「ハイパーリンク(HyperLinks)」に設定し、「Anchor Text(アンカーテキスト)」列を空白にするか、画像の場合は「Alt Text(Altテキスト)」列も空白にして表示することができます。「Bulk Export > Links > Internal Outlinks With No Anchor Text(一括エクスポート > リンク > アンカーテキストなしの内部アウトリンク)」で一括エクスポートします。
- Non-Descriptive Anchor Text In Internal Outlinks(内部リンクに記述的でないアンカーテキストがあるページ) : 内部リンクのアンカーテキストが、「Config > Spider > Preferences(設定 > Spider > 設定)」の設定に基づき、「ここをクリック」や「もっと知りたい」のように記述的でないものになっているページです。アンカーテキストとは、ハイパーリンクで使用される目に見えるテキストや単語のことで、ユーザーや検索エンジンにターゲットページのコンテンツに関するコンテキストを提供します。説明的でないアンカーテキストを含む内部アウトリンクは、「Outlinks」タブで「All Link Types」フィルターを「Hyperlinks」に設定し、「Anchor Text(アンカーテキスト)」列に「ここをクリック」または「もっと知りたい」などの単語を設定して見ることができます。「Bulk Export > Links > Non-Descriptive Anchor Text In Internal Outlinks(一括エクスポート > リンク > 内部リンクの非記述的アンカーテキスト)」を使って一括エクスポートします。
- Pages With High External Outlinks(外部発リンクの多いページ) : 「Config > Spider > Preferences(設定 > スパイダー > 設定)」の「High External Outlinks(外部発リンクの多いページ)」の設定に基づき、外部アウトリンクの数が多いページです。外部発リンクとは、他のドメインやドメインへのハイパーリンクのことです(設定により異なる)。これは、同じルートドメインの別の部分へのリンクや、他の有用なウェブサイトへのリンクなど、完全に有効なものである可能性があります。外部リンクは、「Outlinks」タブで「All Link Types」フィルターを「Hyperlinks」に設定し、「Follow」カラムを「True」にして表示することができます。
- Pages With High Internal Outlinks (内部発リンクが多いページ) : 「Config > Spider > Preferences(設定 > Spider > 設定)」 の「High Internal Outlinks(内部アウトリンクが多い)」設定に基づき、内部発リンクが多く設定されているページ。内部発リンクとは、同じドメインやドメインへのハイパーリンクのことです(設定により異なる)。リンクは、ユーザーがウェブサイトをナビゲートするために使用し、検索エンジンはページを発見しランク付けするために使用します。リンクが多すぎると、ユーザビリティが低下し、各ページに配分されるPageRankの量が減少する可能性があります。内部リンクを持つアウトリンクは、「Outlinks」タブで「All Link Types」フィルターを「Hyperlinks」に設定し、「Follow」カラムを「True」にして表示することができます。
- Follow & Nofollow Internal Inlinks To Page(followとnofollowが混在している内部リンク) : 他のページからrel=”nofollow “とfollowの両方のリンクが張られているページです。nofollowリンク属性が付いたリンクは、一般に検索エンジンにフォローされません。nofollowリンク属性がないリンクは、一般にフォローされます。ですから、followとnofollowのあるリンクの一貫性のない使用は、問題や間違いの兆候かもしれませんし、無視してもよいことかもしれません。Nofollowとfollowのインリンクは、「Inlinks」タブで「All Link Types」フィルターを「Hyperlinks」に設定し、「Follow」列を「True」「False」にして確認することができます。「Bulk Export > Links > Follow & Nofollow Internal Inlinks To Page(一括エクスポート > リンク集 > followとnofollowが混在している内部リンク)」で一括エクスポートします。
- Internal Nofollow Inlinks Only (nofllow内部リンク): 他のページからのrel=”nofollow “リンクのみを持つページです。nofollowリンク属性でマークされたリンクは、一般的に検索エンジンにフォローされないので、ページの発見やインデックス作成に影響を与える可能性があります。Nofollowリンクは、「Inlinks」タブの「All Link Types」フィルターを「Hyperlinks」に設定し、「Follow」カラムを「True」「False」にして表示させることができます。「Bulk Export > Links > Follow & Nofollow Internal Inlinks To Page(一括エクスポート > リンク > nofllow内部リンク)」によって一括エクスポートします。
- Outlinks To Localhost (ローカルホスト内への発リンク): localhostまたは127.0.0.1ループバックアドレスを参照するリンクが含まれているページ。Localhostはローカルコンピュータのアドレスで、開発時にインターネットに接続せずにブラウザでサイトを表示するために使用されます。これらのリンクは、実際のウェブサイトを閲覧しているユーザーには機能しません。これらのリンクは、「Outlinks」タブで見ることができ、「To」アドレスに「localhost」または127.0.0.1ループバックアドレスが含まれている場合、「Outlinks」タブで見ることができます。「Bulk Export > Links > Outlinks To Localhost(一括エクスポート > リンク集 > ローカルホストへのアウトリンク)」で一括エクスポートします。
- Non-Indexable Page Inlinks Only(非インデックスページへの内部リンク) : インデックスに登録されているページで、noindex、canonicalized、robots.txtで禁止されているページなど、インデックスに登録されていないページからリンクされているもの。noindexを持つページとそこからのリンクは、最初はクロールされますが、noindexのページはインデックスから削除され、時間の経過とともにクロールされなくなります。これらのページからのリンクもクロールされなくなる可能性があり、リンクがまったくカウントされなくなるかどうかは、Googlerによって議論されています。正規化されたページからのリンクは、最初はクロールされますが、正規化で示されたようにインデックスとリンクシグナルが別のページに渡されると、PageRankが予想通りに流れない可能性があります。これは、発見とランキングに影響を与える可能性があります。Robots.txtページはクロールされないため、これらのページからのリンクは表示されません。
AMP(アンプ)
AMPタブには、クロール中に発見されたAccelerated Mobile Pages (AMP)が含まれます。これらは、HTML AMP タグと rel=”amphtml” リンクで識別されます。このタブには、一般的なSEOの問題や、AMP Validatorを使用した検証エラーのフィルタが含まれています。
このタブとそれぞれのフィルターに入力するには、’Store’ と ‘Crawl‘ の両方の AMP オプションを有効にする必要があります(「Config > Spider(設定 > Spider)」の下)。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- Occurrences(出現数) : 見つかった正規表現の数 (link 要素と HTTP の両方を通じて)
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば他のURLに正規化されている場合など。
- Title 1 : (最初の)ページのタイトル
- Title 1 Length : ページタイトルの文字数
- Title 1 Pixel Width : ページタイトルのピクセル幅
- h1 – 1 : ページ上の最初のh1(見出し)
- h1 – Len-1 : h1の文字数
- Size(サイズ) : サイズの単位はバイトで、キロバイトに変換する場合は1024で割ります。この値は、Content-Lengthヘッダが提供されている場合はその値から、提供されていない場合は0に設定されます。HTMLページの場合、これは(圧縮されていない)HTMLのサイズに更新されます(バイト単位)。
- Word Count(単語数) : bodyタグ内のすべての「単語」です。HTMLマークアップは含まれません。パーサーは無効な HTML に対して特定の修正を行うため、この数値は手動で行った場合の数値とは異なる場合があります。また、レンダリングの設定も、どのようなHTMLを考慮するかに影響します。私たちの定義では、テキストをスペースで分割しています。コンテンツの可視性(hidden に設定された div 内のテキストなど)は考慮されません。
- Text Ratio(テキスト比率) : ページ上のHTML bodyタグに含まれる非HTML文字(テキスト)の数を、HTMLページが構成する総文字数で割り、パーセントで表示したものです。
- Crawl Depth(クロールの深さ) : 開始ページからのページの深さ(開始ページから「クリック」された数)。リダイレクトは、ページの深さの計算において、現在1レベルとしてカウントされていることに注意してください。
- Response Time(応答時間) : URIをダウンロードするのにかかった時間(秒)です。より詳細な情報は、FAQをご覧ください。
SEO関連フィルター
このタブには、以下のSEO関連のフィルターがあります。
- Non-200 Response(非200レスポンス) : AMP URLが「200:OK」ステータスコードで応答しないことです。robots.txtでブロックされたURL、無応答、リダイレクト、クライアントエラー、サーバーエラーなどが含まれます。
- Missing Non-AMP Return Link(非AMPリターンリンクがない) : 非AMPバージョンのURLの正規版には、AMP URLに戻るrel=”amphtml “のURLが含まれていません。これは、単に非AMPバージョンに含まれていないか、AMPの正規化に関する設定に問題がある可能性があります。
- Missing Canonical to Non-AMP(非AMP版へのCanonicalがない) : AMP URLのCanonicalが非AMP版に行かず、別のAMP URLに行く。
- Non-Indexable Canonical (インデックスされないcanoncalページ): AMP canonical URLは、インデックスを持たないページです。一般的に、デスクトップに相当するページはインデックス可能なページであるべきです。
- Indexable(インデックス可能) : AMPのURLはインデックス可能です。デスクトップに相当するAMP URLは、インデックスされないはずです(デスクトップに相当するCanonicalを持つべきため)。独立したAMPのURL(同等のものがない)は、インデックス可能であるべきです。
- Non-Indexable(インデックス不可能) : AMPのURLはインデックス化されていません。これは通常、デスクトップと同等のものに正しく正規化されているためです。
以下のフィルターは、AMPの仕様に関連する一般的な問題を特定するのに役立ちます。SEO Spiderは、AMP URLの検証には公式のAMP Validatorを使用しています。
AMP関連フィルター
このタブには、以下のAMP固有のフィルターが含まれています。
- Missing HTML AMP Tag(HTML AMPタグの欠落) : AMP HTML文書には、トップレベルのHTMLまたはHTML AMPタグが含まれている必要があります
- Missing/Invalid Doctype HTML Tag(Doctype HTMLタグの欠落/無効) : AMP HTMLドキュメントは、doctype、doctype HTMLで始まる必要があります
- Missing Head Tag(見出しタグがない) : AMPのHTML文書には、見出しタグが必要です(HTMLでは任意です)
- Missing Body Tag (ボディタグがない) : AMPのHTML文書にはボディタグが必要です(HTMLでは任意です)
- Missing Canonical (Canonicalの欠落) : AMPのURLは、その先頭に、AMP HTMLドキュメントの通常のHTMLバージョンを指すcanonicalタグ、またはそのようなHTMLバージョンが存在しない場合はそれ自体を含む必要があります
- Missing/Invalid Meta Charset Tag(Meta Charsetタグがない/無効) : AMP HTMLドキュメントは、headタグの最初の子としてmeta charset=”utf-8″タグを含む必要があります。
- Missing/Invalid Meta Viewport Tag(メタビューポートタグの欠落/無効) : AMP HTML文書は、headタグ内にmeta name=”viewport” content=”width=device-width,minimum-scale=1″ タグを記述する必要があります。また、initial-scale=1も含めることが推奨されます。
- Missing/Invalid AMP Script(AMP スクリプトの欠落/無効) : AMP HTML ドキュメントは、head タグ内に script async src=”https://cdn.ampproject.org/v0.js” タグを含む必要があります。
- Missing/Invalid AMP Boilerplate(AMPボイラープレートの欠落/無効) : AMP HTML文書は、headタグにAMPボイラープレート・コードを含む必要があります。
- Contains Disallowed HTML(許可されないHTMLが含まれている) : AMPで許可されないHTMLを含むAMP URLにフラグを立てます。
- Other Validation Errors(その他の検証エラー) : 上記のフィルターでカバーされていないその他の検証エラーのあるAMP URLにフラグを立てます。
AMPの詳細については、「AMPの監査と検証の方法」のガイドをお読みください。
Structured data(構造化データ)
構造化データタブには、クロールで発見された構造化データおよび検証の問題の詳細が含まれます。
コラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- Errors(エラー): URLで発見された検証エラーの合計数
- Warnings(警告) : URLに対して発見された検証警告の合計数
- Total Types(総タイプ数) : そのURLで発見されたアイテムタイプの総数
- Unique Types(ユニークタイプ) : URLで発見されたitemtypesのユニークな数
- Type 1(タイプ1) : URLに対して最初に検出されたアイテムタイプ
- Type 2 etc(タイプ2など) : URLに対して発見された2番目のアイテムタイプ
フィルター
このタブには、以下のフィルター検索があります。
- Contains Structured Data(構造化データを含む) : これらは、構造化データを含むすべてのURLです。上部のウィンドウの列で、さまざまなタイプを見ることができます。
- Missing Structured Data(構造化データの欠落) : 構造化データが含まれていないURLです。
- Validation Errors(バリデーションエラー) : バリデーションエラーが含まれるURLです。エラーは、Schema.org、Googleリッチリザルト機能、またはその両方のいずれかであり、設定に依存します。Schema.orgの問題は、常に警告ではなく、エラーとして分類されます。Google のリッチリザルト機能の検証では、必須プロパティがない場合や必須プロパティの実装に問題がある場合にエラーが表示されます。Googleの「必須プロパティ」は、リッチリザルトとして表示するためにコンテンツに含まれ、有効である必要があります。
- Validation Warnings(検証警告) : Googleリッチリザルト機能の検証警告が含まれるURLです。これらは、必須のプロパティではなく、常に「推奨プロパティ」に対するものです。推奨プロパティは、コンテンツに関するより多くの情報を追加するために含めることができ、より良いユーザーエクスペリエンスを提供します。Schema.org の検証に関する問題に対する「警告」はありませんが、古いdata-vocabulary.orgスキーマを使用している場合は警告が表示されます。
- Parse Errors(パースエラー) : 構造化データを持つURLで、正しくパースできなかったものです。これは、多くの場合、不正確なマークアップが原因です。Google が推奨するフォーマットである JSON-LD を使用している場合、JSON-LD プレイグラウンドはパース エラーのデバッグを支援する優れたツールになります。
- Microdata URL : Microdata形式の構造化データを含むURLです。
- JSON-LD URL : JSON-LD形式の構造化データを含むURLです。
- RDFa URL : RDFa形式の構造化データを含むURLです。
構造化データ&Googleリッチスニペット機能検証
構造化データの検証では、Schema.orgに従って型やプロパティが存在するかどうかをチェックし、問題がある場合は「エラー」を表示します。
例えば、https://schema.org/author がプロパティとして存在するか、https://schema.org/Book がタイプとして存在するかをチェックする。Schema.org最新版の主なSchema語彙と保留中のSchema語彙に対して検証を行う。
Schema.orgの語彙が公開されてから、SEO Spiderで更新されるまでには、短い時間がかかる場合があります。
また、SEO Spiderは、Googleのリッチリザルト機能に対して検証を行い、必須・推奨プロパティの有無やその値が正確であることを確認します。
SEOスパイダーが検証可能な完全なリストは以下の通りです。
- 記事・AMP記事・ブログ
- 書籍
- パンくずリスト
- カルーセル
- コース
- COVID-19(コロナウィルス)の発表
- 評論家のレビュー
- データセット
- 雇用主の総合評価
- 推定給与額
- イベント
- ファクトチェック
- よくあるご質問
- ハウツー(HowTo)
- 画像ライセンス
- 求人情報
- 職業訓練
- ライブ配信
- ローカルビジネス
- ロゴマーク
- 動画
- 製品
- Q&Aページ
- レシピ
- レビュー・スニペット
- サイトリンク検索ボックス
- ソフトウェアアプリ
- スピカブル
- サブスクリプションと有料コンテンツ
- 動画
SEOスパイダーが現在検証していないGoogleのリッチリザルト機能のリストは以下の通りです。
現在、Googleの全機能に対応しています。
構造化データの検証の詳細については、「構造化データのテストと検証方法」のガイドをご覧ください。
Sitemaps(サイトマップ)
Sitemapsタブには、クロールで発見されたすべてのURLが表示され、XML Sitemapsに関連する追加情報を表示するためにフィルタリングすることができます。
通常のクロールでXML Sitemapsをクロールし、フィルタを入力するには、「Crawl Linked XML Sitemaps」の設定を有効にする必要があります(「設定 > Spider」の下にあります)。
また、クロールの最後に「クロール分析」を行い、いくつかのフィルタを設定する必要があります。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- Content(コンテンツ): URIのコンテンツタイプ
- Status Code(ステータスコード) : HTTPレスポンスコード
- Status : HTTPヘッダーレスポンス
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など
フィルター
このタブには、以下のフィルター検索があります。
- URLs In Sitemap : XML Sitemapに含まれるすべてのURL。重要なURLのインデックスと正規化されたバージョンが含まれている必要があります。
- URLs Not In Sitemap : XML Sitemapに含まれないが、クロールで発見されたURL。これは意図的なものかもしれませんし(重要でないため)、欠落している可能性もあり、それらを含めるためにXML Sitemapを更新する必要があるのかもしれません。このフィルタは、インデックス化されていないURLを考慮せず、正しくインデックス化されていないと仮定し、したがって、含まれるようにフラグを立てるべきではありません。
- Orphan URLs(離小島のURL) : XML Sitemapにのみ含まれているが、クロールの際に発見されなかったURL。または、XMLサイトマップに含まれるURLから発見されただけで、クロールでは発見されなかったURL。これらは、誤ってXML Sitemapに含まれている可能性もありますし、インデックスさせたいページで、本当は内部的にリンクされているべきものかもしれません。
- Non-Indexable URLs in Sitemap(サイトマップに含まれるインデックス不能なURL) : XMLサイトマップに含まれているが、インデックス不能なため、削除するか、インデックス可能性を修正する必要があるURLです。
- URLs In Multiple Sitemaps(複数のサイトマップに含まれるURL) : 複数のXMLサイトマップに含まれるURLです。これは必ずしも問題ではありませんが、一般的にURLは1つのXML Sitemapにのみ掲載される必要があります。
- XML Sitemap With Over 50k URLs(50,000URLを超えるXMLサイトマップ): 許容された50,000 URLを超えるXMLサイトマップを表示します。それ以上のURLがある場合は、リストを複数のサイトマップに分割し、それらすべてをリストアップするサイトマップインデックスファイルを作成する必要があります。
- XML Sitemap With Over 50mb(50MB以上のサイトマップ) : これは許可された50MBのファイルサイズより大きいXML Sitemapを表示します。サイトマップが50MB(非圧縮)を超えている場合、リストを複数のサイトマップに分割する必要があります。
XML Sitemapsの詳細については、「XML Sitemapsの監査方法」についてのガイド、Sitemaps.orgおよびGoogle Search Consoleのヘルプをご覧ください。
PageSpeed(ページスピード)
PageSpeedタブには、Lighthouseを使用して速度監査を行うPageSpeed Insightsのデータが含まれ、Chrome User Experience Report(CrUX、または「フィールドデータ」)から実際のデータを検索することが可能です。
PageSpeedのデータを取得するには、単に’設定> APIアクセス> PageSpeedの洞察’に進み、無料のPageSpeed APIキーを挿入し、接続し、クロールを実行する]をクリックします。データは、クロールされたURLに対して入力が開始されます。
無料のAPI設定とSEO Spiderの設定方法については、PageSpeed Insightsの統合ガイドをお読みください。
コラム&メトリックス
PageSpeed Insights API統合により、以下の速度指標、機会、診断データを収集するよう設定することができます。
概要 メトリクス
- サイズ別の節約額
- 合計時間短縮
- 総リクエスト数
- 総ページサイズ
- HTMLサイズ
- HTMLカウント
- 画像サイズ
- 画像カウント
- CSSサイズ
- CSSカウント
- JavaScriptのサイズ
- JavaScriptのカウント
- 文字サイズ
- フォント数
- メディアサイズ
- メディアカウント
- その他のサイズ
- その他のカウント
- サードパーティーサイズ
- サードパーティーのカウント
CrUX メトリクス(PageSpeed Insights の「フィールドデータ」)
- CrUXパフォーマンス
- CrUXファーストコンテントフルペイント時間(秒)
- CrUX初のコンテントフルペイント部門
- CrUX 第一入力ディレイ時間(秒)
- CrUXファーストインプットディレイカテゴリー
- CrUX最大コンテンツ塗布時間(秒)
- CrUX最大のコンテントフルペイントカテゴリー
- CrUX 累積レイアウトシフト
- CrUX 累積レイアウトシフトカテゴリー
- CrUXインタラクションから次のペイントまで(ms)
- CrUXインタラクションから次の塗装カテゴリーへ
- 最初のバイトまでのCrUX時間(ms)
- CrUX Time to First Byte Category
- CrUX Originのパフォーマンス
- CrUX Origin 最初のコンテンツペイント時間(秒)
- CrUX Origin初のコンテントフルペイントカテゴリー
- CrUX Origin 最初の入力ディレイ時間(秒)
- CrUX Origin 第一入力ディレイカテゴリ
- CrUX Origin 最大のコンテンツペイント時間 (秒)
- CrUX Origin 最大の含有量を持つ塗料カテゴリー
- CrUX Origin 累積レイアウトシフト
- CrUX Origin 累積レイアウトシフトカテゴリー
- CrUX Originインタラクションから次のペイントまで(ms)
- クラックス・オリジン・インタラクション、次の塗装カテゴリーへ
- CrUX Origin 最初のバイトまでの時間 (ms)
- CrUX Origin 最初のバイトまでの時間 カテゴリ
ライトハウスメトリクス(PageSpeed Insightsの「Lab Data」)
- パフォーマンススコア
- 最初のバイトまでの時間(ms)
- 最初のコンテンツ塗布時間(秒)
- 第1回コンテントフル・ペイント・スコア
- スピードインデックス時間(秒)
- スピードインデックススコア
- インタラクティブになるまでの時間(秒)
- インタラクティブスコアまでの時間
- 初回平均塗装時間(秒)
- 初めての意味のあるペイントスコア
- 推定入力待ち時間(ms)
- 入力待ち時間の推定値
- ファーストCPUアイドル(秒)
- ファーストCPUアイドルスコア
- 最大電位 最初の入力ディレイ (ms)
- 最大潜在的な第一入力遅延のスコア
- 総ブロッキング時間 (ms)
- トータルブロッキングタイムスコア
- 累積レイアウトシフト
- レイアウトシフトスコア累計
機会損失
- レンダーブロックの解消 省資源(ms)
- オフスクリーン画像遅延時間 (ms)
- オフスクリーンイメージの保存を延期する
- 画像の効率的なエンコード 省エネ(ms)
- 画像保存の効率的なエンコード
- 画像の適切なサイズ設定 省資源 (ms)
- 画像保存の適切なサイズ
- Minify CSSの節約量(ms)
- CSSの節約を最小化
- Minify JavaScriptの節約量(ms)
- 最小限のJavaScriptの節約
- CSSの未使用量を削減する(ms)
- CSSの未使用分を削減する
- 未使用のJavaScriptを削減する 省資源 (ms)
- 未使用のJavaScriptの保存を削減する
- 次世代フォーマットでの画像配信 省略量(ms)
- 次世代フォーマットで画像を提供する 省資源化
- テキスト圧縮を有効にする 保存量(ms)
- テキスト圧縮保存を有効にする
- 必要なOriginの節約にプリコネクト
- サーバー応答時間(TTFB) (ms)
- サーバー応答時間(TTFB)区分(ms)
- 複数リダイレクトの節約量 (ms)
- プリロード・キー・リクエストの節約量 (ms)
- アニメーション画像にビデオ形式を使用する 省エネルギー (ms)
- アニメーション画像の保存には動画形式を使用する
- 画像最適化の総削減量(ms)
- レガシーJavaScriptをモダンブラウザのセービングに提供しないようにする
診断結果
- DOM要素数
- JavaScript実行時間(秒)
- JavaScript実行時間カテゴリ
- 効率的なキャッシュポリシーの節約
- メインスレッド作業の最小化(秒)
- メインスレッドのワークカテゴリの最小化
- Webfontの読み込み中にテキストが表示されたままになる
- 画像要素に明示的な幅と高さを指定しない
- 大きなレイアウトシフトを避ける
各指標、機会、診断の定義については、Lighthouseによる説明をご覧ください。
Diagnostics(ダイアグノスティック)
- DOM要素数
- JavaScript実行時間(秒)
- JavaScript実行時間カテゴリ
- 効率的なキャッシュポリシーの節約
- メインスレッド作業の最小化(秒)
- メインスレッドのワークカテゴリの最小化
- Webfontの読み込み中にテキストが表示されたままになる
- 画像要素に明示的な幅と高さを指定しない
- 大きなレイアウトシフトを避ける
各指標、機会、診断の定義については、Lighthouseによる説明をご覧ください。
フィルター
このタブには、以下のフィルター検索があります。
- レンダリングをブロックするリソースを排除 : ページの最初の描画をブロックしているリソースを含むすべてのページを、節約の可能性と共にハイライトします。
- 画像の適切なサイズ : サイズが適切でない画像を含むすべてのページをハイライトし、適切なサイズに変更することで節約できる可能性があることを示します。
- オフスクリーン画像の遅延 : 画像が非表示またはオフスクリーンになっているすべてのページをハイライトし、それらが遅延ロードされた場合の潜在的な節約も一緒に表示します。
- CSSの最小化 : CSSファイルが最小化されていないすべてのページと、それらが正しく最小化された場合の潜在的な節約をハイライト表示します。
- JavaScriptの最小化 : JavaScriptファイルが最小化されていないすべてのページと、それらが正しく最小化された場合の潜在的な節約をハイライト表示します。
- 未使用CSSの削減 : 未使用のCSSを含むすべてのページがハイライトされ、不要なバイトを削除することで節約できる可能性が示されます。
- 未使用のJavaScriptを削減 : 未使用のJavaScriptを含むすべてのページをハイライトし、不要なバイトを削除した場合の潜在的な節約額も表示します。
- 画像の効率的なエンコード : 最適化されていない画像を含むすべてのページをハイライトし、節約の可能性を示します。
- 次世代フォーマットで画像を配信 : 古い画像フォーマットの画像を含むすべてのページを、節約の可能性とともにハイライトします。
- テキスト圧縮を有効にする : テキストベースのリソースで圧縮されていないすべてのページを、節約の可能性とともにハイライトします。
- Preconnect to Required Origin : これは、まだリンクrel=preconnectでフェッチ要求を優先していないキー要求を持つすべてのページを、潜在的な節約とともに強調表示します。
- サーバー応答時間の短縮(TTFB) : サーバーがメインドキュメントのリクエストに応答するまでに600ミリ秒以上待たされたページをすべてハイライト表示します。
- 複数のリダイレクトを避ける : リダイレクトするリソースを持つすべてのページをハイライトし、ダイレクトURLを使用することで節約できる可能性があることを表示します。
- プリロードキー要求 : 重要な要求チェーンの3番目のレベルの要求を持つすべてのページをプリロード候補としてハイライト表示します。
- アニメーション画像にはビデオ形式を使用 : アニメーションGIFを含むすべてのページをハイライトし、それらをビデオに変換することで節約できる可能性があることも示しています。
- 過度のDOMサイズを避ける : 推奨される合計1,500ノードを超える大きなDOMサイズを持つすべてのページをハイライト表示します。
- JavaScript実行時間の短縮 : JavaScriptの実行時間が平均的、または遅いすべてのページをハイライト表示します。
- 効率的なキャッシュポリシーで静的資産を提供 : キャッシュされていないリソースを持つすべてのページを、節約の可能性とともにハイライトします。
- メインスレッド作業の最小化 : メインスレッドでの実行タイミングが平均的または遅いすべてのページをハイライト表示します。
- ウェブフォント読み込み中もテキストが表示されるようにする : ページ読み込み中に点滅したり見えなくなったりする可能性のあるフォントを含むすべてのページをハイライト表示します。
- 画像要素に明示的な幅と高さがない : HTMLに寸法(幅と高さのサイズ属性)が指定されていない画像を持つすべてのページがハイライトされます。これは、CLSを悪化させる大きな原因となり得ます。
- レイアウトの大きな変化を避ける : ページのCLSに最も貢献しているDOM要素を持つすべてのページをハイライトし、優先順位付けに役立つ各要素の貢献度を表示します。
- Avoiding Legacy JavaScript to Modern Browsers : レガシーなJavaScriptを含むすべてのページをハイライト表示します。ポリフィルとトランスフォームにより、レガシーブラウザは新しい JavaScript の機能を使用できるようになります。しかし、多くはモダンブラウザには必要ありません。バンドルされている JavaScript では、モジュール/ノモジュール機能検出を使用した最新のスクリプト展開戦略を採用し、レガシーブラウザのサポートを維持しながら、モダンブラウザに出荷されるコード量を削減します。
上記の各機会や診断の定義や説明については、Lighthouseのパフォーマンス監査ガイドをお読みください。
節約の可能性がある速度機会、ソースページ、リソースURLは、「レポート > PageSpeed」メニューから一括でエクスポートすることができます。
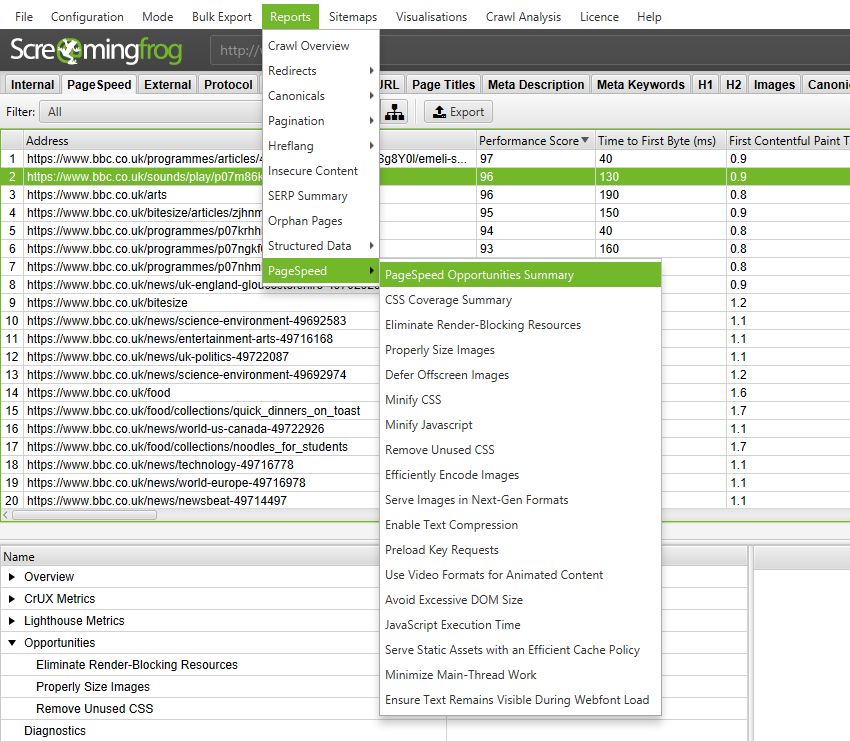
CSS Coverage Summary」レポートは、各CSSファイルがクロール全体でどの程度使用されていないか、また、サイト全体で読み込まれている未使用のコードを削除することで得られる潜在的なコスト削減効果を明らかにします。
JavaScript Coverage Summary」レポートは、各JSファイルがクロール全体でどの程度使用されていないか、また、サイト全体で読み込まれている未使用のコードを削除することによって得られる潜在的な節約を明らかにします。
PageSpeed Insights API ステータスおよびエラー
PSI Status 列は、ある URL に対する API リクエストが「成功」してデータを表示したのか、それとも「エラー」してデータを表示しなか ったのかを示している。エラー」は通常、ウェブインターフェースを反映しており、同じエラーとメッセージが表示されます。
PSIエラー」列には、PSI APIから受信したメッセージの全文が表示され、原因に関する詳細な情報が提供されます。一部のエラーはLighthouse監査自体の失敗によるものですが、他のエラーはリクエストが行われたときにPSI APIが利用できなかったことが原因である可能性があります。
詳しくは、PageSpeed Insights API Errorsに関するFAQをご覧ください。
カスタム検索
カスタム検索では、最大100個の検索フィルターを設定することができ、正規表現を入力すると、選択した入力を「contain(含む)」または「does not contain(含まない)」ページを検索することができます。検索結果は、カスタム検索タブに以下のように表示されます。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- Content(コンテンツ): URIのコンテンツタイプ
- Status Code(ステータスコード) : HTTPレスポンスコード
- Status : HTTPヘッダーレスポンス
- Contains[x](含む) : URLのソースコード内に[x]が出現する回数です。[x]はカスタム検索設定に入力されたクエリ文字列です。
- Does Not Contain[y](含まない) : このカラムは「含む」または「含まない」のどちらかを返します [y].[y]はカスタム検索設定に入力されたクエリ文字列です。
フィルター
このタブには、以下のフィルター検索があります。
- [Search Filter Name](検索フィルター名): フィルターは動的で、カスタム設定と関連するカラムの名前に一致します。入力されたクエリ文字列を含む、または含まないURLを表示します。
カスタム抽出
カスタム抽出設定で最大100個の抽出器を設定することができ、XPath、CSSPath、regexを入力して必要なデータをスクレイピングすることが可能です。抽出は、HTMLコンテンツタイプを持つURLに対してのみ行われます。
結果は、以下のようにカスタム抽出タブ内に表示されます。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : クロールされたURL
- Content(コンテンツ) : URIのコンテンツタイプ
- Status Code(ステータスコード) : HTTPレスポンスコード
- Status : HTTPヘッダーレスポンス
- [Extractor Name](抽出名) : 列の見出し名は、各抽出器に提された名前に基づいて動的です。各抽出器は、各URLに対して抽出されたデータを含む、独立した名前の列を持つことになります。
フィルター
このタブには、以下のフィルター検索があります。
- [Extractor Name](抽出名): フィルタは動的であり、抽出器と関連するカラムの名前にマッチします。これらは、URLに対して関連する抽出カラムを表示します。
Analytics(分析)
SEO Spiderは現在、一度に30個の指標を選択することができますが、デフォルトでは以下の10個のGoogle Analyticsの指標を収集することになっています。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Sessions(セッション)
- % New Sessions(新規セッションの割合)
- New Users(新規ユーザー)
- Bounce Rate(直帰率)
- Page Views Per Session(セッションごとのページビュー)
- Avg Session Duration(平均セッション時間)
- Page Value(ページ価値)
- Goal Conversion Rate(CVR)
- Goal Completions All(すべての目標達成率)
- Goal Value All(すべての目標値)
各メトリクスの定義については、Googleが詳しく解説しています。
アカウント、プロパティ、ビュー、セグメント、日付範囲、メトリクス、ディメンションの設定については、Google Analytics統合のユーザーガイドをご覧ください。
フィルター
このタブには、以下のフィルター検索があります。
- Sessions Above 0(セッション1以上) : これは、該当するURLのセッション数が1以上であることを単純に意味します。
- Bounce Rate Above 70%(直帰率70%以上) : これは、URLの直帰率が70%以上であることを意味し、調査することをお勧めします。シナリオによっては、これが正常である場合もあります。
- No GA Data(データなし) : これは、クエリされたメトリクスとディメンションについて、Google APIがクロール内のURLのデータを返さなかったことを意味します。つまり、URLはセッションを受け取らなかったか、あるいは、クロールされたURLが何らかの理由でGAと異なるだけなのです。
- Non-Indexable with GA Data(インデックス不可だが計測されている) : インデックス非対応と分類されているが、Google Analyticsのデータを持っているURL。
- Orphan URLs(離小島のページ) : クロール中に内部リンクではなく、Googleアナリティクス経由で発見されたURL。このフィルターを使用するには、Google Analyticsの設定ウィンドウ(設定 > APIアクセス > Google Analytics)の「一般」タブで「Google Analyticsで発見された新しいURLをクロールする」を有効にし、ポスト「クロール分析」を入力することが必要です。
Search Console(サーチコンソール)
詳しくは、Google Search Consoleの統合ガイドをご覧ください。統合した場合、以下のデータが収集されます。
カラム
クロール完了後、このタブには、デフォルトでSearch Analyticsの以下のカラムが表示されます。
- Clicks(クリック数)
- Impressions(表示回数)
- CTR(クリック率)
- Position(平均順位)
各メトリクスの定義については、Googleが詳しく解説しています。
オプションで、Search Analyticsのデータと一緒に「URL Inspectionを有効にする」を選択すると、1日1プロパティあたり最大2000URLのGoogleインデックスステータスデータが提供されます。これには、URL Inspection APIの以下のカラムが含まれます。
- Summary(概要) : URLがインデックスされ、Googleの検索結果に表示されるかどうかについての評価です。URL is on Google」は、URLがインデックスされ、Google検索結果に表示されることができ、ページで見つかった拡張機能(リッチリザルト、モバイル、AMP)には問題がなかったことを意味します。URLはGoogleに登録されているが、問題がある」は、インデックスされGoogle検索結果に表示されるものの、モバイルユーザビリティ、AMP、リッチリザルトに問題があり、最適な方法で表示されない可能性があることを意味します。URLがGoogleにない」とは、Googleにインデックスされておらず、検索結果に表示されないことを意味します。このフィルターには、インデックス可能なURLだけでなく、インデックスされないURL(「noindex」になっているものなど)も含まれることがあります。
- Coverage(カバレッジ) : URLの状態について、Googleに掲載されている、またはされていない理由を短く説明するものです。
- Last Crawl(最終クロール) : このページが最後にGoogleにクロールされた時刻(あなたの現地時間)。このツールで表示されるすべての情報は、この最後にクロールされたバージョンに由来しています。
- Crawled As(ユーザーエージェントの種類) : クロールに使用されたユーザーエージェントの種類(デスクトップまたはモバイル)。
- Crawl Allowed(クロール許可) : サイトがGoogleにページのクロール(訪問)を許可しているか、robots.txtルールでブロックしているかを示します。
- ページ取得の有無(Page Fetch) : Googleがあなたのサーバーから実際にページを取得できたかどうか。クロールが許可されていない場合、このフィールドは失敗を表示します。
- Indexing Allowed(インデックス許可) : あなたのページが明示的にインデックス作成を拒否しているかどうか。インデックス作成を許可しない場合、その理由が説明され、そのページはGoogle検索の結果に表示されなくなります。
- User-Declared Canonical(ユーザー指定のcanonical): あなたのページが明示的に正規のURLを宣言している場合、ここに表示されます。
- Google-Selected Canonical(Google指定のcanonical) : Googleがあなたのサイトに類似または重複するページを見つけたときに、正規の(権威ある)URLとして選択したページです。
- Mobile Usability(モバイルユーザビリティ) : ページがモバイルフレンドリーであるかどうか
- Mobile Usability Issues(モバイルユーザビリティの問題) : 「ページがモバイルフレンドリーではない」場合、この欄にはモバイルユーザビリティエラーのリストが表示されます。
- AMP Results(AMP結果) : AMP URLが有効か、無効か、警告があるかについての判定です。有効」は、AMP URLが有効でインデックスされていることを意味します。無効」は、AMP URLにインデックスされないようなエラーがあることを意味します。Valid with warnings」は、AMP URLはインデックスされる可能性があるが、全機能を取得できない可能性がある問題がある、または非推奨のタグや属性を使用しており、将来的に無効になる可能性があることを意味します。
- AMP Issues(AMPの問題) : URLにAMPの問題がある場合、この欄にはAMPエラーのリストが表示されます。
- Rich Results(リッチリザルト) : ページで見つかったRich Resultsが有効か、無効か、または警告があるかについての判定です。有効」は、リッチリザルトが見つかり、検索対象となることを意味します。無効」は、ページ上の1つ以上のリッチリザルトに検索対象から外れるエラーがあることを意味します。「Valid with warnings」は、ページ上のリッチリザルトは検索対象になっているが、完全な機能を得ることができない可能性がある問題があることを意味します。
- Rich Results Types(リッチリザルトタイプ) : ページ上で発見されたすべてのリッチリザルト拡張のカンマ区切りリスト。
- Rich Results Types Errors(リッチリザルトタイプエラー) : ページ上でエラーが検出されたすべてのRich Results Enhancementのカンマ区切りリスト。発見された特定のエラーをエクスポートするには、「Bulk Export > URL Inspection > Rich Results(一括エクスポート > URLインスペクション > リッチリザルト)」エクスポートを使用します。
- Rich Results Warnings(リッチリザルト警告) : ページ上で警告が発見されたすべてのRich Results Enhancementのカンマ区切りリスト。発見された特定の警告をエクスポートするには、「Bulk Export > URL Inspection > Rich Results(一括エクスポート > URLインスペクション > リッチリザルト)」エクスポートを使用します。
インデックスされたURLの結果については、Googleの記事をご覧ください。
フィルター
このタブには、以下のフィルター検索があります。
- Clicks Above 0(クリック数1以上): これは単純に、該当するURLのクリック数が1以上であることを意味します。
- No Search Analytics Data(データなし) : これは、Search Analytics APIが、クロール内のURLのデータを返さなかったことを意味します。つまり、そのURLはインプレッションを受け取らなかったか、あるいは何らかの理由でクロール内のURLとGSC内のURLが異なるだけです。
- Non-Indexable with Search Analytics Data(検索アナリティクスデータを持つ非インデックス型): 非インデックス型と分類されているが、Google検索アナリティクスデータを持つURL
- Orphan URLs(離小島のページ) : クロール中に内部リンクではなく、Google Search Analytics経由で発見されたURL。このフィルターを使用するには、Google Search Console の設定の「Search Analytics」タブで 「Crawl New URLs Discovered In Google Search Console」を有効にし (Configuration > API Access > Google Search Console > Search Analytics) 、ポスト 「crawl analysis」に値を入力することが必要です。離小島ページの見つけ方については、こちらのガイドをご覧ください。
- URL Is Not on Google(インデックスされていないURL) : このURLはGoogleにインデックスされておらず、検索結果には表示されません。このフィルターには、インデックスされる可能性のあるURLだけでなく、インデックスされないURL(「noindex」になっているものなど)も含めることができます。APIに従ってGoogleに登録されていないものに対するキャッチオールフィルタです。
- Indexable URL Not Indexed(インデックス可能だがインデックスされていないURL) : クロールで発見されたインデックス可能なURLのうち、Googleにインデックスされず、検索結果に表示されないURL。これには、Googleに知られていないURLや、発見されたもののインデックスされていないURLなどが含まれることがあります。
- URL is on Google, But Has Issues(URLはGoogleに登録されているが、問題がある) : URLはインデックスされ、Googleの検索結果に表示されますが、モバイルユーザビリティ、AMP、リッチリザルトに問題があり、最適な方法で表示されない可能性があります。
- User-Declared Canonical Not Selected(ユーザー指定のページ外をインデックス判断) : Googleは、ユーザーがHTMLで宣言したものとは異なるURLをインデックスすることを選択しました。Canonicalはヒントであり、Googleが素晴らしい仕事をすることもあれば、理想的でないこともあります。
- Page Is Not Mobile Friendly(ページがモバイルフレンドリーでない) : ページはモバイルデバイス上で問題があります。
- AMP URL Is Invalid(AMPのURLが無効)です : AMPにエラーがあり、インデックスに登録されません。
- Rich Result Invalid(リッチリザルト無効) : URLに1つ以上のリッチリザルト拡張機能のエラーがあり、リッチリザルトがGoogle検索結果に表示されないようになっています。発見された特定のエラーをエクスポートするには、「Bulk Export > URL Inspection > Rich Results(一括エクスポート > URL検査 > リッチリザルト)」エクスポートを使用します。
URL Inspection API の使用方法については、「URL Inspection API を自動化する方法」のガイドをご覧ください。
バリデーション
検証タブでは、クローラーがクロールやインデックスを作成する際に影響を与える可能性のある、基本的なベストプラクティスの検証を実行します。このタブの目的は、検索ボットが確実にページを解析し理解するために影響を与える問題を特定することです。
カラム
クロール完了後、このタブには、以下のカラムが表示されます。
- Address(アドレス) : URLのアドレスです
- Content(コンテンツ) : URLのコンテンツタイプ
- Status Code(ステータスコード) : HTTPレスポンスコード
- Status : HTTPヘッダーレスポンス
- Indexability : URLがインデックス可能か、インデックス不可能か
- Indexability Status : URLがIndexableでない理由。例えば、他のURLに正規化されている場合など
フィルター
このタブには、以下のフィルター検索があります。
- Invalid HTML Elements In <head>(<head> 内の無効な HTML 要素) : <head> 内に無効な HTML 要素があるページ。 無効な要素が <head> 内で使用されている場合、Google は <head> 要素の終わりを想定し、無効な要素の後に表示されるすべての要素を無視します。つまり、無効な要素の後に現れる重要な<head>要素は表示されないということです。HTML標準の<head>要素は、title、meta、link、script、style、base、noscript、template要素にのみ予約されています。
- <head> Not First In <html> Element(<head> Not First In <html> Element) : HTMLの中で<head>要素を進めているページがあります。<head>は<html>要素の中で最初の要素である必要があります。ブラウザやGooglebotは、<head>要素がHTMLの中で最初にない場合、自動的に生成します。理想的には<head>要素は<head>内にあるべきですが、有効な<head>要素が<html>の最初にある場合、それは生成された<head>の一部とみなされるでしょう。しかし、意図した<head>要素とそのメタデータの前に<p>、<body>、<img>などの非<head>要素が使用されていると、Googleは<head>要素の終わりと見なします。つまり、意図した<head>要素とそのメタデータは<body>の中でしか見られず、無視される可能性があります。
- Missing <head> Tag(<head>タグの欠落) : HTML内に<head>要素がないページ。<head>要素は、<html>タグと<body>タグの間に置かれる、ページに関するメタデータのためのコンテナです。メタデータは、ページのタイトル、文字セット、スタイル、スクリプト、ビューポート、その他ページにとって重要なデータを定義するために使用されます。ブラウザやGooglebotは、マークアップで<head>要素が省略された場合、自動的に生成しますが、この要素にはページにとって意味のあるメタデータが含まれていない可能性があり、これを当てにするべきではありません。
- Multiple <head> Tags(複数の<head>タグ) : HTML内に複数の<head>要素が存在するページ。HTML内の<head>要素は1つだけであるべきで、そこにはその文書の重要なメタデータがすべて含まれています。ブラウザやGooglebotは、<body>の前にある<head>要素に含まれるメタデータを結合しますが、これは信頼できるものではありませんし、混同される可能性があります。<body>の後にある<head>タグはすべて無視されます。
- Missing <body> Tag (<body>タグの欠落) : HTML内の<body>要素が欠落しているページ。<body>要素には、リンク、見出し、段落、画像など、ページのすべてのコンテンツが含まれます。ページのHTMLには、<body>要素が1つあるはずです。ブラウザやGooglebotは、マークアップに<body>要素が省略されている場合、自動的に<body>要素を生成しますが、これに頼ってはいけません。
- Multiple <body> Tags(複数の<body>タグ) : HTML内に複数の<body>要素が存在するページ。HTMLの<body>要素は1つだけであるべきで、そこにはその文書のすべてのコンテンツが含まれています。ブラウザやGooglebotは、後続の<body>要素からコンテンツを結合しようとしますが、これは信頼できるものではありませんし、混同される可能性があります。
- HTML Document Over 15MB(15MB以上のHTMLドキュメント) : ドキュメントサイズが15MB以上のページ。Googlebotは、HTMLファイルまたはサポートされているテキストベースのファイルの最初の15MBにクロールとインデックスを制限しているため、これは重要なことです。このサイズには、別途取得される画像、動画、CSS、JavaScriptなど、HTML内で参照されるリソースは含まれません。Googleは、ファイルの最初の15MBのみをインデックスの対象とし、それ以降はクロールを停止します。ファイルサイズの制限は、圧縮されていないデータに対して適用されます。HTMLファイルのサイズの中央値は約30キロバイト(KB)なので、ページがこの制限に達する可能性は極めて低い。
Link Metrics(リンクメトリクス)
リンクメトリクスのタブには、Majestic、Ahrefs、MozのAPIとSEO Spiderが統合されている場合、それらのデータが含まれます。
リンクメトリクスを取り込むには、「Configuration > API Access」に移動するだけです。ツールを選択した後、APIキーを生成して挿入する必要があります。接続後、クロールを実行すると、URLに対してデータが入力されます。
各ツールでのAPI設定の詳細については、それぞれ以下のガイドをお読みください。
カラム&メトリックス
- Address(アドレス) : URLアドレス
- Status Code(ステータスコード) : HTTPレスポンスコード
- Title 1(タイトル1) : URLから発見された(最初の)ページタイトル
統合された場合、以下のメトリックグループについてリンクデータを収集することができます。
- Exact URL(正確なURL)
- Exact URL(正確なURL – HTTP + HTTPS)
- Subdomain(サブドメイン)
- Domain(ドメイン)
マジェスティックメトリクス
- 外部バックリンク
- 参照ドメイン
- トラストフロー
- 引用の流れ
- 参照元IP
- 参照するサブネット
- インデックスされたURL
- 外部バックリンク EDU
- 外部バックリンク GOV
- 参照元ドメイン EDU
- 参照元ドメイン GOV
- トラスト・フロー トピックス
- アンカーテキスト
各メトリクスの定義については、Majesticの記事をご覧ください。
Ahrefs メトリクス
- バックリンク
- リフドメイン
- URLの評価
- RefPages
- ページ
- テキスト
- 画像
- サイト全体
- 非サイトワイド
- NoFollow
- DoFollow
- リダイレクト
- カノニカル
- ゴブ
- エデュ
- HTMLページ
- 内部リンク
- 外部リンク
- Ref クラスC
- リフィプス
- リンクされたルートドメイン
- ツイッター
- ピンタレスト
- ジープラス
- フェイスブック
- Facebookの「いいね!」数
- Facebookのシェア
- Facebookコメント
- Facebookクリック数
- Facebookコメント欄
- 株式総数
- 中位株
- キーワード
- キーワード トップ3
- キーワードトップ10
- トラフィック
- トラフィックトップ3
- トラフィックトップ10
- 価値
- バリュートップ3
- バリュートップ10
各メトリクスの定義については、Ahrefsの記事をご覧ください。
Moz Metrics
- ページ権限
- MozRank
- MozRank 外部資本
- MozRankの組み合わせ
- モズトラスト
- 最後にクロールされた時間(グリニッジ標準時)
- 総リンク数(内部または外部)
- エクイティパスの外部リンク
- 総資本-通過リンク(内部または外部)
- サブドメインリンク
- 総リンク元ドメイン数
- 外部リンクの合計
- スパムスコア
- サブドメインへのリンク
- サブドメインにリンクしているルートドメイン
- サブドメインへの外部リンク
- ドメインオーソリティ
- ルート・ドメイン・リンク
- Cブロックのリンク
- ルートドメインへのリンク
- ルートドメインへの外部リンク
各メトリクスの定義については、Mozからお読みいただけます。
Change Detection(変化検出)
変更検出] タブには、現在と過去のクロールの変更に関するデータとフィルターが含まれています。
比較」モードでは、「Config > Compare」(または上部の「cog」アイコン)で比較構成をクリックし、変化を特定したい要素や指標を選択します。
クロール比較が実行されると、マスタービューと概要タブに「変更検出」タブが表示され、検出された変更の詳細とともに選択された要素およびメトリックのフィルターが表示されます。
カラム
クロール完了後、このタブには、現在のクロールと過去のクロールについて、以下のカラムが表示されます。
- Address(アドレス) : URLのアドレスです
- Indexability : URLがインデックス可能か、インデックス不可能か
- Title 1 : ページに発見された(最初の)ページタイトル
- Meta Description 1 : ページ上の(最初の)メタディスクリプション
- h1 – 1 : ページ上の最初のh1(見出し)です。
- Word Count(単語数) : HTMLマークアップを除く、bodyタグ内のすべての「単語」です。カウントは、「設定>コンテンツ>エリア」で調整可能なコンテンツエリアに基づいて行われます。デフォルトでは、ナビとフッターの要素は除外されています。HTML要素、クラス、IDを含めたり除外したりすることで、精緻なワードカウントを計算することができます。パーサーは無効な HTML に対して特定の修正を行うため、この計算を手動で実行した場合の数値とは異なる場合があります。また、レンダリングの設定も、どのようなHTMLを考慮するかに影響します。当社の単語の定義は、テキストをスペースで分割したものです。コンテンツの可視性(hidden に設定された div 内のテキストなど)は考慮されません。
- Crawl Depth(クロールの深さ) : 開始ページからのページの深さ(開始ページから「クリック」された数)。リダイレクトは、ページの深さの計算において、現在1レベルとしてカウントされていることに注意してください。クロールの深さ。
- Inlinks(内部リンク) : そのURLへの内部ハイパーリンクの数。「Internal inlinks」とは、クロール対象の同じドメインから所定の URL を指すアンカー要素内のリンクのことです。
- Unique Inlinks(固有の内部リンク) : そのURLへの「ユニークな」内部リンクの数。「Internal inlinks」とは、クロール対象の同じサブドメインから指定されたURLを指すアンカー要素内のリンクのことです。例えば、「ページA」が「ページB」に3回リンクしている場合、「ページB」に対するインリンクは3回、ユニークインリンクは1回とカウントされます。
- Outlinks : そのURLからの内部アウトリンクの数。「Internal outlinks」とは、与えられたURLから、クロールされている同じサブドメイン上の他のURLへのアンカー要素のリンクのことです。
- Unique Outlinks(固有の内部発リンク) : そのURLからの「ユニークな(固有の)」内部発リンクの数です。「Internal outlinks」とは、あるURLからアンカー要素で、クロールされている同じドメインの他のURLへのリンクのことです。例えば、「ページA」から同じドメイン上の「ページB」に3回内部リンクしている場合、「ページB」への内部発リンクが3回、固有の内部発リンクは1回とカウントされます。
- External Outlinks(外部発リンク) : そのURLからの外部アウトリンクの数。「External outlinks」とは、指定されたURLから別のドメインへのアンカー要素のリンクのことです。
- Unique External Outlinks(固有の外部発リンク) : そのURLからの「ユニークな(固有の)」外部発リンクの数です。「External outlinks」とは、あるURLから別のドメインへのアンカー要素でのリンクのことです。たとえば、「ページA」から別のドメインの「ページB」に3回リンクしている場合、「ページB」への外部発リンクは3回、固有の外部発リンクは1回とカウントされます。
- Unique Types(ユニークタイプ) : URLで発見されたitemtypesのユニークな数
フィルター
このタブには、以下のフィルター検索があります。
- Indexability(索引性) : 索引性が変化したページ(索引性または非索引性)
- Page Titles(ページタイトル) : ページタイトル要素が変更されたページ
- Meta Description(メタディスクリプション) : メタディスクリプションが変更されたページ
- H1 : h1が変更されたページ。
- Word Count(文字数) : 文字数が変更されたページ
- Crawl Depth(クロールの深さ) : クロールの深さが変更されたページ
- Inlinks(内部リンク) : 内部リンクが変更されたページ
- Unique Inlinks(固有の内部リンク) : 「ユニークな(固有の)」内部リンクが変更されたページ
- Internal Outlinks(内部発リンク) : 内部発リンクが変更されたページ
- Unique Internal Outlinks(固有の内部発リンク) : 「ユニークな(固有の)」内部発リンクが変更されたページ
- 外部アウトリンク : 外部アウトリンクが変更されたページ
- Unique External Outlinks(固有の外部発リンク) :「ユニークな(固有の)」外部発リンクが変更されたページ
- Structured Data Unique Types(構造化データタイプの変更) : 発見された構造化データitemtypesのユニークな数が変更されたページ
- Content(コンテンツ) : コンテンツが10%以上変更されたページ(または「Config > Compare(設定 > 比較)」で設定された類似性の変更)。
変更検出の詳細については、チュートリアルの「クロールを比較する方法」をお読みください。
URLの詳細
トップウィンドウでURLをハイライトすると、このボトムウィンドウのタブがポップアップ表示されます。これには、該当するURLの概要が含まれています。これは、上部ウィンドウ内部タブで報告された列から、以下のようなデータを選択したものです。
- URL : クロールされたURL
- Status Code(ステータスコード) : HTTPレスポンスコード
- Status : HTTPヘッダーレスポンス
- Content(コンテンツ) : URLのコンテンツタイプ
- Size(サイズ) : ファイルまたはWebページのサイズ
- Crawl Depth(クロールの深さ) : ホームページまたは開始ページからのページの深さ(開始ページからの「クリック」数)
- Inlinks(内部リンク) : URLへの内部リンクの数
- Outlinks(内部発リンク) : URLからの内部発リンクの数
Inlinks(内部リンク)
トップウィンドウでURLをハイライトすると、このボトムウィンドウのタブがポップアップ表示されます。これには、そのURLを指す内部リンクのリストが含まれています。
- Type(タイプ) : クロールされるURLのタイプ(ハイパーリンク、JavaScript、CSS、画像など)
- From(参照元ページ) : 参照元ページのURL
- To(対象URL) : メインウィンドウで選択されている現在のURL
- Anchor Text(アンカーテキスト) : 使用されているアンカーまたはリンクテキスト(ある場合)
- Alt Text(Alt テキスト) : 使用されるalt属性(ある場合)
- Follow : 「True」は、リンクがFollowされていることを意味します。「False」は、リンクに「nofollow」、「UGC」または「sponsored」属性が含まれていることを意味します。
- Target(ターゲット) : 関連するターゲット属性(_blank、_self、_parent など)
- Rel : 関連するリンク属性(「nofollow」、「sponsored」、「ugc」に限定)。
- Path Type(リンクタイプ) : リンクの href 属性は、絶対リンクか、プロトコル相対リンクか、ルート相対リンクか、パス相対リンクかを指定
- Link Path(リンクパス) : ページ内のリンク位置の詳細を示すXPath
- Link Position(リンク位置) : コード内のどこにリンクがあるか(ヘッド、ナビ、フッターなど)、カスタムリンク位置の設定でカスタマイズできます
Outlinks(発リンク)
トップウィンドウでURLをハイライトすると、このボトムウィンドウのタブがポップアップ表示されます。これには、指し示すURLの内部リンクと外部リンクのリストが含まれています。
- Type(タイプ: クロールされるURLのタイプ(ハイパーリンク、JavaScript、CSS、画像など)
- From(参照元ページ) :参照元ページのURL
- To(対象URL) :メインウィンドウで選択されている現在のURL
- Anchor Text(アンカーテキスト) : 使用されているアンカーまたはリンクテキスト(ある場合)
- Alt Text(Alt テキスト) : 使用されるalt属性(ある場合)
- Follow : 「True」は、リンクがフォローされていることを意味します。False」は、リンクに「nofollow」、「UGC」または「sponsored」属性が含まれていることを意味します。
- Target(ターゲット) : 関連するターゲット属性(_blank、_self、_parent など)
- Rel : 関連するリンク属性(「nofollow」、「sponsored」、「ugc」に限定)
- Path Type(リンクタイプ) : リンクの href 属性は、絶対リンクか、プロトコル相対リンクか、ルート相対リンクか、パス相対リンクかを指定
- Link Path(リンクパス): ページ内のリンク位置の詳細を示すXPath
- Link Position(リンク位置): コード内のどこにリンクがあるか(ヘッド、ナビ、フッターなど)、カスタムリンク位置の設定でカスタマイズできます
Image details(画像詳細)
上のウィンドウでページのURLをハイライトすると、下のウィンドウのタブに、そのページで見つかった画像のリストが表示されます。
上のウィンドウで画像のURLをハイライトすると、下のウィンドウのタブに画像のプレビューと次の画像の詳細が表示されます。
- From : トップウィンドウで選択されたURLです。
- To : URLにある画像リンク。
- Alt Text : 使用されるalt属性(ある場合)。
Duplicate Details(重複の詳細)
トップウィンドウでURLをハイライトすると、この下のウィンドウタブがポップアップ表示されます。このタブには、該当するURLの完全な重複とそれに近い重複の詳細が含まれています。
重複に近い場合は、クロール前にこの機能を有効にし、クロール後に分析を実行する必要があります。
重複しているURLを特定し、その類似性を表示します。

また、「重複の詳細」タブで「重複に近いアドレス」をクリックすると、ページ間で発見された重複に近い内容が表示され、相違点が強調表示されます。
Resources(リソース)
トップウィンドウで URL をハイライトすると、このボトムウィンドウのタブがポップアップします。このタブには、そのURLで見つかったリソースのリストが表示されます。
- Type(タイプ: リソースのタイプ(JavaScript、CSS、画像など)
- From(参照元ページ) :メインウィンドウで選択されている現在のURL
- To(対象URL) :上記「From」ページのURLにあるリソースリンク
- Anchor Text(アンカーテキスト) : 使用されているアンカーまたはリンクテキスト(ある場合)
- Alt Text(Alt テキスト) : 使用されるalt属性(ある場合)
- Follow : 「True」は、リンクがフォローされていることを意味します。False」は、リンクに「nofollow」、「UGC」または「sponsored」属性が含まれていることを意味します。
- Target(ターゲット) : 関連するターゲット属性(_blank、_self、_parent など)
- Rel : 関連するリンク属性(「nofollow」、「sponsored」、「ugc」に限定)
- Path Type(リンクタイプ) : リンクの href 属性は、絶対リンクか、プロトコル相対リンクか、ルート相対リンクか、パス相対リンクかを指定
- Link Path(リンクパス): ページ内のリンク位置の詳細を示すXPath
- Link Position(リンク位置): コード内のどこにリンクがあるか(ヘッド、ナビ、フッターなど)、カスタムリンク位置の設定でカスタマイズできます
SERP snippet(SERPスニペット)
上のウィンドウでURLをハイライトすると、この下のウィンドウのタブがポップアップ表示されます。
SERPスニペット」タブでは、Googleの検索結果でURLがどのように表示されるかを確認できます。切り捨てポイント(Googleが省略記号(…)を表示し、単語を切り捨てる場所)は、文字数ではなく、ピクセル幅に基づいて計算されます。SEO Spiderは最新のピクセル幅のカットオフポイントを使用し、ページタイトルやメタディスクリプションに使用されているピクセル数を1文字ごとにカウントし、より精度の高いSERPスニペットをエミュレートして表示します。
現在の制限値は、ページタイトルとメタディスクリプションのタブとフィルターの下にある「Xピクセル以上」と、その下の「利用可能」ピクセル欄に表示されます。
Googleは定期的にSERPを変更しており、私たちは以前のブログ記事、こちらと こちらでその変更点を取り上げています。
Googleはピクセル幅や文字数の推奨値を提供していないため、SEO SpiderのSERPスニペットエミュレータはSERPsでの調査に基づいています。Googleはスコアリングで表示されるよりも多くの文字を使用することがありますが、ユーザーにとって目に見えるSERPに重要な情報を含めることが重要です。
SEO SpiderのSERPスニペットエミュレーターのデフォルトはデスクトップで、モバイルとタブレットの両方でピクセル幅の切り捨てポイントが異なります。「Config > Spider > Preferences(設定 > Spider > 設定)」のMax Description Preferences」をモバイルまたはタブレットの長さに更新することができます。SERPスニペットエミュレータで「デバイス」タイプを切り替えると、デスクトップとモバイルの現在の推定ピクセル長との違いを表示できます。
SERPスニペットの編集
ページタイトルや説明文を直接編集して、SERPスニペットがGoogleでどのように表示されるかを確認することができます。
SEOスパイダーはデフォルトで、’タイトルと説明をリセット’ボタンをクリックしない限り、ページタイトルと説明に加えた編集を記憶します。これにより、エミュレーターで好きなだけ変更を加え、SERPスニペットを完成させ、エクスポート(Reports > SERP Summary)してクライアントや開発チームに送り、本番サイトで変更を加えてもらうことが可能です。
Rendered page(レンダリングページ)
SEO Spiderがクロールしたレンダリングページは、JavaScriptレンダリングモードでクロールしたときに表示される「レンダリングページ」タブで確認することができます。これは、トップウィンドウでURLを選択したときに、下のウィンドウペインにのみ表示されます。
この機能は、JavaScriptレンダリング機能を使用する場合、初期設定で有効になり、設定されたユーザーエージェント、AJAXタイムアウト、ビューポートサイズと連動します。
左下のウィンドウでは、レンダリングされたページの「ブロックされたリソース」も見ることができます。デフォルトでは「ブロックされたリソース」に設定されていますが、ページで使用されている「すべてのリソース」を表示するように変更することも可能です。
レンダリングされたスクリーンショットは、下記に保存されます。
C:\Users\User Name\.ScreamingFrogSEOSpider\screenshots-XXXXXXXXXXXXXXXJavaScriptレンダリングモードを使用している場合は、「JavaScriptのウェブサイトをクロールする方法」のガイドを参照してください。
View Source(ビューソース)
Stored HTML & Rendered HTMLは、「Store HTML」または「Store Rendered HTML」を有効にしてクローリングすると、ここに表示されます。上のウィンドウでURLを選択した場合、下のウィンドウペインにのみ表示されます。
HTMLを保存するには、「Configuration > Spider > Extraction > Store HTML / Store Rendered HTML(設定 > Spider > 抽出 > HTMLを保存 / レンダリングしたHTMLを保存)」をクリックします。レンダリングされたHTMLを保存するには、JavaScriptレンダリングモードでクロールする必要があります。

オリジナルのHTMLは左側に、レンダリングされたHTML(有効になっている場合)は右側に表示されます。どちらのフィールドにも検索フィールドがあり、エクスポート可能です。
詳細はこちらでご確認ください。
HTTP Headers(HTTPヘッダー)
HTTPヘッダーを抽出するように設定されている場合、ハイライトされたURLのHTTPレスポンスおよびリクエストヘッダをすべて表示することができます。これは、上のウィンドウでURLを選択したときに、下のウィンドウペインにのみ表示されます。
HTTPヘッダーの抽出を有効にするには、「Configuration > Spider > Extraction > HTTP Headers(設定 > Spider > 抽出 > HTTPヘッダー)」をクリックします。
タブの左側には、HTTPリクエストヘッダが表示されます。タブの右側には、HTTPレスポンスヘッダが表示されます。この右側のウィンドウに表示される列は以下の通りです。
- Header Name : サーバーからの応答ヘッダーの名前
- Header Value : サーバーからの応答ヘッダーの値
抽出されたHTTPヘッダーは、Internalタブのユニークなカラムに追加され、クロールデータと一緒にクエリすることができます。
また、「Bulk Export > Web > All HTTP Headers(一括エクスポート > ウェブ > すべてのHTTPヘッダー)」または「Reports > HTTP Headers > HTTP Header Summary(レポート > HTTPヘッダー > HTTPヘッダーサマリー)」で一括してエクスポートすることができます。
Cookies(クッキー)
Cookieを抽出する設定になっていれば、ハイライトされたURLをクロールした際に見つかったCookieを表示することができます。上部のウィンドウで単一または複数のURLを選択し、下部のウィンドウペインに表示することができます。
Cookieの抽出を有効にするには、「Configuration > Spider > Extraction > Cookies(設定 > Spider > 抽出 > Cookie)」をクリックします。JavaScriptやピクセル画像タグを使ってページに読み込まれたCookieを正確に表示するには、JavaScriptレンダリングモードを使用する必要があります。
Cookiesタブに記載されている列は以下の通りです。
- Cookie Typ(クッキータイプ) : クッキーが発見された場所。HTTP’上か、’On-Page’上か : JavaScriptやピクセルタグを経由した場合。
- Cookie Name : Cookieの名前
- Cookie Value : Cookieの値
- Domain : クッキーを発行したドメインで、ファーストパーティかサードパーティのどちらか
- Expiration Time : Cookieの有効期限
- Secure : クッキーのセキュア属性の詳細
- HttpOnly : クッキーのHttpOnly属性の詳細
- Address: クッキーが見つかったURL
Cookieは「Bulk Export > Web > All Cookies(一括エクスポート > Web > すべてのクッキー)」で一括エクスポートでき、「Reports > Cookies > Cookie Summary(レポート > クッキー > クッキー概要)」で集計レポートをエクスポートすることができます。
なお、Cookieの保存を選択した場合、発行されたすべてのCookieを正確に把握するために、SEO SpiderがGoogle Analyticsのトラッキングタグに対して行う自動排除は無効となります。
つまり、トラッキングスクリプトを除外する設定(Config > Exclude)をするか、PSIを除外するのと同様に’Screaming Frog SEO Spider’ ユーザーエージェントをフィルタリングしない限り、分析レポートに影響を与えるということです。
構造化データの詳細
構造化データを抽出するように設定されている場合、ハイライトされたURLの構造化データの詳細を表示することができます。これは、上のウィンドウでURLを選択したときに、下のウィンドウペインにのみ表示されます。

タブの左側には、エラーや警告のアイコンとともに、プロパティ値が表示されます。これらの値のいずれかをクリックすると、検証エラー/警告の詳細が右側のウィンドウに表示されます。この右側のウィンドウに表示される列には、以下のものがあります。
- Validation Type(バリデーションタイプ) : バリデーション問題を持つ構造化データフィールド(Article、Person、Productなど)
- Issue Severity(問題の深刻度) : 問題の値が推奨されるか、または検証を要求されるか
- Issue(課題) : 特定の課題に関する詳細
詳しくは、「構造化データのテストと検証方法ガイド」をご覧ください。
PageSpeed Details(表示速度の詳細)
これらの指標を取得するには、「Configuration > API Access > PageSpeed Insights(設定 > APIアクセス > PageSpeed Insights)」で、無料のPageSpeed APIキーを挿入し、接続し、クロールを実行するだけです。
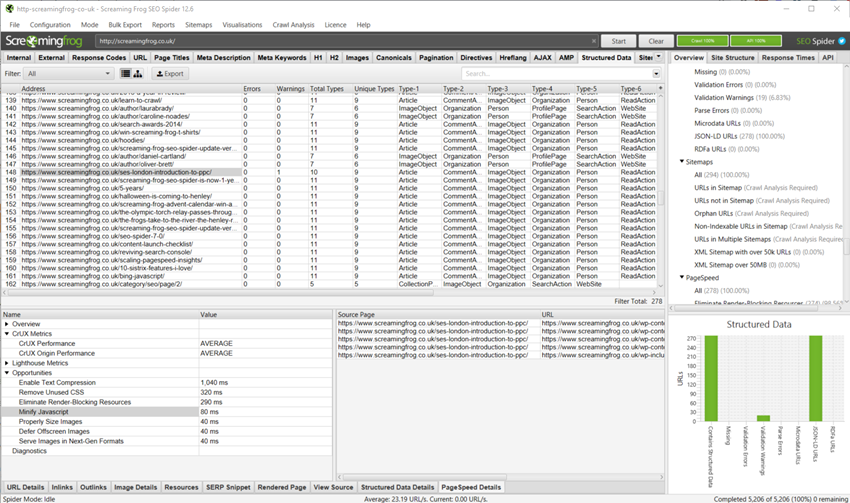
データがある場合、上のウィンドウでURLを選択すると、下のウィンドウのタブに詳細が表示されます。
左側のウィンドウには、抽出された指標と、ハイライトされたURLに固有の利用可能な機会の両方に関する具体的な情報が表示されます。機会をクリックすると、右側のウィンドウに詳細な情報が表示されます。これは、以下の列で構成されています。
- The Source Page(ソースページ) : トップウィンドウで選択されたURL
- URL : 機会が利用可能なリンク先リソース
- Size (Bytes) : リストされたリソースの現在のサイズです
- Potential Savings(潜在的に節約できる規模): 強調された機会を実施することによって節約される可能性のある規模
利用可能な速度指標の詳細と機会については、PageSpeed Insightsの統合ガイドを参照してください。
スペル・文法詳細
トップウィンドウでURLをハイライトすると、この下のウィンドウタブがポップアップ表示されます。このタブには、該当するURLのスペルや文法上の問題の詳細が含まれています。
このタブに入力する前に、スペルチェックおよび/または文法チェックが有効になっている必要があります。
下のウィンドウの「スペル・文法の詳細」タブには、エラーの種類(スペルまたは文法)、詳細、および問題を修正するための提案が表示されます。また、詳細タブの右側には、ページのテキストと識別されたエラーがビジュアルで表示されます。
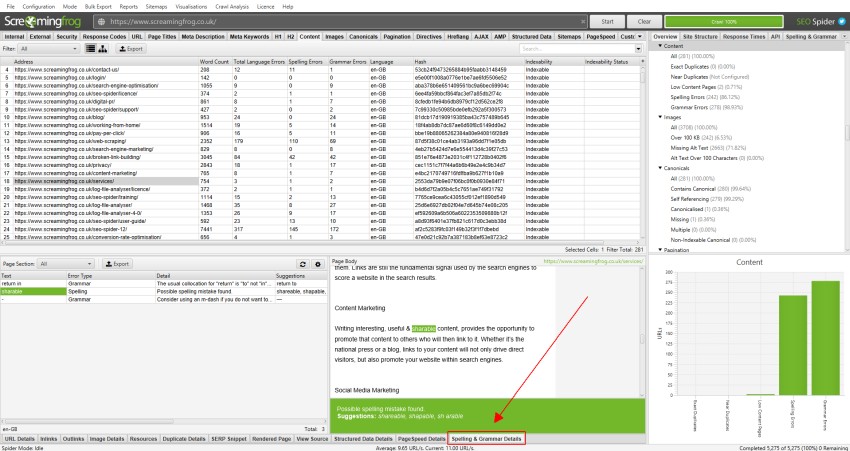
概要
概要タブは、リアルタイムに更新され、クロールのトップレベルのビューを提供します。URLデータの概要や各タブ、フィルタの集計が表示されます。
- Summary(概要) : クロールで遭遇したURLの概要
- SEO Elements(SEO要素) : 各トップレベルタブとそれぞれのフィルター内で見つかったURLの数の概要。このデータは、タブやフィルター内をクリックすることなく、問題を発見するために使用することができます。また、Spiderのメインウィンドウでタブやフィルターへのショートカットとして使用することもできます。
Issues(課題)
課題タブはリアルタイムに更新され、クロールで発見された潜在的な課題、警告、機会の詳細を提供します。このデータは、概要タブやフィルターから得られる既存のデータに基づいていますが、潜在的な「問題」のみを表示します。
データは課題の種類、優先度で分類され、アプリ内で課題の説明とヒントが表示されます。
- Issue Name(課題名) : タブとフィルターに基づいた課題名
- Issue Type(課題タイプ) : 「課題」、「機会」、「警告」のどれに該当するか
- Issue Priority(課題の優先順位) : 潜在的な影響に基づき「高」「中」「低」とし、さらに注意を払う必要がある場合もある。
- URLs : 問題のあるURLの数
- % of Total(問題のあるページ割合): 問題のあるURLの総数に対する割合

各課題には「タイプ」があり、潜在的な影響に基づく推定「優先度」が設定されています。
- 課題とは、理想的には修正されるべきエラーや問題です。
- 機械とは、最適化および改善のための「潜在的」な領域である。
- 警告は必ずしも問題ではないが、確認する必要があり、修正する可能性もある。
優先順位は、決定的なアクションではなく、より注意を払う必要がある潜在的な影響に基づいており、広く受け入れられているSEOのベストプラクティスに基づいています。また、SEO戦略において何を優先すべきか、SEO監査で何を修正すべきかという明確なルールではありません。
しかし、手動でデータをフィルタリングするよりも、より効率的に潜在的な問題を発見することができます。
「Directives:Noindex」は「警告」に分類されますが、URL が誤って noindex になった場合に大きな影響を与える可能性があるため、優先度は「高」に設定されます。
すべての課題は「一括エクスポート > 課題 > すべて」によって一括でエクスポートすることができます。これにより、発見された各issue(リンク切れなどのための「inlinks」バリアントを含む)がフォルダ内の個別のスプレッドシートとしてエクスポートされます(CSV、Excel、Sheetsとして)。

問題タブは、専門知識や、ビジネス、SEO、重要なことを優先するニュアンスのコンテキストを持つSEOの専門家に取って代わるものではないことを理解することが重要です。
課題」タブは、データの意味を理解し、各ウェブサイトやシナリオに関連する適切な優先アクションに解釈できるユーザーに指示を与えるためのガイドとして機能します。
課題」データの単純なエクスポートは、それ自体、専門家の指導と何が本当に重要かの優先順位付けがなければ、私たちが推奨する「SEO監査」とは言えません。
Site Structure(サイト構造)
サイト構造タブはリアルタイムに更新され、ウェブサイトのディレクトリツリーを集約したビューを提供します。これにより、サイト構造を視覚化し、異なるパスのインデックス性など、どこに問題があるのかを一目で確認することができます。
トップテーブルはリアルタイムに更新され、ウェブサイトの各パス、URLの総数、インデックス可能なURL、インデックス不可能なURLが表示されます。
- Path : クロールされたウェブサイトのURLパス
- URLs : パス内で見つかった一意の子URLの合計数
- Indexable : パス内で見つかった、ユニークな Indexable 子 URL の総数
- Non-Indexable : パス内で見つかった一意のNon-Indexableの子URLの総数
集約されたサイト構造の「表示」を調整し、各パスのURLの「インデックス可能性ステータス」「レスポンスコード」「クロールの深さ」も確認することが可能です。
下の表とグラフは、クロール深度が1~10+のURLの数を、レスポンスコードに基づいたバケットで表示したものです。
- 深さ (開始URLからのクリック数) : ホームページまたは開始ページからの深さ (開始ページからの「クリック数」).
- URL数 : クロールで遭遇した、特定の深さを持つURLの数。
- % of Total : クロールされたURLのうち、特定の深度を持つURLの割合。
すべてのURLの「Crawl Depth」データは、「Internal」タブの「Crawl Depth」カラムから検索してエクスポートすることができます。
応答時間
応答時間タブはリアルタイムに更新され、クロール中のURLの応答時間をトップレベルで見ることができます。
- Response Times(応答時間) : URLをダウンロードするのにかかる時間の範囲(秒)。
- Number of URLs(URLの数) : 特定の応答時間の範囲内でクロールに遭遇したURLの数。
- % of Total : 特定の応答時間の範囲にあるクロールのURLのパーセンテージです。
レスポンスタイムは、HTTPリクエストを発行して、サーバーから完全なHTTPレスポンスが返ってくるまでの時間から計算されます。SEO Spiderのインターフェースに表示される数値は秒単位です。この数値は、リクエストが行われた時のサーバーの負荷やクライアントのネットワークアクティビティに大きく依存するため、100%再現できるわけではありませんのでご注意ください。
この図には、JavaScriptレンダリングモードでの追加リソースのダウンロードにかかる時間は含まれていません。各リソースは、ユーザーインターフェースに個別に表示され、それぞれ個別のレスポンスタイムが発生します。
PageSpeedの徹底的な解析には、PageSpeed InsightsのAPI統合をお勧めします。
API
すべてのAPIからのデータ収集の進捗を、エラー数とともに個別に表示します。
APIは、このタブの’Cog’アイコンから接続することができます。また、’Config > API Access’からもAPIに接続でき、APIインテグレーションを選択することができます。
各インテグレーションについての詳細は、ユーザーガイドの以下のリンクからご覧ください。
言語&文法
右側のペイン「スペル&グラマー」タブには、発見された上位100のユニークなエラーと、それが影響するURLの数が表示されます。これは、テンプレート間でエラーを見つけたり、辞書や無視リストを作成するのに便利です。右クリックして、「文法規則を無視する」、「すべてを無視する」、「辞書に追加する」のいずれかを選択することができます。
